几十万人关注,一发表即被行业大佬评为“这是很长时间以来最重要的论文”。
哈佛、斯坦福、MIT 等团队的一项研究表明:训练的 token 越多,需要的精度就越高。
例如,Llama-3 在不同数据量下(圆形 8B、三角形 70B、星星 405B),随着数据集大小的增加,计算最优的精度也会增加。
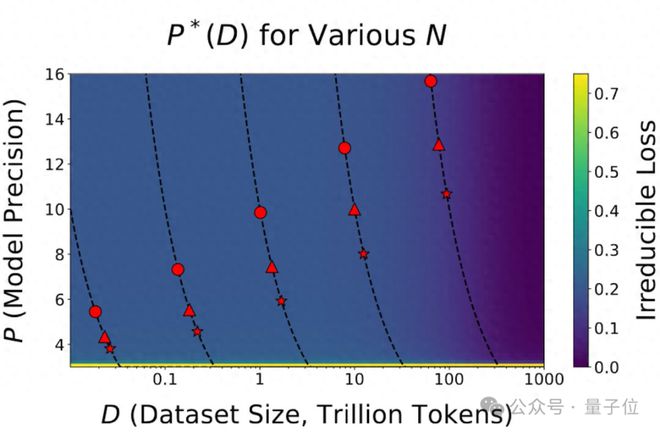
换句话就是,对于大规模的训练任务,低精度的量化可能不再足够有效。
按照结论,对 Scaling Law 的遵循意味着我们需要保持更高精度,然而一直以来,人们通常会选择量化(将连续值或多精度值转换为较低精度)来节省计算资源。
一旦结论成立,GPU 的设计和功能可能也需要相应调整,因为传统上,GPU 的性能提升部分依赖于对低精度计算的优化。
正如艾伦 AI 研究所科学家所指出的:这是很长时间以来最重要的论文。它用强有力的证据表明,我们正在达到量化的极限。论文得出的结论对整个领域以及 GPU 的未来有着广泛的影响。

与此同时,研究得出了两个重要结论:
- 如果量化是在后训练阶段进行的,那么更多的预训练数据最终可能反而有害
- 在高(BF16)和下一代(FP4)精度下进行预训练可能都是次优的设计选择;
这也引来 OpenAI 员工大赞特赞:将非常酷地看到如何 SOTA 量化方案(mxfp,Pw≠Pkv≠Pa 等)推动前沿;在我看来,将一半的计算预算用于一次大规模运行以检查模型是否适用于大模型是值得的。

提出“精度感知”Scaling Laws
一上来,研究就指出,当前扩展的焦点主要放在了模型规模、数据量上,忽视了对精度的关注。
而事实上,随着模型进一步应用落地,低精度量化正在成为新的范式。
- 深度学习正朝着更低精度的方向发展。
-
当前的前沿模型(如 Llama-3 系列)在 BF16 中进行训练,并且大家都在努力将预训练范式转移到 FP8,甚至下一代硬件将支持 FP4;
因此,研究想要搞清:
- 精度、参数和数据之间的权衡是什么?它们在预训练和推理方面如何比较?
具体而言,团队研究了在预训练和后训练 ,随着数据和参数的变化,精度对损失的影响如何变化。
同时,为了精确测量相关变化,团队专门提出了“精度感知(precision-aware)”的 Scaling Laws,以预测和优化不同精度下的语言模型训练和推理。

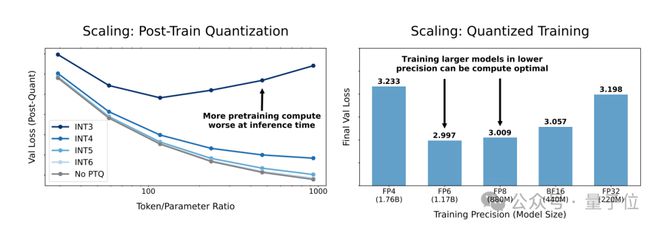
先说结论。下图展示了两个主要的实验结果:
- 在较低精度下训练模型(例如 INT3 和 INT4)会导致较高的损失;
- 在推理时使用较低精度会导致性能下降;
具体而言,左侧图表展示了在不同精度下训练模型的效果。
其中纵轴表示最终的验证损失(Val Loss),横轴表示不同的模型规模(Model Size),从 30M 到 220M 参数。不同的颜色代表了不同的训练精度,从 INT3 到 INT6,以及没有后训练量化(No PTQ)。
研究发现,在较低精度下训练模型(例如 INT3 和 INT4)会导致较高的损失,而随着精度的提高,损失会减少;同时,随着模型规模的增加,损失也会减少。
另外,右侧图表展示了在不同精度下进行推理时的模型性能。
其中横轴表示了推理时的权重精度(Final Val Loss)。
结果显示,在推理时使用较低精度(例如 INT3 和 INT4)会导致性能下降,即损失的增加;而随着精度的提高,损失会逐渐减少,接近没有进行后训练量化的模型性能。
上述发现也解释了为什么 Llama-3 难以量化?
要知道,Llama-3 发布后,它因“超 15T Token 数据上的超大规模预训练”而闻名,不过人们后来发现,Llama-3 低比特量化性能下降显著。
这可能正如研究提到的,模型在预训练阶段看到的数据越多,对量化的敏感性就越高。
与此同时,研究还发现了:
- 后训练量化(PTQ,即训练完成后对模型进行量化)引起的性能退化随着模型训练数据量的增加而增加。
换句话说,在大量数据上训练的模型,如果在推理时进行低精度的 PTQ,可能会导致性能显著下降。

接下来,团队提出利用“精度感知”Scaling Laws 来预测模型在不同精度下的性能,并指出:
- 在较低精度下进行训练可以减少模型的“有效参数数量(effective parameter count)”,从而预测在低精度下训练和后训练量化产生的额外损失。
其中包含两个关键公式,它们构成了一个统一的理论框架,用于预测不同精度下训练和推理的性能。
训练后量化(PTQ)引起的损失退化预测公式:

考虑训练精度的模型损失预测公式:

统一预训练与后训练的精度预测
BTW,研究最终将后训练量化和预训练量化的影响统一起来,以此实现:
- 预测在任何精度组合下的预训练和后训练损失
相关公式如下:

同时,为了验证预测的准确性,研究对超过 465 次预训练运行的数据进行拟合,并在高达 1.7 亿参数、训练了高达 260 亿个 token 的模型上进行了验证。
并在过程中提出了以下几点建议:
- 需要衡量精度与性能,在资源有限的情况下,可以考虑使用较低的精度来训练更大的模型;
- 需要衡量精度与参数,在低精度下训练时,可以考虑增加模型的规模(即参数数量),因为研究表明这样做可能是计算上最优的;
- 需要优化数据量,通过数据增强、选择性数据采样等技术提高数据使用率,并在预训练时应避免使用过多的数据,特别是在模型需要后期量化的情况下。
不过,这项研究目前也存在一定局限性,比如作者自述使用了一个固定的模型架构来控制变量。
这意味着,相关结果可能不适用于经过架构调整的低精度训练模型,因为架构的变化可能会影响模型对精度变化的敏感性。

最后,有网友还想得更远。提出一旦量化失败,还有 3 条路可以考虑:
- 扩展数据中心
- 转向更小的专业模型
- 知识蒸馏

你怎么看?






