
新智元报道
编辑:Aeneas 好困
OpenAI 又憋大招了!据悉,下一代旗舰模型 GPT-5 或名为「猎户座」,由「草莓」合成的数据训练。而草莓具有极强的复杂推理(数学、编程)和语言能力,或将超越当前的任何模型的推理和生成的能力。
OpenAI 的下一代旗舰大语言模型,要来了?
据悉,新模型代号 Orion(猎户座),就是能超越 GPT-4 的下一代模型。
而猎户座的预训练数据,正是由草莓模型生成的。
而草莓模型驱动的聊天机器人,很可能就会在今年秋天上线!
关于 OpenAI 的草莓,外媒 The Information 最近又挖到了新的细节。

根据 The Information 的信息,网友推测:「GPT-4+ 草莓」会在秋季推出,之后上线的继任者「猎户座」可能就是 GPT-5。


由于大概率要避开 11 月,因此,猎户座的发布时间要么在之前要么是在 12 月。
甚至,AI 大V、Hallid.ai 联创「indigo」提出了一个大胆的猜测:猎户座或许不是 GPT-5,而是 GPT-6。

AI 大V「Chubby」表示附议。
最后,Chubby 激动地表示:所有人都觉得 AI 的发展正在放缓?并不是。在大公司,厨房里的东西正在沸腾!

网友们纷纷表示:「我们正在见证一种超越我们自己思想的诞生」。

打开Q*之门,一切模型凭此迭代。


有人担心,如果 GPT-5 控制整个互联网,人类会从此迷失。
所以,猎户座到底是 GPT-5 还是 GPT-6 呢?网友们各持己见。
但有人猜测,我们目前还没有足够的算力来达到 GPT-5,更不用说 GPT-6 了。

透个底,让美国政府安心

今年夏天,Sam Altman 的团队已经向美国国家安全官员展示了这项技术。
在安全问题日益敏感的情况下,OpenAI 的做法也算给大家打了个样。
如果政府官员觉得这项 AI 不安全怎么办?那就给他们展示一下。
这次演示,就是 OpenAI 让政策制定者觉得更透明的努力的一部分。毕竟,如果他们感觉到受到这项技术的威胁了,很可能就会给公司带来麻烦。
现在,OpenAI 的安全团队已经出走,愤怒的前员工在网上大肆爆料,这种时候,对政府官员更加透明的做法,就显得尤为重要。
The Information 表示,这次演示还可能另有目的:跟政府队员就如何保护技术进行对话,以防止美国的 AI 技术被他国窃取。
说不定,还可以借此机会攻击 Meta 一波,因为他们的 AI 是开放权重的,其他国家想要获取,是非常容易的事。
总之,未来几年内,AI 开发者应该会经常出现在旧金山和华盛顿之间的航线上了,因为他们时不时就需要跟政府官员来往一下。

草莓:数学提升,能解字谜
一个月前路透社曾报道,OpenAI 内部测试了一种 AI,在 MATH 基准上得分超过了 90%。
据猜测,这个模型很可能就是草莓。
如今的传言是,今年秋天 OpenAI 研究者会推出代号为草莓的新 AI(也就是之前的Q*),或许会聊天到 ChatGPT 之类的聊天机器人中。
它能做到目前的聊天机器人无法做到的很多事情,比如解决未曾遇到的数学问题,还能解决编程难题。

在获得额外「思考」时间后,草莓模型还可以回答更主观的问题,比如产品的营销策略。
据悉,在语言任务上,草莓表现出了强大的能力。比如 OpenAI 的一位员工曾向同事演示了草莓成功解决《纽约时报》的 Connections——复杂的文字谜题。
OpenAI 在 LLM 和会话 AI 领域的领先地位,一直在遭受冲击,因此 OpenAI 只能对外不时放出点草莓的消息,提升一下自己的存在感。
另外,据说草莓的技术已经显示出了智能体的能力。
草莓模型似乎能够自主浏览网络,像人类研究人员一样,独立上网、进行深度研究。
它不仅能生成答案,还能规划、执行一系列复杂任务,还能收集信息。
与之类似的,还有斯坦福的 Quiet-STaR。
就像人类会在说话或写作前会停下来思考自己的想法一样,Quiet-STaR 可以训练 LLM 去生成在复杂推理问题中采取步骤的内部「思考」,从而做出更好的决策。

论文地址:https://arxiv.org/abs/2403.09629
眼下,OpenAI 的业务正以惊人的速度增长:跟去年相比,今年它向企业销售 LLM 和 ChatGPT 订阅的收入大约增加了三倍,达到了每月 2.83 亿美元,尽管公司每月的亏损可能高于此。
目前,OpenAI 的私人估值为 860 亿美元。
Sam Altman 还希望为公司筹集更多资金,找到减少损失的方法。
自 2019 年以来,OpenAI 已经从微软筹集了约 130 亿美元,与这家企业软件巨头的协议,会持续到 2030 年。
合作条款可能会发生变化,包括 OpenAI 向微软支付租用云服务器以开发 AI 的方式。
云服务器,是 OpenAI 最大的成本。
OpenAI 的新希望:Orion(猎户座)
但说到底,OpenAI 的前景终究还是依赖正在开发的新旗舰——Orion。
有人能解释一下为什么 OpenAI、谷歌和亚马逊一直用希腊神话来命名他们的模型吗?
去年初推出后,GPT-4 已经被各家赶超得差不多了,现在 GPT-4 级的模型,可以说是各家人手一个。
有人猜,OpenAI 可能会推出一个比原始草莓模型更小、更简化的模型,也就是蒸馏版。
这个版本被寄望于提升 GPT-4 和 ChatGPT 性能,目的是保持和更大模型相同的性能水平,而且更易于操作,成本更低。
另外,还有知情人士透露,OpenAI 还在用更大的草莓版本,为 Orion 的训练生成数据。
这种人工合成数据,意味着草莓能帮助 OpenAI 克服获取高质量数据的限制,从而可以从现实世界数据(比如从互联网获取的文本或图像)中训练新模型。

研究人员表示,使用草莓可以帮助 Orion 减少幻觉的产生。
这是因为,AI 模型是从训练数据中学习的,所以它们看到的复杂推理的正确示例越多,就越好。
对此,智能体初创公司 Minion AI 的 CEO 兼 GitHub Copilot 前首席架构师 Alex Graveley 给予了高度厚望。
「想象一个没有幻觉的模型,一个你问它逻辑难题、它第一次就答对了的模型。」
「训练数据中存在较少的歧义,因此它的猜测更少。」
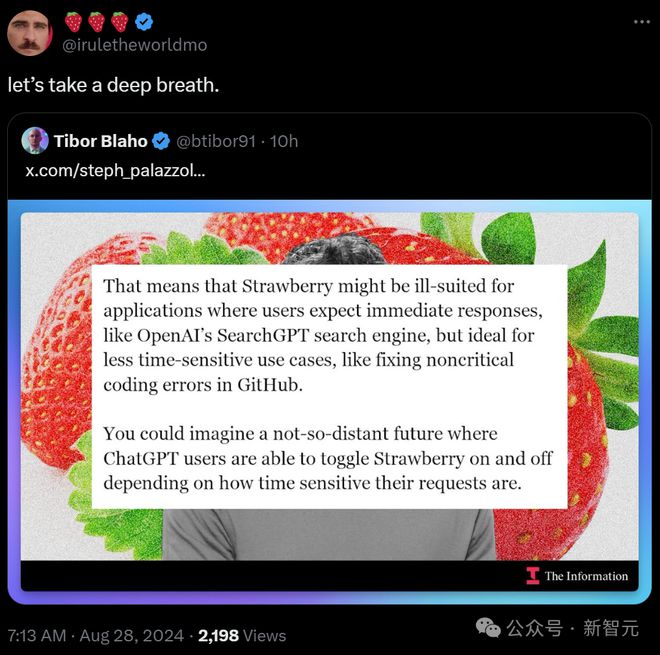
The Information 猜测,草莓改进的推理能力,可能会整合到 ChatGPT 中。这些答案可能会更准确,但也可能更慢。
因此,草莓可能并不适合需要即时即时响应的应用。而在 GitHub 中修复非关键编码错误,则是理想的选择。
或许,以后的 ChatGPT 用户,可以根据请求的时间敏感性来切换草莓模型。
Sam Altman 在五月的一次活动中曾表示:「我们感觉,为下一个模型准备的数据已经足够」。
这个模型,很可能指的是就 Orion。Altman 表示:「我们进行了各种实验,包括生成合成数据。」
解决复杂数学问题:有前景的应用
如果说目前 AI 最有前景的应用,那解决复杂数学问题,必然是其中一个了。
毕竟,现有的 AI 在数学密集的领域如航空航天和结构工程中,表现实在不佳。
各种 LLM 在回答数学问题时,往往会给出各种让人啼笑皆非的答案。
而且,数学推理能力的提升还能帮助 AI 模型更好地推理会话查询,比如用户的服务请求。
谷歌和一些初创公司,也在这方面发力。
上个月,谷歌 DeepMind 开发的 AI,已经能在国际数学奥林匹克竞赛中击败大多数人类参赛者。

OpenAI 的另一大竞争对手 Anthropic 祭出的最新模型,也能编写更复杂的软件代码,还能回答有关图表和图形的问题,这些都要归功于它推理能力的改进。

还有一些初创公司为了提高模型的推理能力,采用了一种廉价的技巧,将问题分解为更小的步骤,尽管这些方法速度慢且成本高昂。
无论 Strawberry 是否会作为产品推出,人们对 Orion 的期望都不会低了,因为 OpenAI 会力求继续保持领先地位,同时还要保证显著的的收入增长。
OpenAI 的领先者优势,已经不明显了。
虽然在 5 月宣布了「Her」的版本,但谷歌却抢先推出了 AI 驱动的语音助手,后者也足够灵活,还能处理用户的打断,和突然变化的话题。
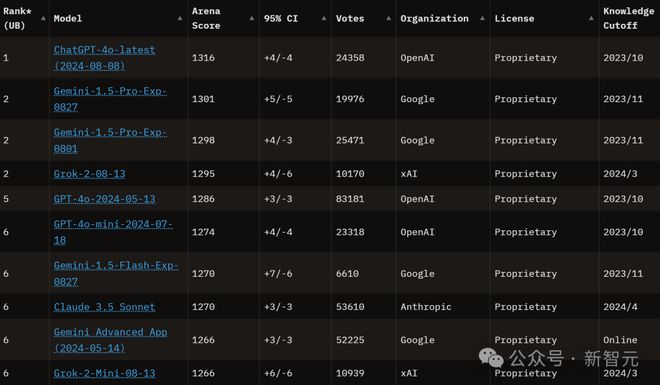
而 Lmsys Chatbot Arena 等大模型排行榜上,谷歌、xAI、Anthropic 和 Meta 的模型也都在赶上 OpenAI 的步伐。
Ilya 看到了什么?
值得一提的是,「草莓之父」,其实就是已经离职了的 OpenAI 的首席科学家 Ilya Sutskever。
几年前,Ilya 启动了一个项目,在研究过程中,诞生了草莓。

而在 Ilya 离职之前,OpenAI 的研究人员 Jakub Pachocki 和 Szymon Sidor,就已经在 Ilya 的工作基础上开发了一个新的数学求解模型Q*,这让不少关注 AI 安全的研究人员感到担忧。
另外,在去年Q*的前期准备中,OpenAI 研究人员开发了一种被称为「测试时计算」的概念变体,目的是提升 LLM 的问题解决能力。
这样,LLM 就会花更多时间考虑被要求执行的命令,或问题的各个部分。
当时,Ilya 发表了一篇与这项工作相关的博客。

博客地址:https://openai.com/index/improving-mathematical-reasoning-with-process-supervision/
在博客中,模型解决了数个有难度的数学问题。
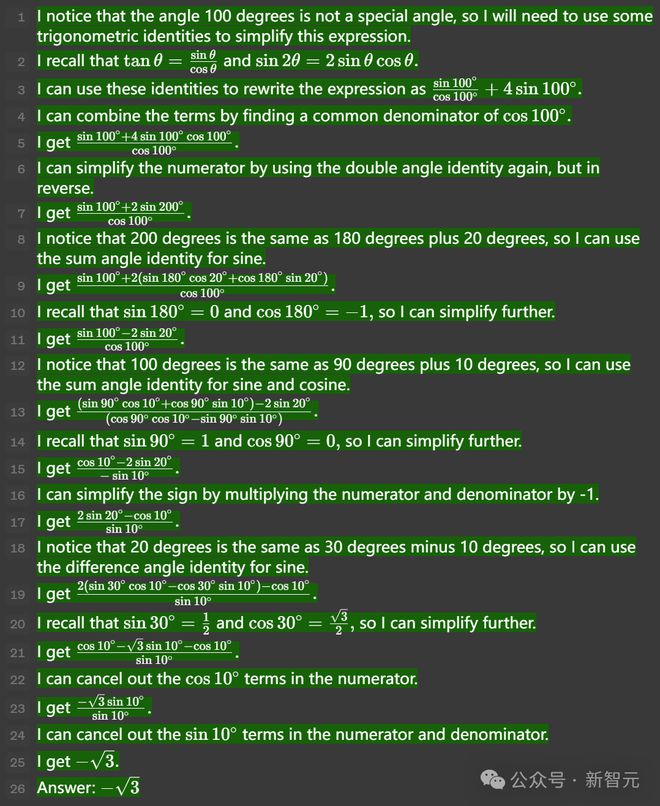
比如在这道有挑战性的三角函数题中,需要连续应用几个并不明显的等式。

在这道题,GPT-4 成功执行了一系列复杂的多项式分解。

步骤 5 中使用的 Sophie-Germain 恒等式是重要的一步,可以被认为极有洞察力。

在这道题的步骤 7 和 8 中,GPT-4 开始执行猜测和检查。

这也是模型可能产生幻觉的常见情况,LLM 会声称某个特定的猜测是成功的,但实际上并不成功。
在这种情况下,奖励模型会验证每个步骤,并确定思路是否正确。

在最后这道题中,模型成功地应用了多个三角恒等式,来简化了表达式。
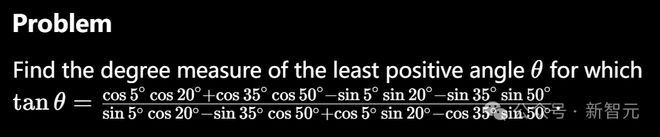

或许,我们能从中窥见草莓和 Orion 的端倪。
参考资料:






