
新智元报道
编辑:编辑部 HXY
o1 的秘诀,和全新的「推理 Scaling Law」关系有多大?Epoch AI 最近的对比实验表明,算法创新才是关键。
CoT 铸就了 o1 推理王者。
它开创了一种推理 scaling 新范式——随着算力增加、更长响应时间,o1 性能也随之增长。
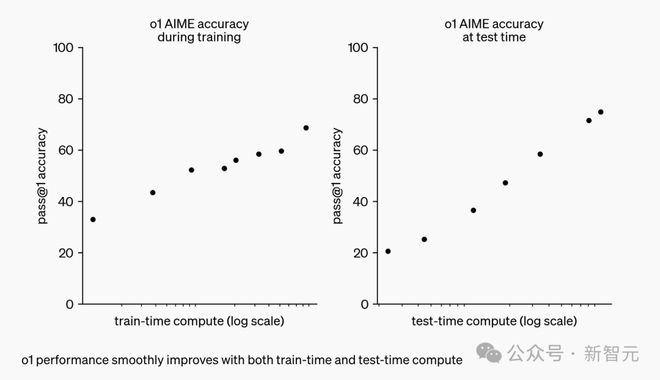
这一点,为 AI scaling 开辟了新的可能性。
既然如此,若是将 o1 这一训练过程直接应用到所有 LLM 中,岂不皆是「推理王者」。
然而,研究机构 Epoch AI 发现,结果并不是这样的。
单纯的扩展推理计算,根本不能弥合 o1-preview 和 GPT-4o 之间的差距。

他们称,「虽然 o1 使用了逐步推理方法训练,但其性能改进,可能还存在其他的因素」。
o1 的秘诀是什么?
上周,在 o1-preview 和 o1-mini 发布之后,Epoch AI 研究人员开启了 GPT-4o 和 o1-preview 对比实验。
他们选择了一个具有挑战性的基准测试 GPQA 进行评估,其中包含 STEM 领域研究生级别的多项选择题,而且考虑到模型的随机性进行了多次运行。
结果发现 o1-preview 的性能远远好于 GPT-4o,比 Claude 3.5 Sonnet、Llama3.1 405B 也拉开了相当大的差距。
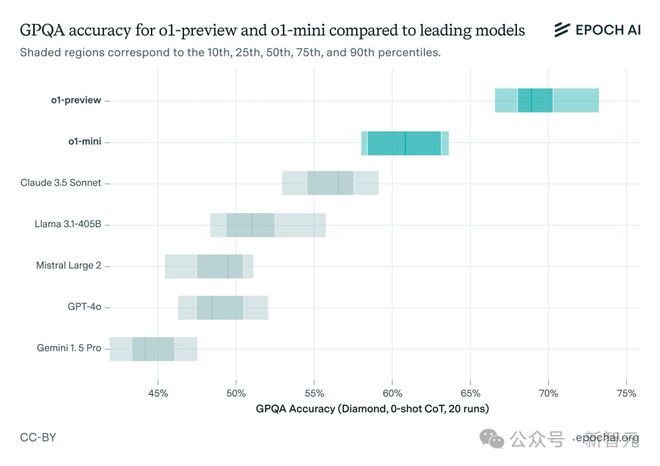
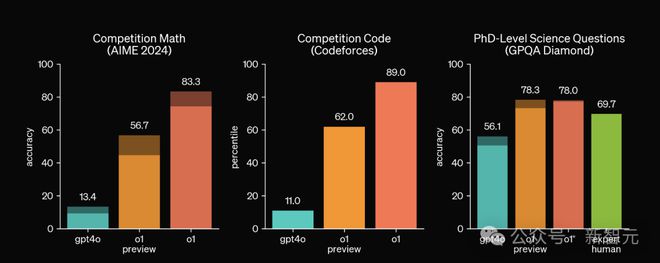
这个结果也和 OpenAI 自己放出的测试结果相吻合,尤其是在 AIME 和 Codeforces 这类难度更高的基准上,o1-preview 相比 GPT-4o 的提升更加明显。

然而,考虑到 o1 模型相比 GPT-4o 使用了更多的推理时计算,而且每个问题生成的 token 也更多,这种比较显得不太公平。
因此,研究人员使用了两种方法尝试增加 GPT-4o 的输出 token,类似于让 GPT-4o 模仿 o1 的思考过程。
- 多数投票(majority voting):选择k个推理轨迹中最常见的答案
- 修正(revision):给模型n次反思和改进答案的机会
值得注意的是,这些都是相对简单的方法。其实存在更复杂、有效的方法来利用推理时间计算,比如让过程奖励模型作为验证器参与搜索。
o1 模型很可能使用了更复杂的方法,但 Epoch 研究人员只是想建立一个比较基线,因此选择了较为基础的方法。
结果显示,虽然这两种方法都生成了更多的 token,并提高了 GPT-4o 的准确性,但依旧无法匹敌 o1-preview 的性能。
GPT-4o 变体的准确率仍然显著低于 o1-preview,差距始终大于 10 个百分点。
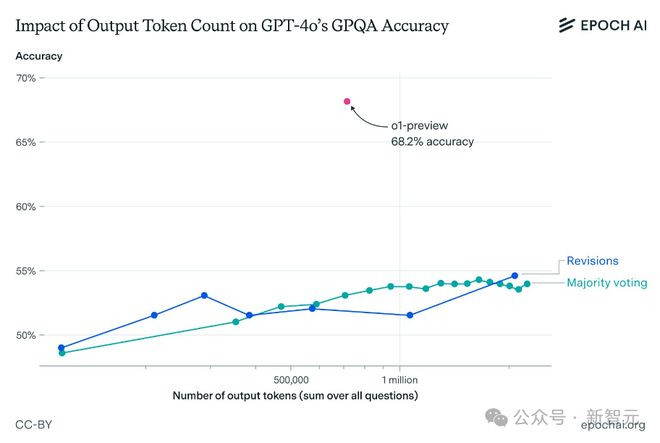
与 o1-preview 相比,输出 token 数量对 GPT-4o 在 GPQA 上性能的影响
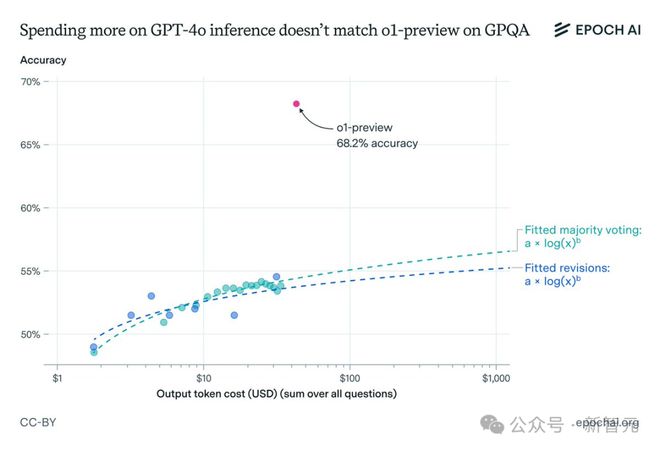
即使考虑到 o1-preview 每个输出 token 的成本更高,这种性能差距仍然存在。
Epoch AI 团队的推算结果表明,即使在 GPT-4o 上花费 1000 美元用于输出 token,准确率仍将比 o1-preview 低 10 多个百分点。
对 GPT-4o mini 进行相同操作后也能得到类似的结果,但在进行模型修正后,结果存在一些差异。
随着修正次数的增加,模型准确性不会持续提升,反而会在到达一定阈值后开始下降。这可能是由于 GPT-4o mini 在长上下文推理方面的局限。
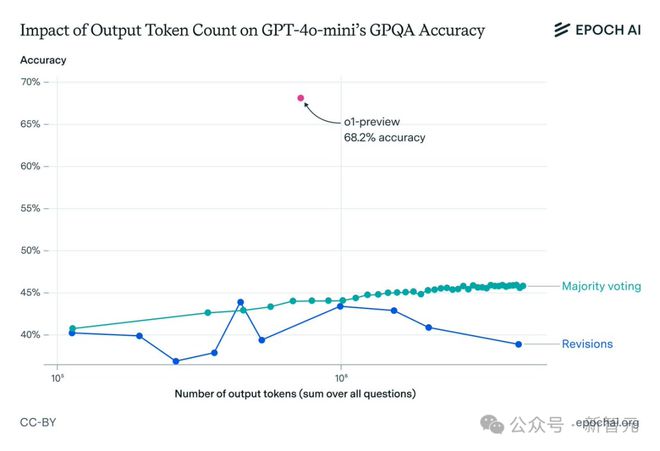
从以上结果可以看出,仅仅扩大推理处理能力并不足以解释 o1 的卓越性能。
研究作者认为,先进的强化学习技术和改进的搜索方法可能发挥了关键作用,凸显了在 Scaling Law 之外,算法创新对 AI 发展的重要性。
但是,我们也并不能确定算法改进是 o1-preview 优于 GPT-4o 的唯一因素,更高质量的训练数据也可能导致性能差异。
推理很强的 o1,差在规划能力
虽然 GPQA 或 AIME 这类问题相当困难,但一般只会考察模型的在 STEM 领域的知识储备和推理能力。那么强如 o1,它的规划能力如何?
2022 年,亚利桑那州大学的学者们曾经提出过一个用于评测 LLM 规划能力的基准套件 PlanBench,包括了来自 Blocksworld 领域的 600 个任务,要求将一定数量的积木按照指定顺序堆叠起来。
在 MMLU、GSM8K 等传统基准相继饱和时,两年前提出的 PlanBench 依旧没有饱和,可见当今的 LLM 在规划能力方面依旧有很大的提升空间。
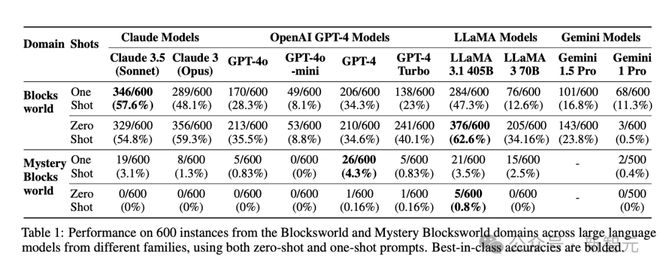
o1 之前的模型中,PlanBench 准确率很少超过 50%
最近,提出 PlanBench 团队又测试了一下最新的 o1-preview 模型,发现虽然 o1 的结果已经表现出了实质性改进,但仍然存在很大的局限性,不能完全解决规划任务。

论文地址:https://arxiv.org/abs/2409.13373
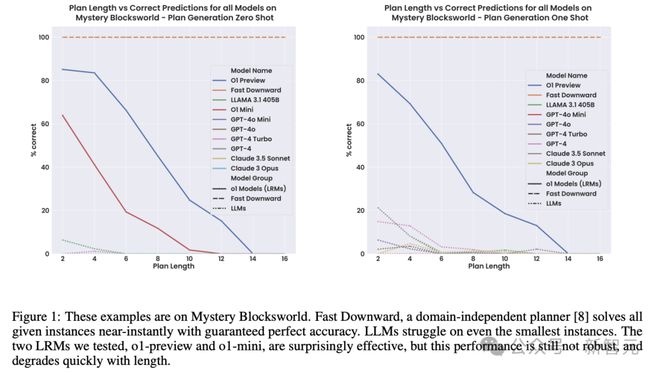
在 Blocksworld 任务上,o1 实现了 97.8% 的准确率,远远优于 LLaMA 3.1 405B 之前达到的最好成绩 62.6%。
在更具挑战性的任务版本 Mystery Blocksworld 上,之前的 LLM 几乎完全失败,而 o1 达到了 52.8% 的准确率。
此外,为了排除 o1 的性能提升源于训练数据中包含基准测试,研究人员还创建了 Mystery Blocksworld 的随机变体进行测试(表 2 中的 Randomized Mystery Blocksworld)。
o1 在随机变体测试集上的成绩从 52.8% 下降至 37.3%,但依旧超过得分接近于 0 的之前其他模型。

虽然 o1 和 o1-mini 都取得了不错的成绩,但性能并不稳健。随着任务逐渐复杂、计划步骤增加,性能会出现直线下降。
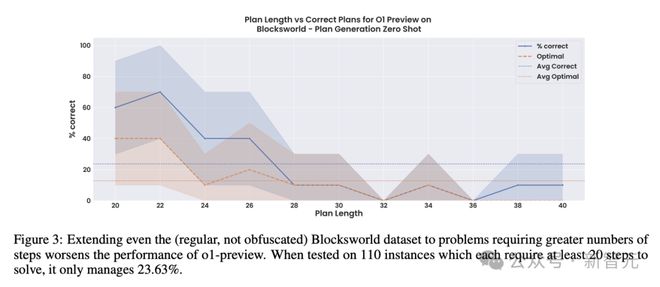
在这组含有 110 个实例的较大 Blocksworld 数据集上,每个问题都需要 20~40 个步骤的最佳计划,而 o1 的准确率从之前报告的 97.8% 直接下降至 23.6%,而且这些准确率大部分都来自步骤少于 28 的问题。
相比准确性更高、成本更低的传统方法,如经典规划器 Fast Downward 或 LLM-Modulo 系统,o1 这样的大型推理模型(LRM)非常缺乏正确性保证,而且使得可解释性几乎不可能,因此很难在实际应用中部署。
o1 虽强,但绝不是万能的。OpenAI 想要真正实现 AGI,还需要走很长一段路。
参考资料:
https://the-decoder.com/openais-o1-probably-does-more-than-just-elaborate-step-by-step-prompting/






