
文商隐社,作者 浩然
AI 的发展给人们描绘了科技进步带来的“诗和远方”,但这背后却有着巨大的能源、资源、劳动力消耗,这是 AI 发展的沉重现实。
此外,AI 作为一种新型“巨机器”对人和社会的影响也被低估了。
01
谷歌在本周一表示,与 Kairos Power 公司签署一份从多个小型模块化反应堆购买电力的协议,以满足发展人工智能的用电需求。
谷歌计划买六到七个小型模块化反应堆的电力,总计 500 兆瓦,首个小型模块化反应堆在 2030 年之前投入使用。
而在上个月月底,微软和星座能源公司签署了一份为期 20 年的电力采购协议,计划重启曾因严重核事故而关闭的美国三哩岛核电站。
1979 年 3 月 28 日,三哩岛压水堆核电站的二号反应堆由于冷却系统失灵,造成 62 吨的堆芯熔毁事故,这是人类核能发展史上发生的第一起堆芯熔毁事件。
国际上把核电站事故分为 7 级,切尔诺贝利和福岛的核事故是唯二的两件 7 级事故,而三哩岛核泄露处于第 5 级。
星座能源在 1999 年买下了一号反应堆,就在发生事故的二号反应堆旁边,后来因为经济效益不好在 2019 年关闭了。
跟微软签协议后,星座能源将投入 16 亿美元对一号反应堆进行翻新,预计到 2028 年才开始重新发电,时间表受到监管批准的影响。
谷歌、微软搬出来核电站,一下子囤这么多电,主要将用来驱动 AI 数据中心。而且不只这两家,其他在 AI 领域布局的科技大佬都在这么干。
今年 3 月,亚马逊从塔伦能源公司购买了一个自带核电供应的数据中心园区;甲骨文最近也表示,正在设计 1 处由 3 个小型核反应堆供电的数据中心。
科技巨头之所以搞得这么大,是因为 AI 恐怖的耗电量。
AI 究竟有多耗电?
斯坦福人工智能研究所发布的《2023 年人工智能指数报告》显示,OpenAI 的 GPT-3 单次训练耗电量高达 128.7 万度,相当于 3000 辆特斯拉 Model Y 跑满 32 万公里的耗电量。这也是 120 个美国家庭 1 年的用电量。
这还只是训练用的电,相比后面不断使用的环节只是小头。
在使用环节,AI 每次作出回应也要大量耗电。像 ChatGPT 有 2 亿多用户,每天响应这些需求就要耗 50 万度电。
大模型的参数量越大,需要处理的数据就越多,所需要的计算量就越大,而算力背后是大量的服务器、存储设备和网络设备,它们日夜不停地工作,消耗大量电能。
曾有业内人士表示,国内一线大模型的运营成本中,电费占到了总成本的 50% 以上。
国际能源署今年发布的报告中预测,未来三年全球对数据中心、加密货币和人工智能的电力需求将增加一倍以上,相当于一个德国的全部电力需求。
“我在一年多前就预测过芯片短缺,下一个短缺的将是电力。我认为明年将没有足够的电力来运行所有的芯片。”前段时间马斯克发出了这样的预警。
OpenAI 首席执行官山姆·奥特曼也表示,人工智能将消耗比人们预期更多的电力。
如果说算力是大模型的底层支撑,那电力就是算力的底层支持。能否获得更清洁、稳定的能源,以及 AI 设备能否做到效率更高、更省电,影响着 AI 发展的可持续性。
02
除了耗电,AI 对资源也有着大量消耗。
比如对水资源的消耗。AI 芯片制造过程中涉及大量的清洗和化学处理步骤,生产一个智能手机芯片就需要大约消耗 5 吨多的水。而 AI 超算数据中心也需要大量水来散热,研究发现,单是使用 GPT-4 生成 100 字文本就需要消耗多达三瓶水。
有调研估算,到 2027 年,全球范围内的 AI 需求可能需要消耗掉 66 亿立方米的水资源,相当于杭州西湖水量的 450 多倍。
还有矿产资源,任何高科技的起点都是能源和矿产。
从网络路由器到电池再到数据中心,AI 系统扩展网络中的每一部分都需要矿产资源。
现代生活的很多方面都被转移到了“云端”,但人们很少考虑这些原材料的成本。我们的工作、生活、闲暇娱乐大部分都发生在网络计算架构的世界,而由云计算联通的我们拿在手中的设备,其内核为锂。
可充电锂离子电池是移动设备、笔记本电脑、家用数字助理和数据中心备用电源的必需品。它们支持着互联网和互联网上运行的几乎所有商业平台。
除此之外,还有很多不可再生的矿物质参与到了 AI 和其他高科技发展中,包括用于 iPhone 扬声器和电动汽车电机的稀土元素镝和钕,用于士兵的红外军事设备和无人机的锗,可以提高锂离子电池性能的钴。
参与世界科技竞争的国家都会根据自身工业要求和对供应风险的战略评估,制定自己的关键矿物清单。
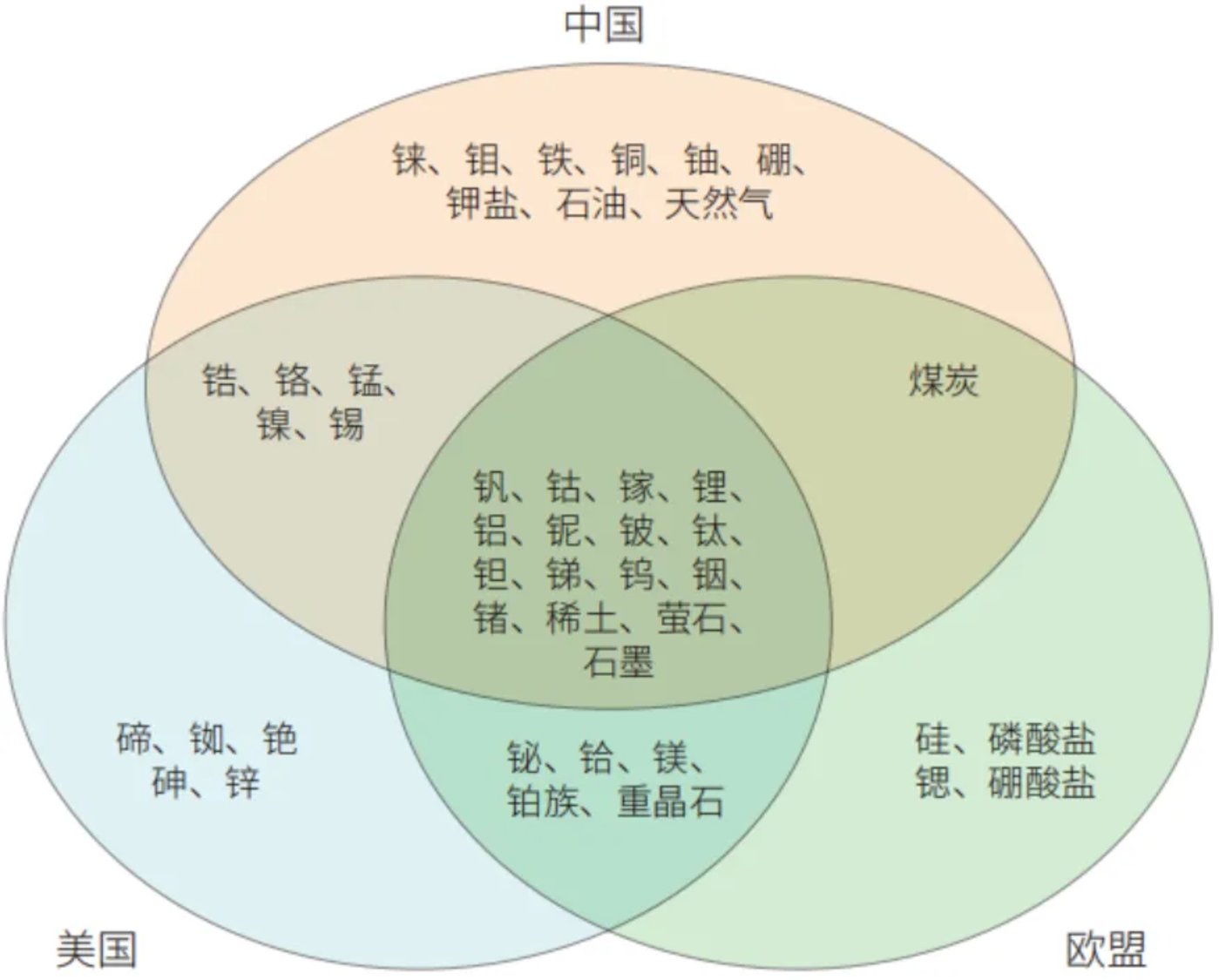
中国、美国、欧盟战略性关键矿产(图源:国际合作中心网站)
锂、锗、钴、稀土、石墨等都位列其中,是发展新能源汽车、人工智能、云计算、光伏、信息通信等高科技不可或缺的。
像稀土,里面包含 17 种金属元素,16 种被用在了智能手机里,这些元素可以在彩色显示屏、扬声器、相机镜头、可充电电池、硬盘驱动器和其他许多组件中找到。
如果无法保证这些矿物的供应,包括 AI 在内的科技行业都将陷入停滞。这是技术发展最重要的约束条件。
很多矿产都分布于世界上比较偏僻或者经济不发达地区,像玻利维亚西南部的乌尤尼盐沼、刚果中部、蒙古国、印度尼西亚。而采矿历来都是一件极易引发地缘政治冲突和战争的事情。
但包括 AI 在内的高科技发展给我们带来了“诗与远方”,很容易让我们忽略构成技术“肉身”的这些原材料,背后的稀缺,以及由此带来的冲突、饥饿和贫穷。
正如“锂电池之父”古迪纳夫所担忧的那样:“锂的重要性不亚于石油等战略性资源,一旦开采出现瓶颈,可能会跟石油一样成为战争的导火索。”
这样看来,高科技几乎也可以看作是一种资源密集型的提取技术,把不可再生的矿产、水等转化一些虚拟能力,期间还伴随着环境破坏和地缘冲突。
而且,这种巨大的资源密集型基础设施几乎完全是私人的。
03
AI 发展不仅存在能源和资源“饥渴”,还存在数据“饥渴”。
数据、算法和算力是 AI 大模型的三大支柱,而数据是大模型进行训练的根基。数据集塑造了 AI 的认知边界,它们决定了 AI“看”世界的界限。
比如,创建计算机视觉系统的第一步,通常是从网上抓取成千上万甚至数百万张图像,然后建立一系列分类体系来对它们进行排序,并以此作为系统感知可观察事实的基础。
如果想构建一个可以检测苹果和橙子图片之间差异的机器学习系统,首先开发人员必须收集和标记数以千计的苹果和橙子的图像,并基于此训练神经网络。在软件方面,算法会对图像进行统计调查,并开发一个模型来识别两个“类别”之间的差异。
如果一切按计划进行,经过训练的模型将能够区分它以前从未遇到过的苹果和橙子图像之间的差异。
但如果所有苹果的训练图像都是红色的,而没有一个是绿色的,那机器学习系统可能会推断“所有苹果都是红色的”。青苹果完全不会被识别为苹果。
因此,训练数据集是大多数机器学习系统进行推理的核心。它们是 AI 系统用来生成预测基础的主要原材料。
现在网络上每天有不可胜数的文本、图片、音视频被上传,AI 参与者就开始了数据掠夺。
科技巨头在其中占据了优势地位,像腾讯、字节、Meta 等掌握着各自的数据渠道,分享内容的人越多,他们能用来训练大模型的力量就越大。人们很乐意免费为他们的照片贴上姓名和地点的标签,而这种无偿劳动为机器视觉和语言模型系统带来了更准确的标记数据。
没有这些数据渠道的企业就要为此付一大笔费用或者想其他办法得到。
OpenAI 就曾被报道其在未得到创作者授权情况下,使用 Whisper 语音识别工具,转录了超过一百万小时的 YouTube 视频内容,并将这些数据用于训练其 GPT-4 模型。
但数据,尤其是高质量的数据并非取之不尽的。根据去年 Epoch AI 人工智能预测组织的一项研究,AI 公司可能在 2026 年前耗尽高质量文本训练数据,而低质量文本和图像数据的枯竭时间可能介于 2030 年至 2060 年之间。
山姆·奥特曼曾认为 AI 最后应当可以产生高品质的“人造资料”,以便高效地进行自我培训。
但很多研究者认为,AI 产生的数据质量太差,再用这样的数据“喂”自己就是“自我投毒”。
对高质量数据的饥渴催生了“AI 录音员”“大数据标注师”“AI 编辑”等众包工作。
之前就有媒体报道,在一些一二线城市,互联网大厂正以每次 300 元的价格,招募“AI 录音员”。他们的任务是为大模型提供定制化的语音数据,通过录制长达 3 小时的对话,帮助 AI 更好地理解和学习人类语言。
这 300 元不是那么好挣的,需要提供有充足剧情、严格符合规范的高质量内容,可能需要多次重复一些内容以符合要求。
事实上,AI 的一个常被忽视的重大事实就是需要数量巨大的低薪工人帮助开发、维护和测试 AI 系统。比如 AI 录音员,还有给数千小时的培训数据做标记,审查可疑或有害的内容。但他们从未因为使这个 AI 系统正常运行而获得认可。
此外,像亚马逊的物流系统,即便配备了大量机器人来做诸如搬箱子这样的重活,但也需要人来配合完成机器人做不了的特殊、精细的工作,比如机器人识别不了的奇形怪状的东西。
人去配合机器人,就要不断适应机器人,还要按照机器的节奏,很难运用自己已有的知识或形成工作惯性。
这显示出了 AI 发展初期人的改造,把人的劳动和价值之间进行脱节,从而更好地配合机器,也更容易被替代。
而 AI 大多数训练集是在人们不知情或未经当事人同意的情况下构建的,像家里的智能音箱、口袋里的手机、智能手表、监控记录下的面部表情等,会不会也被拿来作为数据训练 AI?
机器学习模型需要持续的数据流才能变得更加准确。但机器只能渐近,永远不会达到完全精准,这进一步推动算法从尽可能多的人身上提取信息,来为人工智能提供“燃料”。人类主体性被进一步消解。
04
写下这么多并不是“反技术”,恰恰相反,技术给人类带来了诸多便利,创造了更多可能性,使人类摆脱了诸多生存和发展难题。
但技术背后是一个涉及能源、资源、人、社会、历史等各方面的系统性问题。
正如社会学家凯特·克劳福德在其所著《技术之外:社会联结中的人工智能》中认为,人工智能既是具身的,也是物质的,由自然资源、燃料、人力、基础设施、物流、历史和分类构成,这些都是需要付出代价的。
但很明显,当下人们更多追求技术的军备竞赛和技术狂欢,而忽略了技术之外的一系列问题。
尤瓦尔·赫拉利在《今日简史》里说,19 世纪工业革命兴起之后,当时的社会、经济和政治模式都无法应对相关的新情况和新问题。封建主义、君主制和传统宗教不适合管理工业大都市、几百万背井离乡的工人,并面对现代经济不断变化的本质。
狄更斯笔下的煤矿童工、第一次世界大战和 1932—1933 年的乌克兰大饥荒,都只是人类付出昂贵学费的一小部分。
现代文明有核武器及各种更高级的技术,破坏力也更惊人,我们只能比面对工业革命时做得更好才行。
人类的行进既充满智慧,又是盲目的。做任何事都有代价,或许最优的结果是效果和代价匹配,而非不计代价地奔向目标。






