AddressCLIP 项目组投稿
量子位公众号 QbitAI
拔草星人的好消息来啦!
中科院自动化所和阿里云一起推出了街景定位大模型,只要一张照片就能实现街道级精度的定位。
有了模型的帮助,再也不用害怕遇到种草“谜语人”了。
比如给模型看一张旧金山的街景之后,它直接给出了具体的拍摄位置,并列举了附近的多个候选地址。

该模型名为 AddressCLIP,基于 CLIP 构建。
相关论文 AddressCLIP: Empowering Vision-Language Models for City-wide Image Address Localization 已入选顶会 ECCV2024。

传统的图像位置识别往往致力于以图像检索的方式来确定图像的 GPS 坐标,这种方法称为图像地理定位。
但 GPS 对于普通人来说晦涩难懂,并且图像检索需要建立并维护一个庞大的数据库,难以本地化部署。
本篇工作提出了更加用户友好的,端到端的图像地理定位任务。二者的对比示意图如下:

针对这个任务,为了实现上述效果,研究人员主要从数据集构建与定制化的模型训练两方面入手开展了研究。
图像地址定位数据集构建
图像地址定位本质上是需要将街景图像与地址文本进行图文模态的对齐,因此首先需要收集大量的图像-地址对。
考虑到现有的用于多模态训练的图文数据中包含地址信息的数据比例过于稀少,研究人员选择基于图像地理定位中的图像-GPS 数据对进行数据集的构造。
具体来说,通过使用地图中的 Reverse Geocoding API,可以对一个 GPS 查询到一系列的相近的地址。
接着,通过筛选、投票等数据清洗机制,可以过滤得到每个图像的街道级地址文本。
这一过程如下图所示:
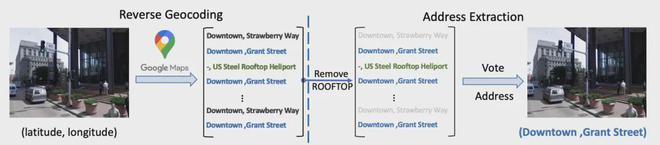
然而,考虑到街道本身的长短分布差异巨大,导致这个分布极度不均衡,同时街道级别的定位精度仍然过于粗糙。
因此,研究人员模仿人类描述位置的习惯,对于街道级别的地址进行了进一步的语义地址划分。
该过程通过使用道路交叉的十字路口等信息来对地址信息进行加强,其具体过程以及最终形成的地址文本描述如下:
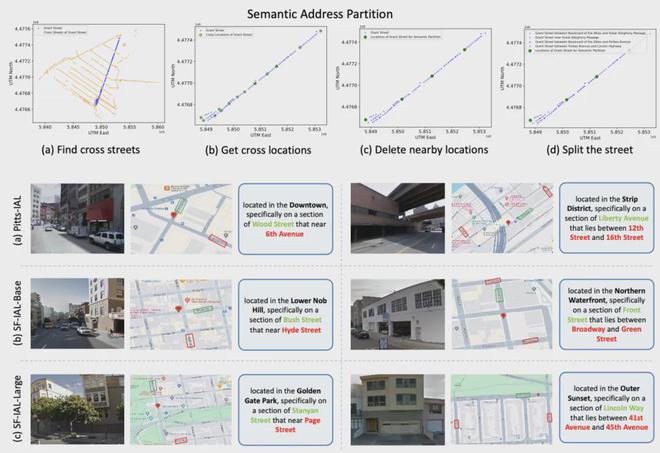
最终,论文构造了位于两个城市,三种不同尺度的数据集,相关数据信息如下:
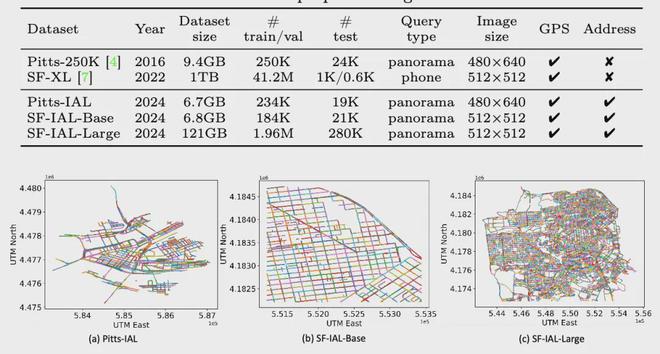
AddressCLIP 具体实现
有了上述街景-地址文本的数据准备之后,似乎直接模仿 CLIP 的方式进行对比学习的微调即可。
但考虑到本任务的图像-文本数据对的语义关联十分微弱,这和 CLIP 预训练的数据存在着比较大的差异。
因此研究人员首先从数据和损失函数层面进行了对 CLIP 原始的训练框架进行了改进。
具体来说,借助以 BLIP 为代表的多模态生成模型的图像标注能力,研究人员对于训练数据中每个街景图像进行了语义文本的自动化标注。

然后,作者将语义文本与地址文本按照一定规则直接进行拼接,显式的弥补了本任务和 CLIP 预训练任务的差异。
这样一来,微调过程优化更加容易,并且也能过通过语义隐式增强了地址文本的判别性。
此外,考虑到图像特征,地址文本特征在预训练特征空间的分布可能是十分不均匀的。
受到流形学习的启发,作者认为本任务中图像-地址文本的理想特征应该位于一个和真实环境匹配的低维流形上。
具体来说,研究人员们引入了在真实地理环境中距离相近的两个点,其地址与图像特征在特征空间也应当接近,反之亦然这一假设。
利用图像与图像两两之间归一化后的真实地理距离来监督它们在特征空间中的距离,从而实现了图像特征与真实地理环境的在距离层面的匹配,使得模型学到的特征空间更加均匀。
因此,AddressCLIP 将经典的 CLIP 损失优化为图像-地址文本对比损失,图像-语义对比损失以及图像-地理匹配损失,最终实现了准确、均匀的图像-地址文本对齐。
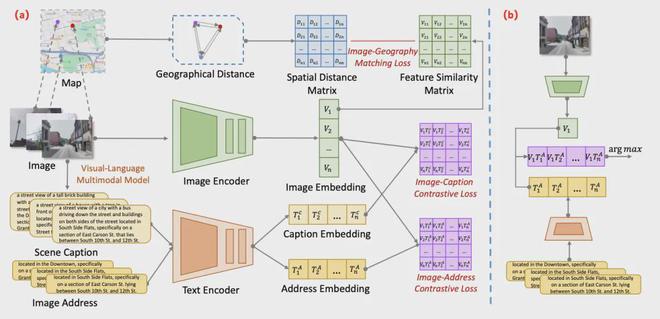
完成上述训练后,AddressCLIP 可以通过给定候选地址集的形式进行推理。
值得一提的是,得益于模型将图像与各种地址的良好对齐,推理所用的候选文本可以是十分灵活与多样的形式,而非一定要按照训练集的书写规则。
效果优于通用多模态模型
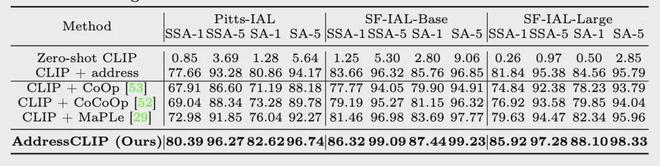
在定量实验结果中,团队主要将模型与与 zero-shot 的 CLIP,直接对齐地址的 CLIP 以及各种 CLIP 微调策略方法等进行对比。
可以看到,AddressCLIP 在不同数据集,不同指标上均优于各个所比较方法。
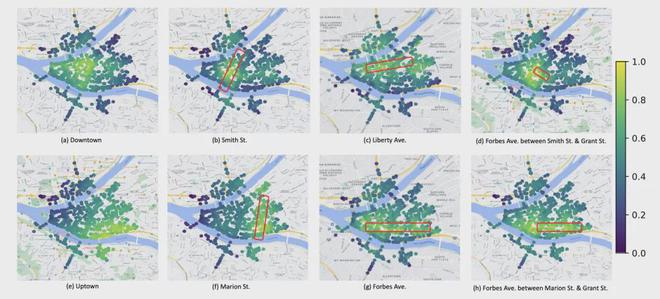
在定性实验中,论文主要展示了 AddressCLIP 在推理形式上的灵活性与泛化性。
通过给定不同精细程度的地址文本的查询(如街区,街道,子街道),模型都可以在测试集图像上展示出与其真实覆盖地理分布一致的激活。
此外,研究人员也畅想了这一任务与数据集与多模态大模型结合的场景。
通过将数据集构造成关于地址问答的多轮对话形式,团队对 LLaVA-1.5-vicuna 进行了视觉指令微调,实现了对图像地址的生成式识别。
在与前沿多模态模型的对比中展现出明显的优势,尤其是针对图像中不存在地标与明显线索的图像。

作者预计,未来这一技术可以进一步扩展应用于社交媒体基于位置的个性化推荐上,或者与多模态大模型结合进行更加丰富的地址,地理信息相关问答,提供更加智能的城市、地理助手。
论文地址:
https://arxiv.org/abs/2407.08156
项目主页:
GitHub:






