
新智元报道
编辑:桃子
一年一度的 NeurIPS 2024 评审结果公布了。一大波网友纷纷晒出自己的成绩单。不过,这届顶会又成为吐槽灾区了。
NeurIPS 2024 评审结果已经公布了!
收到邮件的小伙伴们,就像在开盲盒一样,纷纷在社交媒体上晒出了自己的成绩单。

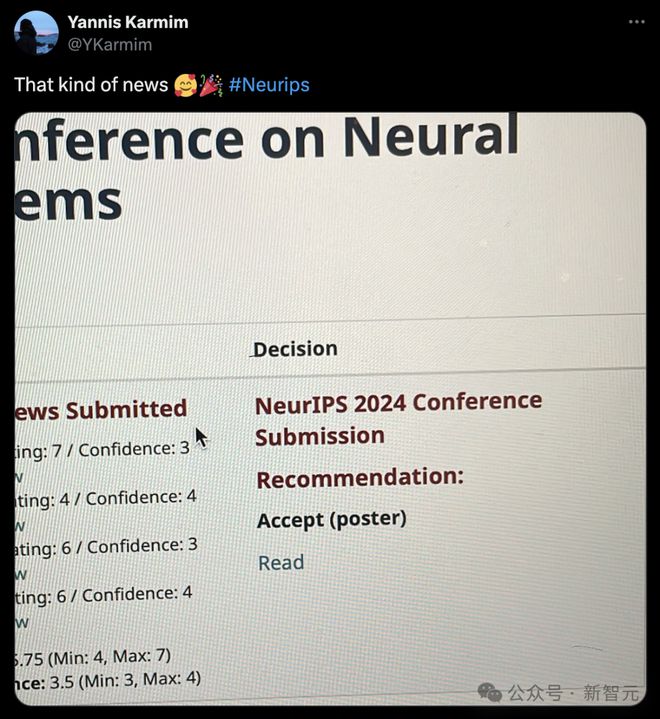
俄亥俄州立大学助理教授晒图,明明评审员给的评价是「论文接收」,却没想到最终决定是「拒收」。

应该给这位审稿人颁发一个 NeurIPS 2024 最佳 AC 奖
顺便提一句,今年是 NeurIPS 第 38 届年会,将于 12 月 9 日-15 日在加拿大温哥华举办。

AI 大佬晒出成绩单
一些网友们早已晒出了自己的录用结果,好像一件大事。
来自洛桑联邦理工学院(EPFL)的博士 Maksym Andriushchenko 称,自己有 3 篇论文被 NeurIPS 2024 接收。
它们分别是:
论文一:Why Do We Need Weight Decay in Modern Deep Learning?

论文地址:https://arxiv.org/pdf/2310.04415
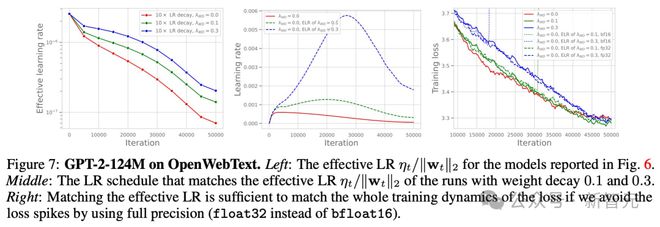
权重衰减(weight decay),比如在 AdamW 中传统上被视为一种正则化的方法,但效果非常微妙,即使在过度参数化的情况下也是如此。
而对大模型而言,权重衰减则扮演者完全不同的角色。与最初一版 arXiv 论文相比,研究人员对其进行了很多更新。
Andriushchenko 表示,自己非常喜欢这项新实验,并且匹配了 AdamW 有效学习率,得到了完全相同的损失曲线,而没有使用权重衰减。
论文二:JailbreakBench(Datasets and Benchmarks Track)

论文地址:https://arxiv.org/pdf/2404.01318
JailbreakBench 是全新评估大模型越狱能力的基准。上个月,该数据集在 HuggingFace 上,被下载了 2500 次。
而且,多家媒体还使用了这个越狱神器,Gemini 1.5 技术报告中也将其用于模型稳健性的评估。

论文三:Improving Alignment and Robustness with Circuit Breakers

论文地址:https://arxiv.org/pdf/2406.04313
这篇论文发布之初,已经掀起了不少的讨论。
其中最重要的一点是,它有助于训练 Cygnet 模型,其在越狱竞技场上表现出惊人的性能,而这正是对防御是否有用的测试。

来自 UT Austin 的副教授 Qixing Huang 也有三篇论文被 NeurIPS 录用。

它们分别是:
局部几何感知神经曲面表示法 CoFie。

以及另外两篇,一个是参数化分段线性网络 PPLN,另一个是关于时空联合建模的运动生成。


谷歌 DeepMind 团队 Self-Discover 算法被 NeurIPS 2024 录用。
中国有句古话:千人千面。正如每个人都是独一无二的,每个问题也是独一无二的。如何让 LLM 通过推理解决复杂的看不见的问题?
Self-Discover 最新论文证明了,模型可以从一般问题解决技术的集合中,组成特定用于任务的推理策略。
最新算法在 GPT-4 和 PaLm 2-L 上的性能比 CoT 高 32%,而推理计算量比 Self-Consistency 少 10-40 倍。

论文地址:https://arxiv.org/pdf/2402.03620
又是被吐槽的一届
不论是哪个顶会,吐槽是必不可少的。
这不,网友们对 NeurIPS 2024 审稿结果,吵成一锅了。

纽约大学工学院的助理教授称,一篇在 NeurIPS 提交中得分相当高的论文被拒绝。原因竟是:「模拟器是用 C++ 编写的,而人们不懂C++」。

他表示,论文被拒的现象太正常了,但是对这个被拒理由,实在是令人震惊。

还有一位大佬表示,团队的两篇关于数据集追踪的 NeurIPS 论文被拒了,尽管评审结果有积极的反馈。
这显然是,组委会试图人为地标尺较低的录取率。
「根据录取率而不是成绩来排挤研究,这一点其实我不太确定」。

无独有偶,UMass Amherst 的教员也表达出了这种担忧:
我看到很多人抱怨 NeurIPS 的 AC,推翻了最初收到积极评审论文的决定。
作为一名作者和评审员,我能理解这种做法有多令人沮丧。作为一名区域主席,我也经历过管理那些勉强达到录用分数的论文的压力,特别是当项目委员会要求更严格的录用率时。

有趣的是,NeurIPS 已经变得像「arXiv 精选」——突出展示前一年的最佳论文。

一位 UCSC 教授 Xin Eric Wang 表示,一篇平均得分为 6.75 的 NeurIPS 投稿被拒绝了。
他表示,这是自己收到第二荒谬的元评审,最荒谬的那次,是因为结果中没有加「%」就否决了论文。
无论论文质量如何,似乎总会有无数理由可以否决一篇论文。
元评审中提到的关键问题,在原始评审中只是小问题,而且他们团队已经在回复中明确解决。Xin Eric Wang 怀疑 AC 是否真正阅读了他们的回复: (1) AC 提出了一个重大问题,这是基于一个得分为 8 分的评审者的小建议,引用了「大部分数据」,但实际数字小于 10%(如回复中所述)。 (2) AC 指出缺少统计数据,这些数据评审者从未提及,而且在论文正文中已经清楚地呈现。

LLM 参与评审
而且 AI 火了之后,大模型也被用来论文评审。
这次,NeurIPS 2024 也不例外。
Reddit 网友评论道,自己用一个月的时间审核 6 篇论文,当看到自己得到的是 LLM 的评价,真的很受伤。


还有人指出,在自己审阅的论文中,至少发现了 3 篇由大模型生成的评审意见,很可能还有更多,其中 3 篇明显是直接复制粘贴了 ChatGPT 输出,完全没有阅读论文。
这些评审都给了 6 分,Confidence 为4,与其他所有人的评价完全不一致。

更有网友评价道,「论文评论的质量很低」。
一个评审者混淆了我们方法的基线,另一个评审者混淆了基线的派生(正如我们的工作所批评的那样)和我们方法的派生。我怀疑一些评论是由 LLM 产生的。

参考资料:






