
新智元报道
编辑:LRS
NVLM 1.0 系列多模态大型语言模型在视觉语言任务上达到了与 GPT-4o 和其他开源模型相媲美的水平,其在纯文本性能甚至超过了 LLM 骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了 4.3 个百分点。
文本大模型经过多年的发展,逐渐发展成了统一的纯解码器 Transformer 架构。
反观现有的多模态大模型架构仍然处于混乱状态,开源模型在选择 LLM 主干、视觉编码器以及训练数据方面都存在差异,性能优异的闭源多模态大模型也没有公布相关信息,无法直接进行模型对比和研究。
并且,不同模型在处理高分辨率图像输入时的设计(如动态高分辨率)虽然可以提高了与 OCR 相关的任务(例如,OCRBench)的性能,但与低分辨率版本模型相比,在推理相关任务(例如,MMMU)上的准确率却会下降。
此外,虽然开源的多模态大模型在视觉-语言任务上取得了非常亮眼的基准测试结果,但在纯文本任务上的性能却有显著下降,与领先的闭源模型(如 GPT-4o)的表现并不一致。
为了改变这一现状,英伟达的研究团队最近宣布推出 NVLM 1.0,在视觉-语言任务上取得了最先进的成果,能够与最强大的闭源模型(如 GPT-4o)和开源模型(如 Llama 3-V 405B 和 InternVL 2)相媲美,并且在多模态训练后,其文本性能甚至超过了所采用的 LLM 主干模型。

论文链接:https://arxiv.org/pdf/2409.11402
项目主页:https://nvlm-project.github.io/
在模型设计方面,研究人员对纯解码器多模态大模型(如 LLaVA)和基于交叉注意力的模型(如 Flamingo)进行了全面对比,并根据总结出的优势和劣势,提出了一种全新架构,提升了模型的训练效率和多模态推理能力。
文中还引入了一种1-D 图块(tile)标签设计,可用于基于 tile 的动态高分辨率图像,能够显著提高多模态推理和与 OCR 相关任务的性能。

在训练数据方面,研究人员在文中详细介绍了多模态预训练和监督微调数据集的详细信息,结果表明,数据集的质量和任务多样性比规模更重要,对所有的架构来说都是如此。
值得注意的是,研究人员将高质量的纯文本数据集精心整合到多模态训练中,并辅以大量的多模态数学和推理数据,从而在各个模态上增强了数学和编码能力,使其在视觉-语言任务上表现出色的同时,保持甚至提高了纯文本性能。
NVLM 1.0 模型架构
NVLM-1.0 包括三种可选架构:
1. 仅解码器的 NVLM-D
2. 基于 Cross (X)-attention 的 NVLM-X
3. 采用混合架构的 NVLM-H
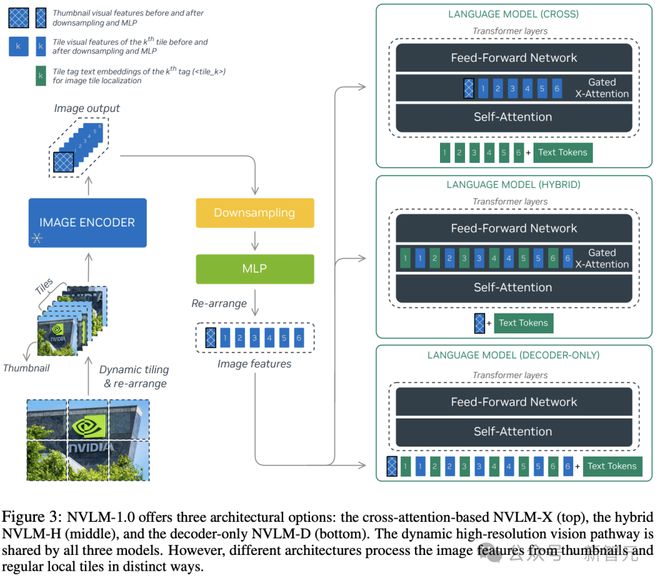
1. 共享视觉路径(Shared Vision Pathway)
研究人员使用单一的、大型的、表现优异的视觉编码器 InternViT-6B-448px-V1-5 作为默认选项,在所有训练阶段都保持冻结状态,以固定的分辨率 448×448 处理图像,生成 1024 个输出 token,在训练中最多 6 个图块(tiles),预定义的宽高比为{1:1, 1:2, 1:3, 1:4, 1:5, 1:6, 2:1, 2:2, 2:3, 3:1, 3:2, 4:1, 5:1, 6:1},覆盖了所有可能情况。
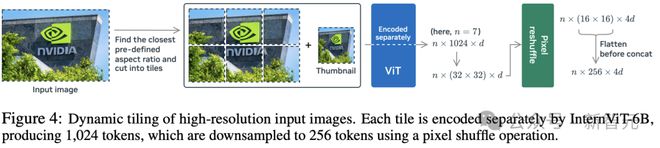
然后执行下采样(downsampling)操作,沿着通道维度将 1024 个图像 token 减少到 256 个,将四个相邻的图像 token 组合成一个,以节省 LLM 处理开销。
动态高分辨率(DHR)设计显著提高了与 OCR 相关的任务性能,但当所有 tile 的图像 token 直连输入到 LLM 时,有时会导致推理相关任务的性能下降,研究人员在三种架构中分别解决该问题。
2. NVLM-D:纯解码器模型
NVLM-D 模型使用一个 2 层多层感知器(MLP)作为投影器(projector)或模态对齐(modality-alignment)模块,将预训练视觉编码器连接到大型语言模型。
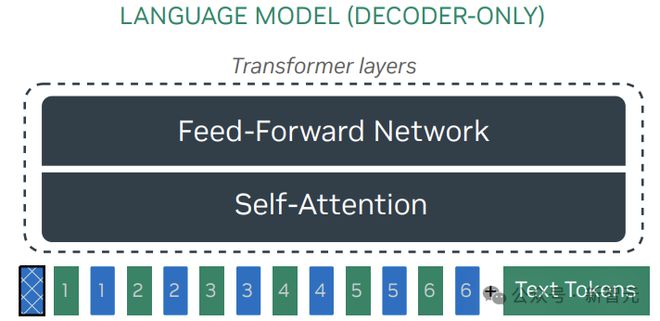
NVLM-D 的训练包括两个阶段:预训练和有监督微调(SFT),其中 MLP 是随机初始化的,需要先进行预训练,同时保持视觉编码器和 LLM 主干冻结。
在探索过程中,研究人员发现当视觉编码器相对较弱(如 ViT-L/14)且预训练数据集足够多样化时,MLP 投影器和视觉编码器的联合预训练是有益的;在升级到更强大的 InternViT-6B-448px-V1-5 后,性能增益变得微乎其微。
为了简化,研究人员选择在预训练期间保持视觉编码器冻结;在 SFT 阶段,MLP 投影器和 LLM 都需要训练以学习带有新指令的新视觉-语言任务,且保持视觉编码器冻结。
以往文献中很少讨论的是,在多模态 SFT 训练期间不冻结 LLM 权重通常会导致纯文本性能显著下降,NVLM-D 模型通过整合高质量的纯文本 SFT 数据集,有效地保持了纯文本性能。
动态高分辨率的图块(tile)标签
大型语言模型(LLM)的主干需要处理所有动态高分辨率 tile 的扁平图像 token,包括一个额外的缩略图 tile,如果不加分隔符可能在输入 LLM 时产生歧义,因为语言模型没有动态平铺(dynamic tiling)过程的先验知识。
为了解决这个问题,研究人员在输入序列中插入一个基于文本的 tile 标签以标记图块的开始以及在整个平铺结构中的位置,然后在标签后附加 tile 的 256 个图像 token,总共设计了三种标签:
1)无标签:无 tile 标签直接连接,也是 InternVL-1.5 的设计。
2)1-D 扁平化 tile 标签: , , ..., ,
3)2-D 网格标签: , , ..., ,
4)2-D 边界框标签: (x0, y0), (x1, y1) , ..., (xW, yH), (xW+1, yH+1) ,其中两个坐标分别为(左, 顶部),(右, 底部)。
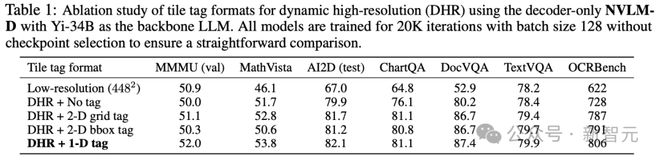
从消融实验结果中可以观察到:
1)纯粹的动态高分辨率方法(DHR + 无标签)在所有基准测试中的性能都有显著提高;
2)在 LLM 解码器中插入其他类型的图块标签,其性能显著优于简单的无标签连接,还能极大改善与 OCR 相关任务的性能。
3)1-D 瓦片标签通常比其他标签表现更好,虽然无法提供2-D 信息(例如,2×3 与3×2),但在测试阶段具有更好的泛化能力。
3. NVLM-X:X-attention 模型
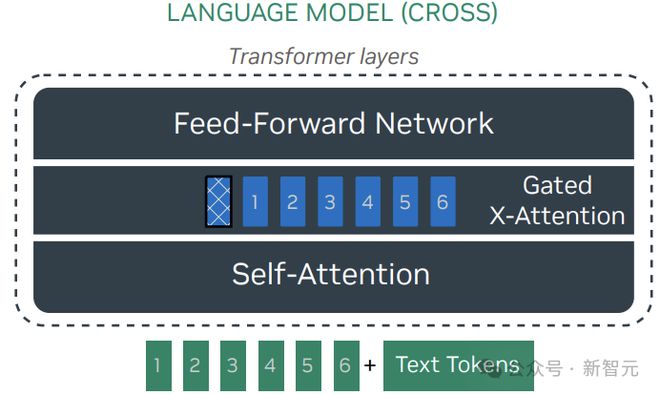
NVLM-X 使用门控交叉注意力来处理图像 token,与 Flamingo 模型不同的是:
1)感知器重采样器对自然图像描述是有益的,但对密集 OCR 任务会产生负面影响,主要是因为感知器中的交叉注意力到潜在数组混合了输入图像 token,可能会破坏图像块之间的空间关系,而这些关系对于文档 OCR 至关重要,所以 NVLM-X 完全依使用交叉注意力直接从视觉编码器读取图像 token
2)在多模态监督式微调(SFT)阶段冻结大型语言模型(LLM)会损害视觉-语言任务的性能,因为模型需要快速适应在纯文本指令调整期间未遇到的新任务和新指令;因此,在多模态 SFT 期间,研究人员解冻了 NVLM-X 的 LLM 主干,并混合了高质量的纯文本 SFT 数据集,以保持强大的纯文本性能。
NVLM-X 的动态高分辨率图块标签与 NVLM-D 相同,采用门控X-attention 来处理每个图块的扁平化图像 token。
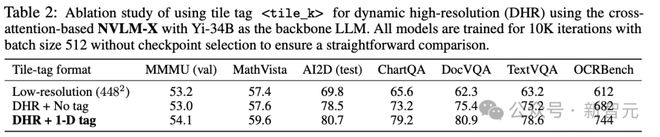
消融实验中,使用低分辨率 448×448 输入,动态高分辨率(DHR)无图块标签和带有1-D 标签的情况,可以发现:原始的动态高分辨率方法(DHR + 无标签)在所有基准测试中都显著优于其低分辨率对应结果;添加图块标签在所有基准测试中都提高了性能,包括多模态推理和 OCR 相关的任务。
4. NVLM-H:混合模型
NVLM-H 是一种混合架构,结合了 NVLM-D 和 NVLM-X 的优势,将图像 token 的处理分为两条路径:缩略图 token 与文本 token 一起输入到大型语言模型中,并由自注意力层处理,实现了联合多模态推理。
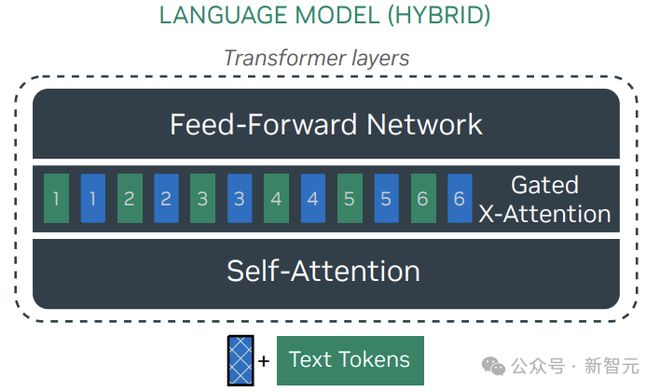
同时,通过门控交叉注意力处理动态数量的常规图块(regular tile),使模型能够捕捉更精细的图像细节,相比 NVLM-X 增强了高分辨率能力,与 NVLM-D 相比显著提高了计算效率,在训练中的吞吐量高于 NVLM-D

动态高分辨率的图块标签
NVLM-H 使用了与 NVLM-D 相同的1-D 平展图块标签 ,主要区别在于处理位置, 的文本嵌入与视觉嵌入一起集成到门控交叉注意力层中,能够在预训练期间有效地对齐文本和视觉嵌入,使模型能够在交叉注意力机制内无缝解释图块标签。
实验结果
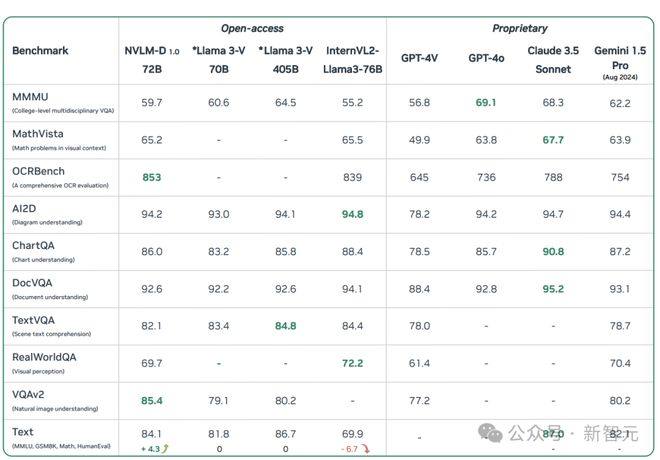
在九个视觉-语言基准测试和四个纯文本基准测试上的结果显示,NVLM-1.0 72B 模型可以与其他最强的开源、闭源模型(例如,GPT-4o)相媲美,包括尚未公开可用的 LLaMA 3V 和 InternVL 2
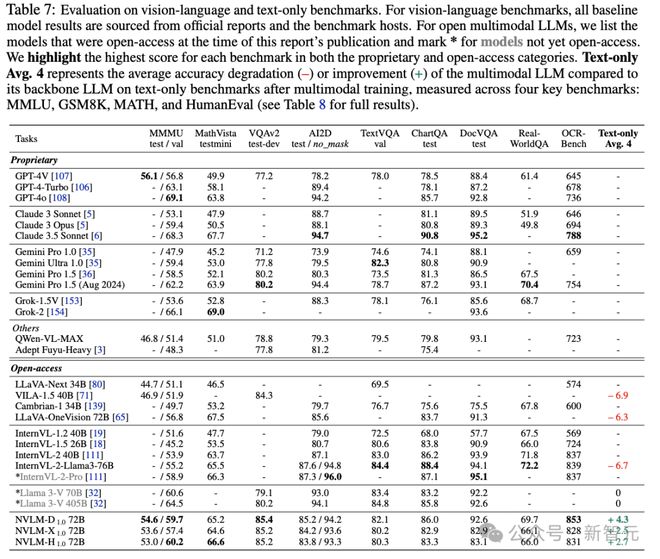
NVLM-D1.0 72B 在 OCRBench(853)和 VQAv2(85.4)上取得了所有对比模型的最高分,其 MMMU 得分(59.7)也在本报告发布时显著超过了所有开源模型,包括 LLaVAOneVision 72B(56.8)和 InternVL-2-Llama3-76B(55.2)。在 AI2D、TextVQA、ChartQA 和 DocVQA 上,其表现仅略逊于表现最佳的 InternVL-2-Llama3-76B,与的 GPT-4o 相当,并显著优于其他开源模型。
NVLM-H1.0 72B 在所有开源多模态 LLMs 中取得了最高的 MMMU(Val)得分(60.2),还在 NVLM-1.0 家族中取得了最佳的 MathVista 得分(66.6),已经超越了许多非常强大的模型,包括 GPT-4o、Gemini Pro 1.5(2024 年 8 月)、InternVL-2-Pro,证明了其卓越的多模态推理能力。
NVLM-X1.0 72B 也取得了前沿级别的结果,并且作为同类中最佳的基于交叉注意力的多模态 LLMs,能够与尚未发布的 Llama 3-V 70B 相媲美。NVLM-X1.0 还有一个优势:训练和推理速度更快。
开源的多模态大型语言模型,如 LLaVA-OneVision 72B 和 InternVL-2-Llama3-76B,在多模态训练后在纯文本任务上表现出显著的性能下降;相比之下,NVLM-1.0 模型的纯文本性能甚至略有提高,主要得益于包含了高质量的纯文本监督式微调(SFT)数据,也表明,只要融入了高质量的文本对齐数据,在多模态 SFT 期间解冻 LLM 主干并不会损害文本性能。
参考资料:






