西风发自凹非寺
量子位公众号 QbitAI
不必增加模型参数,计算资源相同,小模型性能超过比它大 14 倍的模型!
谷歌 DeepMind 最新研究引发热议,甚至有人表示这可能就是 OpenAI 即将发布的新模型草莓所用的方法。

研究团队探究了在大模型推理时进行计算优化的方法,根据给定的 prompt 难度,动态地分配测试时(Test-Time)的计算资源。
结果发现这种方法在一些情况下比单纯扩展模型参数更经济有效。

换句话说,在预训练阶段花费更少的计算资源,而在推理阶段花费更多,这种策略可能更好。

推理时用额外计算来改进输出
这项研究的核心问题是——
在一定计算预算内解决 prompt 问题,不同的计算策略对于不同问题的有效性有显著差异。我们应如何评估并选择最适合当前问题的测试时计算策略?这种策略与仅仅使用一个更大的预训练模型相比,效果如何?

DeepMind 研究团队探究了两种主要机制来扩展测试时的计算。
一种是针对基于过程的密集验证器奖励模型(PRM)进行搜索。
PRM 可以在模型生成答案过程中的每个步骤都提供评分,用于引导搜索算法,动态调整搜索策略,通过在生成过程中识别错误或低效的路径,帮助避免在这些路径上浪费计算资源。
另一种方法是在测试时根据 prompt 自适应地更新模型的响应分布。
模型不是一次性生成最终答案,而是逐步修改和改进它之前生成的答案,按顺序进行修订。
以下是并行采样与顺序修订的比较。并行采样独立生成N个答案,而顺序修订则是每个答案依赖于前一次生成的结果,逐步修订。
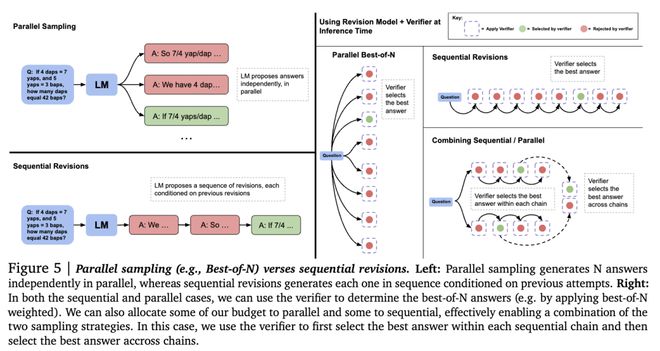
通过对这两种策略的研究,团队发现不同方法的有效性高度依赖于 prompt 的难度。

由此,团队提出了“计算最优”扩展策略,根据 prompt 难度自适应地分配测试时的计算资源。
他们将问题分为五个难度等级并为每个等级选择最佳策略。
如下图左侧,可以看到,在修订场景中,标准的 best-of-N 方法(生成多个答案后,从中选出最优的一个)与计算最优扩展相比,它们之间的差距逐渐扩大,使得计算最优扩展在使用少 4 倍的测试计算资源的情况下,能够超越 best-of-N 方法。
同样在 PRM 搜索环境中,计算最优扩展在初期相比 best-of-N 有显著的提升,甚至在一些情况下,以少 4 倍的计算资源接近或超过 best-of-N 的表现。
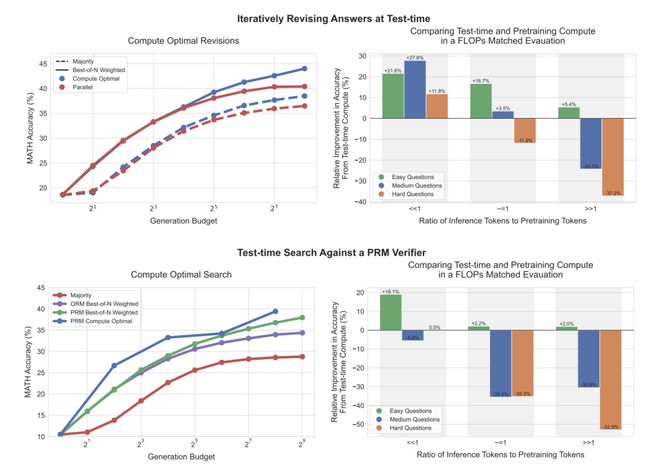
上图右侧比较了在测试阶段进行计算最优扩展的 PaLM 2-S 模型与不使用额外测试计算的预训练模型之间的表现,后者是一个*大 14 倍的预训练模型。
研究人员考虑了在两种模型中都预期会有 tokens 的预训练和 tokens 的推理。可以看到,在修订场景中(右上),当 << 时,测试阶段的计算通常优于额外的预训练。
然而,随着推理与预训练 token 比率的增加,在简单问题上测试阶段计算仍然是首选。而在较难的问题上,预训练在这些情况下更为优越,研究人员在 PRM 搜索场景中也观察到了类似的趋势。
研究还比较了测试时计算与增加预训练的效果,在计算量匹配的情况下,对简单和中等难度的问题,额外的测试时计算通常优于增加预训练。
而对于难度较大的问题,增加预训练计算更为有效。

总的来说,研究揭示了当前的测试时计算扩展方法可能无法完全替代预训练的扩展,但已显示出在某些情况下的优势。
引发网友热议
这项研究被网友 po 出来后,引发热议。
有网友甚至表示这解释了 OpenAI“草莓”模型的推理方法。
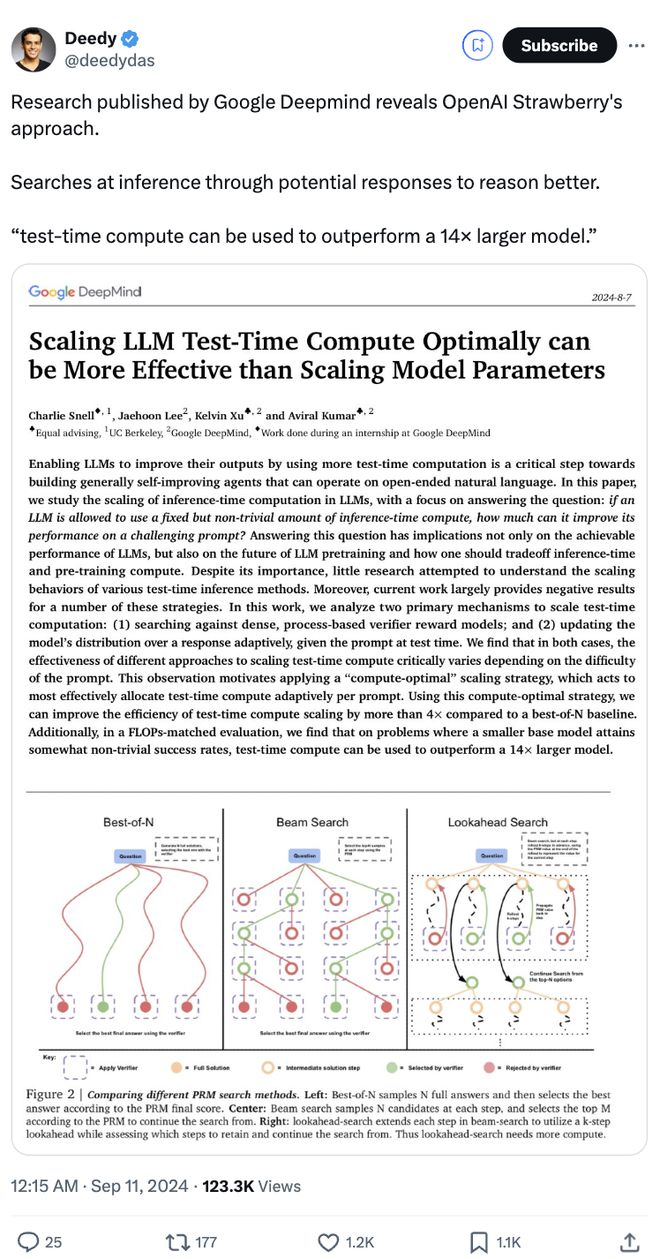
为什么这么说?
原来就在昨晚半夜,外媒 The Information 放出消息,爆料 OpenAI 新模型草莓计划未来两周内发布,推理能力大幅提高,用户输入无需额外的提示词。
草莓没有一味追求 Scaling Law,与其它模型的最大区别就是会在回答前进行“思考”。
所以草莓响应需要10-20 秒。

这位网友猜测,草莓可能就是用了类似谷歌 DeepMind 这项研究的方法(doge):
如果你不认同,给个替代推理方法解释!

解释就解释:
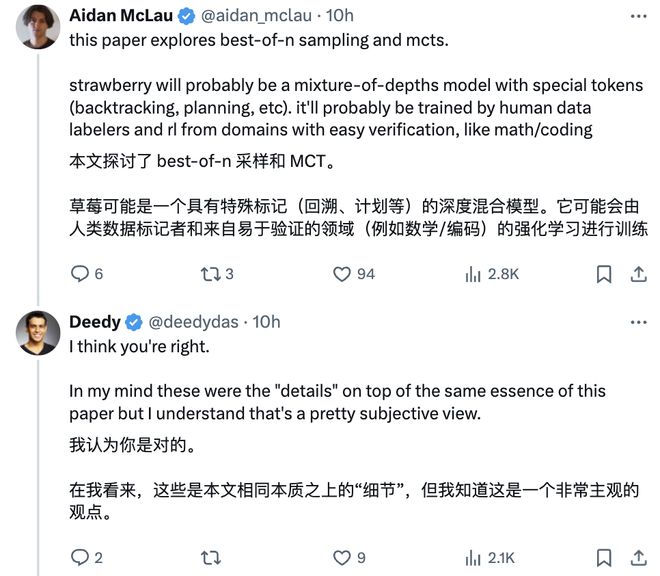
本文探讨了 best-of-n 采样和蒙特卡洛树搜索(MCTS)。
草莓可能是一种具有特殊 tokens(例如回溯、规划等)的混合深度模型。它可能会通过人类数据标注员和来自容易验证领域(如数学/编程)的强化学习进行训练。

论文链接:https://arxiv.org/pdf/2408.03314
参考链接:






