
新智元报道
编辑:桃子好困
一条磁力链,又在 AI 圈掀起狂澜。成立一年法国 AI 独角兽 Mistral,官宣首个多模态模型 Pixtral 12B,不仅能看懂手绘稿,还可以理解复杂公式、图表。
法国 AI 初创 Mistral AI,又扔出一条磁力链炸场了。

这次,与以往不同的是,他们发布了首个多模态模型 Pixtral 12B,集语言、视觉能力于一身。

这意味着,Mistral AI 正式跨界 MMML,开启多模态 AI 新时代,同时向 OpenAI、Anthropic 等劲敌发起挑战。
多模态 Pixtral 12B,是基于文本模型 Nemo 12B 完成训练。
与 GPT-4o、Claude 类似,只需上传一张图、提供一个链接,模型就能根据提示回答问题。
它不仅能够识别复杂手写笔记,还能看懂数学公式、图表等等。
在多项基准测试(文本、指令跟随、多模态)中,新模型性能大幅超越 Qwen2 7B、Phi-3 Vision 开源模型。
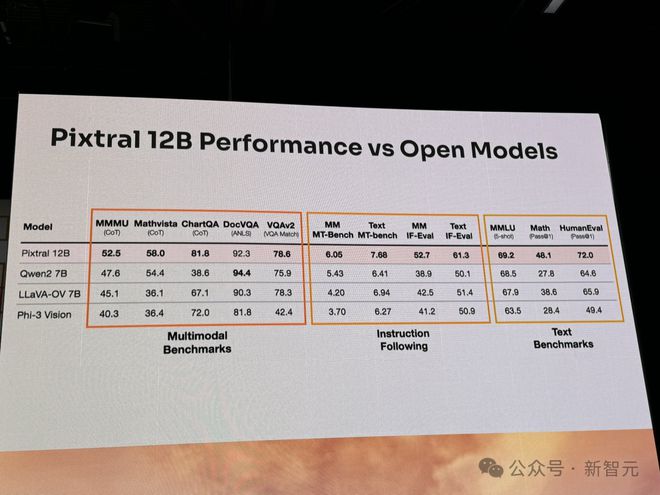
Hugging Face 技术负责人发现此处列举的 Qwen 的数据问题很大
相较于闭源模型,Pixtral 12B 在图表问答、文档问答、视觉数学推理、大学水平多学科等基准中,性能碾压 Claude3 Haiku、Gemini 1.5 8B。

除了大约 24GB 的磁力链,模型代码还可在 HuggingFace、GitHub 下载。(由社区开发者上传)
地址:https://huggingface.co/mistral-community/pixtral-12b-240910
值得一提的是,Mistral AI 现场还请来了老黄坐镇。

手绘稿直出代码,现场 Demo 惊艳
Mistral AI 在旧金山举办的首届 AI 峰会上,初次展示了 Pixtral 12B 的多模态能力。

现场,足以用震撼形容。
让它将一份科学报告转录为 Markdown 格式,可以看到图片中,包含了许多复杂的数学符号,还有公式。
Pixtral 12B 通过 OCR 能力,精准地识别出所有的内容。

再来一个更复杂的手写稿,别说 AI 了,小编也有些看不清写的什么字。
没想到,这也难不倒它。

给它扔一张关于美国「风险投资交易密度分布」的图表,并将其总结成一份表。
模型以不同州/城市,以及交易数量、区位商(LQ),列出了非常清晰的表格。

再来看看,它如何去描述一张图像的。
上传一张风景图,然后询问「我们可以从中看到什么」?
Pixtral 12B 先从各种动物近景描述,再延伸到背后建筑、基础设施,以及大树、天空云彩等。
整个讲述的过程,非常有逻辑。

在复杂图表方面,Pixtral 12B 理解力也是一绝。
上传一张全球不同国家 GDP 图片,让它给出欧洲中 GDP 最高的 5 个国家。
模型根据绿色欧洲区域,总结给出了相应的答案。

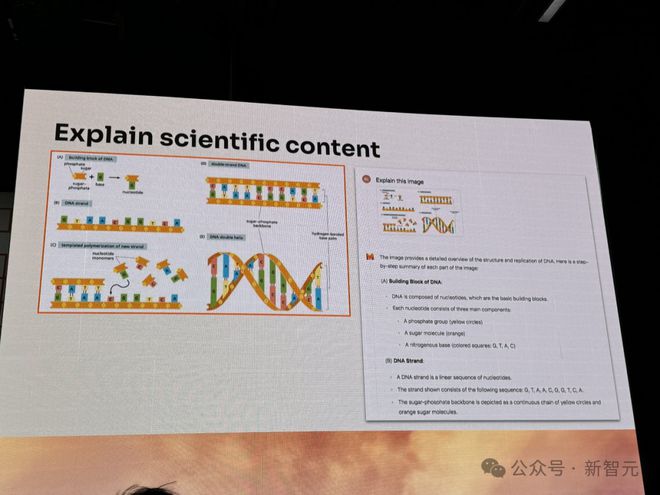
不仅如此,它还可以解释科学报告中,图表中 DNA 结构的具体含义。
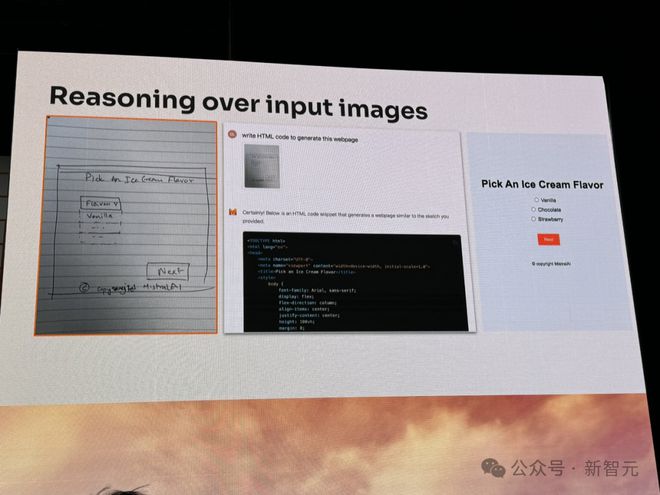
想要搭建一个网页,手绘一张草稿,传给模型。
它能看着图直出代码,一个网页 HTML 的设计分分钟就搞定了。
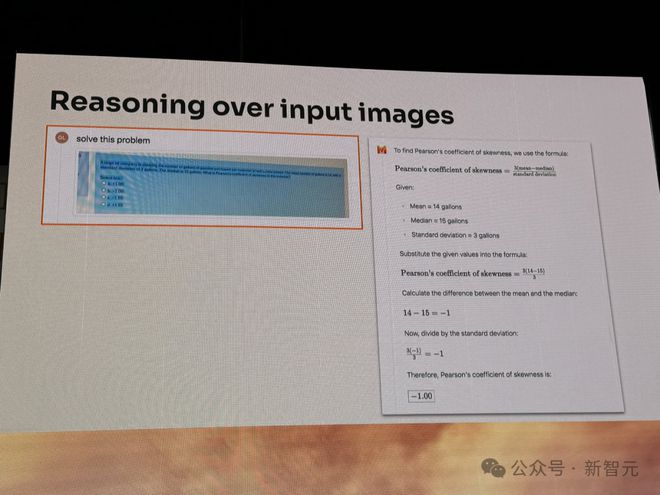
又或是,当你遇到一道数学推理难题,拍好照片上传给 Pixtral 12B,便会得到解题步骤和答案。
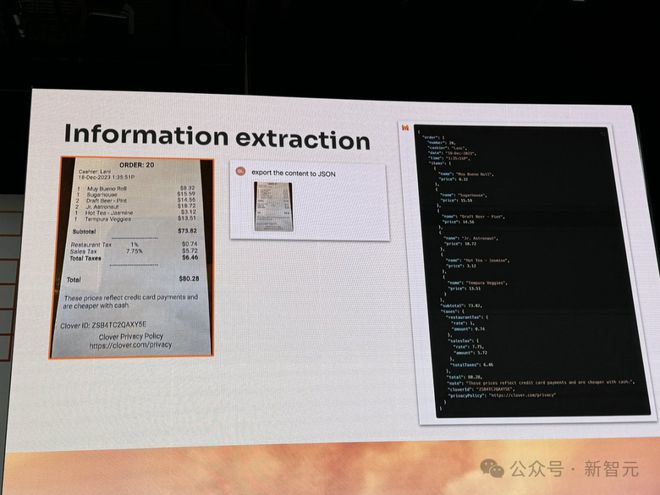
外出餐饮小票,它也可以将其中信息提取成 JSON 格式。
这样一通看下来,一个 120 亿参数的小模型,竟具备了如此强大的图像识别、文本理解能力。
那么,它是如何训练而来?背后架构是什么?
模型架构
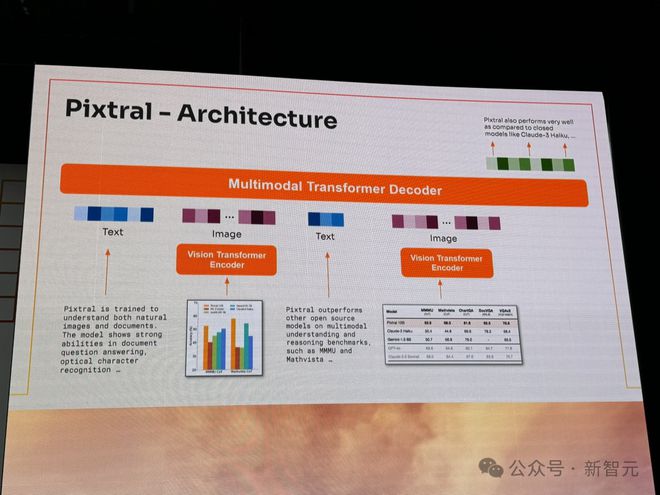
现场的介绍中,Pixtral 12B 的架构如下图所示。
它包含了一个多模态 Transformer 解码器,还有视觉 Transformer 编码器,能够理解原生的图像和文档。
正如开头所述,新模型是基于 Nemo 12B 完成搭建,关于训练数据目前仍在保密中。
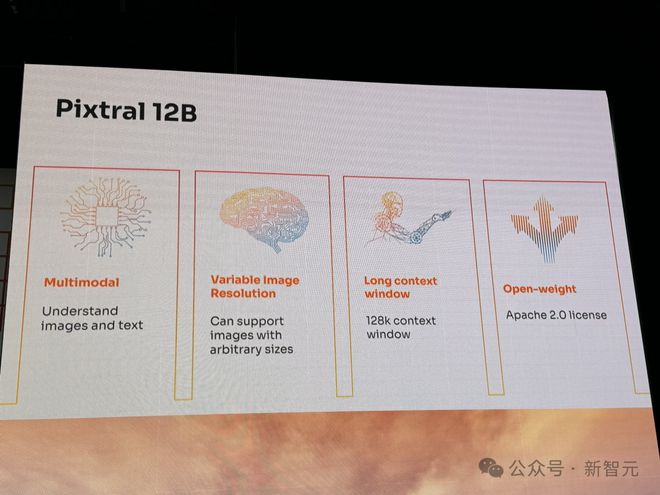
开发者关系主管 Sophia Yang 表示,「Pixtral 12B 独特之处在于,能够原生支持任意数量、大小的图像」。

它能够快速处理小图像,还可以精准处理真实世界和高分辨率的图像。而且,扔出一个图文混杂的大型文档,也能信手拈来。

Pixtral 12B 的上下文长度为 128k。
根据初始测试者的分享,这个 24GB 模型架构共有 40 层,14336 个隐藏维度,32 个注意力头,用于广泛的计算处理。
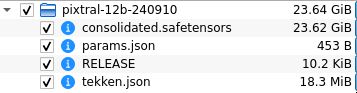
在视觉方面,它还有一个专用的视觉编码器,可支持 1024×1024 图像分辨率,以及 24 个隐藏层用于高级图像处理。
然而,当 Mistral 最终通过 API 提供该模型时,可能会有所改变。
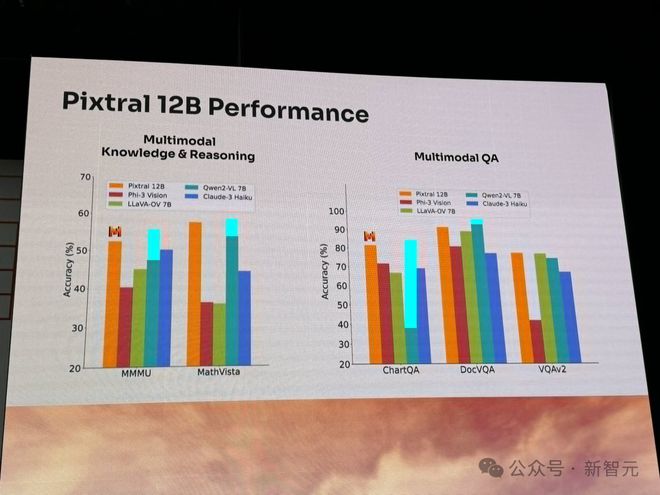
就性能来说,Pixtral 12B 在多模态知识和推理基准(MMMU、MathVista)、多模态问答基准(ChatQA、DocVQA、VQAv2)上,完全碾压当前领先的同等参数的模型。
比如,Qwen2-VL、LLaVA-OV、Phi-3 Vision 等。
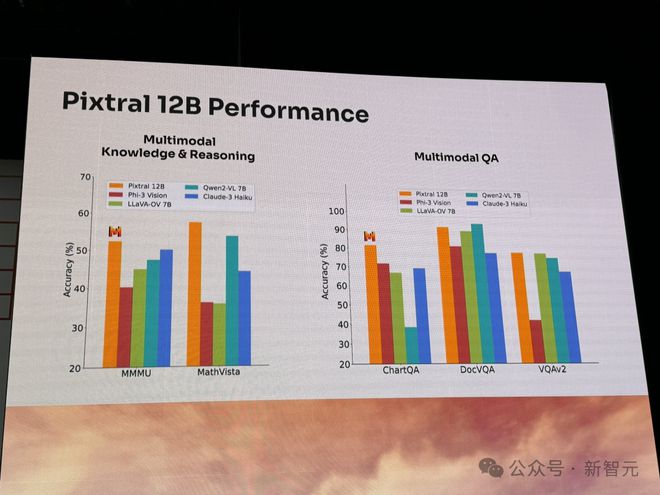
而在指令跟随(多模态、文本)、文本理解(科学、数学、代码)基准上,Pixtral 12B 表现也非常出色。
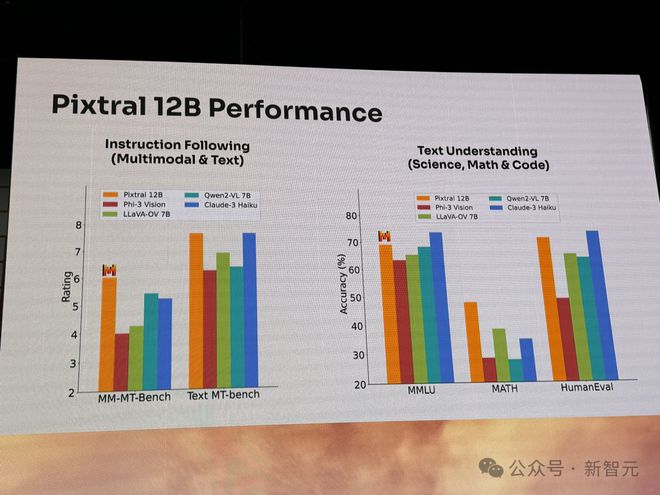
或许多模态模型对于我们来说,屡见不鲜,但 Pixtral 12B 对于 Mistral 来说是开创历史。
自去年成立以来,Mistral 凭借开源媲美 OpenAI 等领先实验室大模型,一路走红得到 AI 社区的认可。

几个月前,它以 60 亿美金估值,完成 6.4 亿美元新一轮融资,并随之推出了一款 GPT-4 级别的模型——Mistral Large 2。
此外,他们在今年,还推出了一个专家混合模型 Mixtral 8x22B,包含了一个编码模型 Codestral,以及一个数学推理和科学发现的模型。

Mistral 或许有实力,成为下一个 OpenAI。
穿上皮夹克,和老黄炉边谈话
更让人惊喜的是,大会现场,还上演了经典「皮夹克帮」集结的一幕。
创始人 Arthur Mensch 穿上皮夹克和老黄坐在台前,开启了炉边谈话,一起探讨了未来 AI 和算力问题。

老黄表示,在英伟达,GPU 的设计、性能、耗能等方面问题,仍将持续优化。
他们希望利用 AI 先去探索巨大设计空间的可能性,然后再进行收缩,最终专注于有前景的解决方案。
老黄还认为:推理在今天是一次性的,但在未来不会是这样。为了实现这一点,还需把推理速度提高到一个数量级。
因为,利用 GPU 做推理面临着显著的困难,英伟达 90% 的工程师都投在了推理,而非训练中。
当然,英伟达对推理技术架构的探索,仍在继续。老黄希望 NVLink 能够实现低延迟高吞吐量的推理设计。
对于 AI 未来的探索,老黄表示自己最喜欢的 AI 应用,便是创建数字人。
他希望,未来公司会有数百万个智能体数字员工,可以自主相互交流,运营业务。

此外,他还讨论了英伟达在「类人机器人」领域的大量工作。
而它的发展,受到了老黄所言的「3 台计算机问题」的瓶颈制约——
第一台用于训练多模态模型,第二台用于精确物理模拟和生成合成数据(NVIDIA Omniverse),第三台是机器人体内的计算机(即将推出的 NVIDIA Thor)。
最后,老黄还回顾了英伟达历史,「在 1993 年成立之时,我们在 GPU 领域还没有竞争对手,到 1994 年有 10 个,1995 年有 50 个,然后有 100 个,竞争对手迅速增加」。
在竞争这么激烈领域中,英伟达能够有所成,一定程度上,可以归咎于你所做的事情与做这些事情的原因不同。
英伟达是 PC 游戏行业的最大推动者,他们通过创建计算平台、生态系统来创造一个新市场,使之成为「家庭的一部分」。
他们最先在游戏领域做到了这一点,然后是科学计算,现在是 AI。
大佬发现「华点」:又来一个评测造假的?
前两天,所谓的「开源新王」Reflection 70B 才刚刚深陷 Benchmark 造假争议。
如今,相似的剧情再次上演。
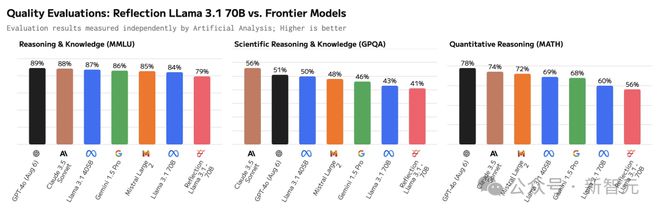
随着峰会现场的照片大范围流出,Hugging Face 技术负责人 Philipp Schmid 也在第一时间发现,Mistral AI 放出的跑分和 Qwen 2 VL 7B 的官方数据大相径庭。
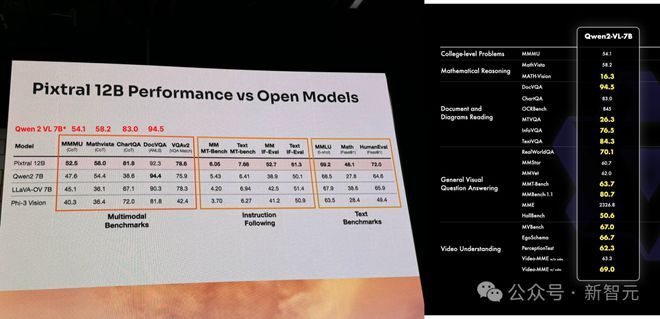
把数据补全到柱状图中后可以看道,Pixtral 12B 在多项评测中的成绩都明显不如 Qwen 2 VL 7B。
也就是说,Mistral AI 的首个多模态模型,被一个参数量小了近 42% 的模型,吊打了!
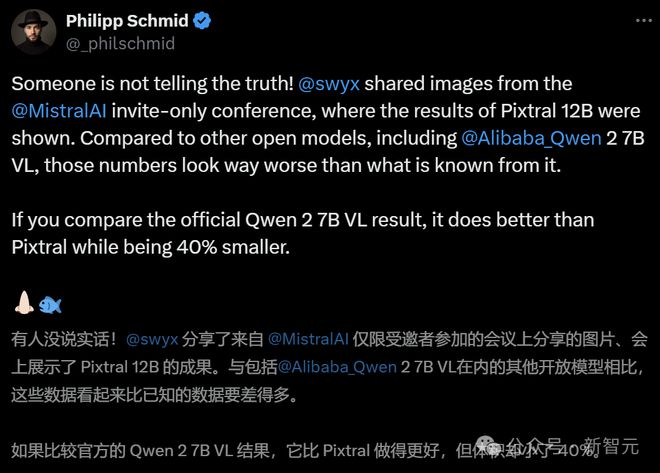
此外,还有网友指出,别说数据有问题,他们连模型的名字好像都没写对……

参考资料:
https://venturebeat.com/ai/pixtral-12b-is-here-mistral-releases-its-first-ever-multimodal-ai-model/






