明敏发自凹非寺
量子位公众号 QbitAI
Meta 版 o1 也来了。
田渊栋团队带来新作 Dualformer,把快慢思考无缝结合,性能提升还成本更低。
能解决迷宫、推箱子等复杂问题。

通过让模型在推理轨迹和最终答案上进行训练,再基于特定策略丢掉部分轨迹,Dualformer 模型可以在模仿慢思考的同时,像快思考一样走捷径。
由此能形成更简洁的思维链(CoT)。
从结果来看,在慢思考模式下,Dualformer 的最优解率达到 97.6%,推理步骤减少 45.5%。
自动切换快慢思考模式下,最优率也达到 96.6%,且推理步骤减少 59.9%。
搞定 o1 玩不来的迷宫游戏
o1 带火了系统2(慢思考),能让大模型推理能力大幅提升。
但是随之而来的计算成本更高。
Dualformer 能很好结合快慢思考,从而缓解这一问题。
它建立在 Searchformer 这项工作的基础上。Searchformer 是一个可以解决复杂推理任务的模型,在A*搜索算法生成的路径上训练而来,在路径规划任务(如迷宫、推箱子游戏)上表现良好,可以以更高效率找到最优解。

研究发现,人类会在思考过程中倾向于找捷径。为了更进一步模拟人类,Dualformer 在随机推理轨迹数据上进行训练,并在训练过程中依据定制的丢弃策略丢到部分结构。
比如在处理路径规划任务时,根据搜索轨迹中的不同子句(如 close 子句、子句中的 cost tokens、create 子句等)设计了四个级别的丢弃策略,从只丢弃 close 子句到丢弃整个轨迹,并在训练时随机选择应用这些策略。

基于这些策略,Dualformer 可以学习更简洁有效的搜索和推理过程。
在推理阶段,Dualformer 可配置快速模式(仅输出解决方案)、慢速模式(输出推理链和最终解决方案)或自动模式(自行决定推理模式)。
这种灵活的推理模式设计使得模型能够根据不同任务需求和场景进行自适应调整,类似于人类思维在不同情况下的决策方式。
在具体任务上,研究设置了迷宫(Maze)和推箱子游戏(Sokoban),让模型进行路径规划。以及数学推理任务。
对比来看,在迷宫任务中,o1-preview 和 o1-mini 模型输出的路径并不好,会“穿墙”。
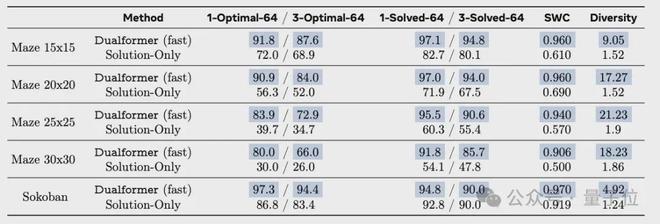
快思考模式下,Dualformer 的表现如下。
Dualformer 以 80% 的最优率完成这些任务,显著优于仅基于解决方案数据训练的 Solution-Only 模型,后者的最优率仅为 30%。
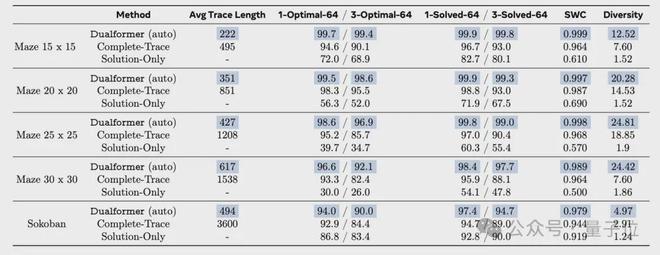
慢思考模式表现如下。
30×30 迷宫任务中,在 97.6% 的情况下可以达到最优解,同时推理步骤减少 45.5%。

自动切换快慢思考模式下,Dualformer 的最优率达到 96.6%,与 Searchformer 相比,推理步骤减少 59.9%。
将该方法推广到 Mistral-7B 和 Llama3-8B 上,在 Aug-MATH 数据集上,模型的表现都有所提升。
比如在 Mistral-7B 模型上,当p=0.1、0.2 和 0.3 时,Pass@20 度量的基线模型,其中绝对正确率增加到 61.9%。

最后,来看一下研究团队阵容。
该研究由田渊栋等人带来。
田渊栋现在是 Meta FAIR 的研究科学家主任,领导 LLM 推理、规划和决策小组。

Qinqing Zheng 是 FAIR 的工程师,研究方向集中在生成模型和强化学习方面。她本科毕业于浙江大学,在芝加哥大学攻读博士学位。2017-2019 年期间在 Facebook 担任研究科学家,帮助 Facebook 建立了广告推荐模型的分布式训练系统。

Sainbayar Sukhbaatar 是 FAIR 的研究科学家,主要负责大模型推理和记忆方面研究。他曾先后在谷歌、DeepMind、Meta 任职。

Michael Rabbat 是 FAIR 的创始成员之一。加入 Meta 之前他曾是麦吉尔大学计算机工程系教授。研究领域包括机器学习、分布式算法、信号处理等。

论文地址:






