
新智元报道
编辑:Aeneas 好困
Ilya 终于承认,自己关于 Scaling 的说法错了!现在训练模型已经不是「越大越好」,而是找出 Scaling 的对象究竟应该是什么。他自曝,SSI 在用全新方法扩展预训练。而各方巨头改变训练范式后,英伟达 GPU 的垄断地位或许也要打破了。
昨天,The Information 爆料,传统的大模型 Scaling Law 已经撞墙,OpenAI 下一代旗舰 Orion 遭遇瓶颈。

就在刚刚,路透社也发文表示,由于当前方法受到限制,OpenAI 和其他公司正在寻求通向更智能 AI 的新途径。

有趣的是,昨天拱火的 The Information,今天又急忙发出一篇文章来灭火。
他们强调,昨天的文章只是在说改进大模型必须找到新方法,并不是说 Scaling Law 已经终结。

但一个不争的事实就是:硅谷几大主要 AI 实验室正在陷入困境。训练这些大规模的 LLM 动辄需要花费数千万美元,但复杂系统还经常崩溃。往往需要数月时间,才知道模型能否按预期工作。
比起 GPT-4o,Orion 几乎没有任何改进;谷歌的 Gemini 2.0,被曝也存在同样问题;Anthropic 据传也已暂停 Opus 3.5 模型的工作。

据悉,谷歌正准备在 12 月推出最新的 Gemini 2.0,它可能无法实现 DeepMind 创始人 Demis Hassabis 团队预期的显著性能改进,但会引入一些有趣的新功能
Anthropic 首席执行官 Dario Amodei 表示,「我们的目标是改变曲线,然后在某个时候成为 Opus 3.5」
而离职创业的 OpenAI 元老 Ilya Sutskever 则表示,现在重要的是「扩大正确的规模」。
「2010 年代是 scaling 的时代,现在,我们再次回到了奇迹和发现的时代。每个人都在寻找下一个奇迹。」
对经营着自己的 AI 实验室 SSI 的 Ilya 来说,这是一个很大的改变。
曾经在推动 OpenAI 的 GPT 模型时,他的准则是「越大越好」。但在 SSI 的最近一轮融资中,Ilya 开始希望尝试一种与 OpenAI 不同的 Scaling 方法。
Scaling Law 大家都说得够多了。但有一个问题,却被每个人都忽略了——我们说 scaling 的时候,究竟在 scaling 什么?
如今,Ilya 抛出了这个振聋发聩的疑问。
Scaling 正确的东西,比以往任何时候都更重要
毕竟,超大规模语言模型的 ROI 实在太低了。
虽然在 GPT-4 发布后,各大 AI 实验室的研究人员都竞相追赶,发布了超过 GPT-4 的大模型,但他们更多的感觉是失望。
因为要同时运行数百个芯片,这种超大参数模型的训练可能要花费数千万美元,系统太复杂还可能会出现硬件故障。但只有经过数月,等到运行结束后,研究人员才能知道模型的最终性能。
另一个问题,就是 LLM 吞噬了大量数据,而世界上易于获取的数据,几乎已经被耗尽了!
同时,由于过程中需要大量能源,电力短缺也成为训练 AI 的严重阻碍。
论文题目:「The Unseen AI Disruptions for Power Grids: LLM-Induced Transients」
替代 Scaling 的新方法,Ilya 已经有了?
面对这种种现状,Ilya 最近在路透社的采访中表示,扩展训练的结果,已经趋于平稳。
也就是说,用大量未标记数据来理解语言模式和结构的训练阶段到头了。
以前,Ilya 是暴力 scaling 的早期倡导者之一,那时有一种想法广泛认为,通过在预训练中使用更多的数据和算力,能让 AI 模型的性能暴涨。
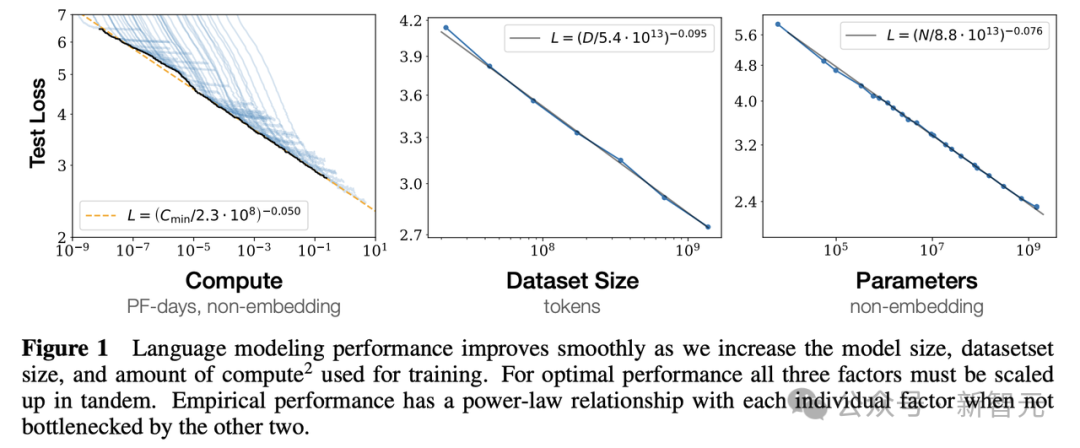
OpenAI 团队 2020 年提交的 arXiv 论文中最先提出这一概念:LLM 性能与计算量、参数量、数据量三者呈现幂律关系
的确,沿着这条路线,最终 ChatGPT 诞生了。
ChatGPT 发布后,从 AI 热潮中受益颇多的科技公司都公开声称,这种通过增加数据和算力来「scale up」的方法,能显著改善模型性能。
可是现在,Scaling Law 已经碰壁了!越来越多的 AI 科学家,对于这种「越大越好」(bigger is better)的哲学产生了质疑。
2010 年代属于 Scaling,但大模型要继续发展下去,需要一个新的奇迹。
Ilya 的 SSI 团队是否找到了呢?
对此,Ilya 拒绝透露,只是表示,SSI 正在研究一种全新的替代方法,来扩展预训练。

再领先三步?OpenAI 破局新方法:测试时计算
同时,OpenAI 仿佛也找到了新方法——通过开发使用更类人思维的算法训练技术,或许就能克服在追求更大规模 LLM 过程中遇到的意外延迟和挑战。
已经有十几位 AI 科学家、研究人员和投资者告诉路透社,他们认为正是这些技术,推动了 OpenAI 最近发布的 o1 模型。
而它们,可能会重塑 AI 竞赛的格局,让 AI 公司们不再对能源和芯片资源产生无限制的需求。
有没有这么一种新方法,让 AI 模型既能摆脱对数据的依赖,又不再需要动辄吞噬整个国家乃至全球的电力?
为了克服这些挑战,研究人员正在探索一项「测试时计算」的技术。
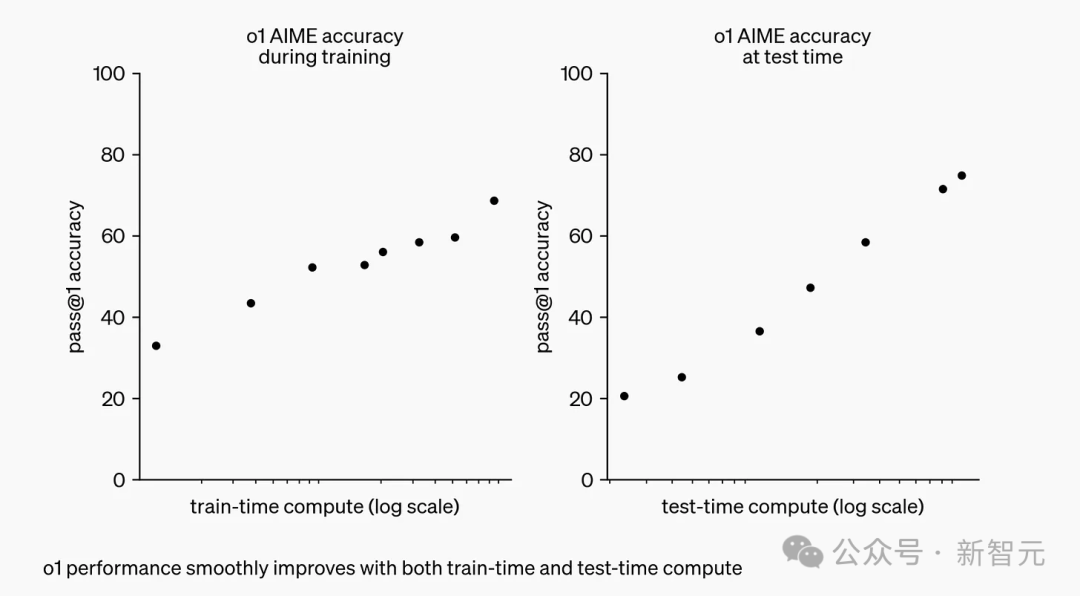
上图即是 OpenAI 解释 o1 的博文,x轴标记为「训练时计算」和「测试时计算」。
左图是 OpenAI 发现的 Scaling Law,意味着在模型上投入更多训练时间(GPU 周期)时,我们可以获得更好的结果。
右图则暗示了我们尚未触及的一套全新的 Scaling Law。「测试时计算」意味着,给模型更多的「思考时间」(GPU 周期)时,它会思考出更好的结果。
测试时计算技术,能在推理阶段(模型被使用时)就将模型增强,比如,模型可以实时生成和评估多种可能性,而不是理解选择单一答案。最终,模型就可以选择出最佳路径。
这种方法可以允许模型将更多的处理能力,用于数学、编码问题等具有挑战性的任务,或者需要类人推理和决策的复杂操作。

传统的 Scaling Law,专注于用更长时间训练大模型,但如今 o1 系列模型 scaling 有了两个维度——训练时间和测试(推理)时间
早在上个月的旧金山 TED AI 会议上,曾参与 o1 开发的 OpenAI 研究员 Noam Brown 就提出——
事实证明,让一个机器人在一局扑克中思考仅 20 秒,其性能提升与将模型规模扩大 10 万倍并训练 10 万倍时间相同。
o1 模型以前曾被称为「Q*」和「Strawberry」。现在,它能够以多步骤方法思考问题,类似于人类推理。

现在,模型不再受限于预训练阶段,还可以通过增加推理计算资源,来提升表现
而且,它还涉及了来自博士和行业专家策划的数据和反馈。
o1 系列的秘密武器,是在 GPT-4 等基础模型上进行的另一套训练,OpenAI 还计划,将这种技术应用于更多更大的基础模型。
OpenAI 的首席产品官 Kevin Well 在十月的一次科技会议表示——
我们看到很多可以快速改进这些模型的机会,而且非常简单。到人们赶上来的时候,我们会尝试再领先三步。
通过思维链提示,o1 模型可以经过训练生成长长的输出,并通过答案进行推理
全球顶尖 AI 实验室开卷,英伟达垄断地位有望打破?
OpenAI 说要领先三步,其他顶尖 AI 实验室岂甘落后?
据知情人士透露,来自 Anthropic、xAI 和谷歌 DeepMind 的研究人员,也已经奋力开卷了!
比如 Meta 最近提出了「思维偏好优化」TPO,这种方法旨在教会 LLM 在回答一般任务(而不仅仅是数学或逻辑问题)之前「思考」,而不需要特殊的训练数据。

论文地址:https://arxiv.org/pdf/2410.10630
而谷歌也在开发一种新模型,同样使用 CoT 方法解决多步骤问题、生成多个答案,评估后选择最佳答案。
这个过程同样可以通过在推理中使用更多算力来增强,而非仅仅增加训练数据和算力,这就为扩展 AI 模型开辟了一条新道路。

论文地址:https://arxiv.org/pdf/2408.03314
这会导致什么后果?
很有可能,对英伟达 GPU 巨大需求主导的 AI 硬件竞争格局,将从此改变。
这是因为,通过增加训练时间和测试(推理)时间,可能会获得更好的结果,模型就不再需要那么大的参数。
而训练和运行较小模型会更便宜,因此,在给定固定计算量的情况下,我们可能会突然从小模型中获得更多收益。
突然之间,模型参数、训练时间和测试时间计算之间的关系变得复杂了,也就让我们看到了下一代 GPU 的可能。
比如 Groq 这样的公司,恰巧就在为这类任务制造专门的芯片。
今年 2 月登场的世界最快大模型 Groq,每秒 500 token 直接破了纪录,自研的 LPU 在 LLM 任务上比英伟达 GPU 性能快了 10 倍。

红杉资本和 A16z 在内的著名风投机构,如今已经投入了数十亿美元,资助 OpenAI、xAI 等多家 AI 实验室的开发。
他们不可能不注意到最近圈内盛传的 Scaling Law 碰壁事件,而重新考虑自己的昂贵投资是否会打水漂。
红杉资本合伙人 Sonya Huang 表示,这种转变,将使我们从大规模预训练集群转向推理云,即分布式的、基于云的推理服务器。
大模型热以来,对英伟达尖端 AI 芯片的需求,已经让它崛起为全球最有价值的公司,并且市值超越了苹果。
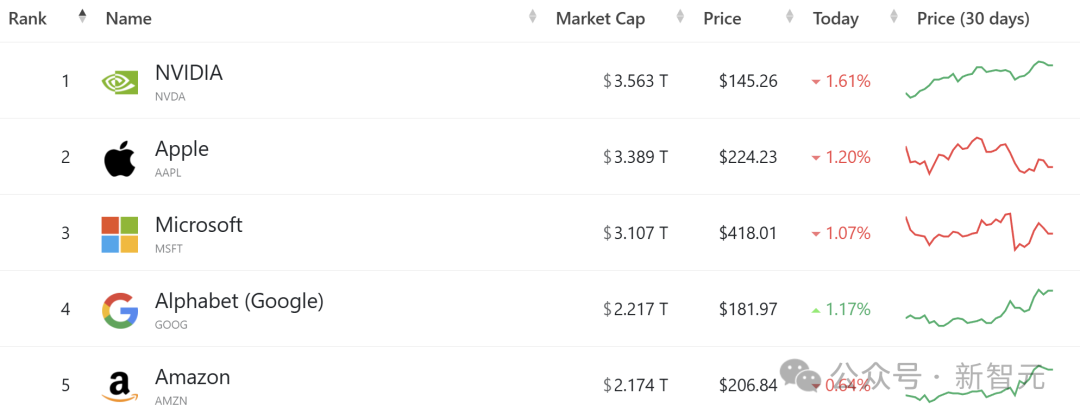
今年以来,英伟达股价上涨了约 186%,而苹果仅上涨了 17%
虽然在训练芯片的市场,英伟达已经占据主导地位,但它在推理市场,可能还会面临更多竞争。
而 o1 模型背后的技术,意味着对推理芯片的需求也会随着增加。
「我们现在发现了第二个 Scaling Law,这是在推理阶段的 Scaling Law……所有这些因素导致对 Blackwell 的需求非常高。」

在英伟达 GTC 大会上,黄仁勋也讲到,如果要训练一个 1.8 万亿参数量的 GPT 模型,需要 8000 张 H100 GPU,消耗 15 兆瓦的电力,连续跑上 90 天
随着 Scaling Law 碰壁,各大公司纷纷开启新路线,英伟达是否还会继续坐火箭般的辉煌呢?
再见,GPT。你好,推理「o」
The Information 今天的解释文章,标题意味深长:《再见,GPT。你好,推理「o」》。
文章内容是这样的。
月初,一位 Reddit 用户曾在 QA 中问道,OpenAI 的下一代旗舰大语言模型何时发布。
对此,Altman 回答说:「今年晚些时候,我们会发布一些非常不错的产品,但并不会叫做 GPT-5。」随后他又补充道,有限的计算资源意味着很难同时推出过多的项目。
当时我们并未多想。
但如今,我们更能理解 Altman 的评论了——以及他为何专注于推出o系列推理模型,而非另一版本的 GPT 。
所谓 GPT,即生成式预训练 Transformer 模型,是 ChatGPT 和大多数其他生成式人工智能产品的基石。
原因正如之前报道的那样,GPT 的改进速度正在放缓。
2023 年初登场的上一代旗舰级模型 GPT-4,凭借着巨大的性能提升在科技行业引发了轰动。
Orion 比 GPT-4 更好,但其质量提升与 GPT-3 和 GPT-4 之间的差距相比略显逊色。甚至,可能会让 OpenAI 放弃自 2018 年推出 GPT-1 起使用的「GPT」命名惯例。
因此,当 Altman 写道「o1 及其后续版本」时,可能意味着 Orion 将与推理融合并被命名为「o2」。
随着一种 Scaling Law 的消退,另一种定律取而代之
让我们回到 GPT 发展放缓这个问题上。
传统的 Scaling Law 不仅仅意味着在大语言模型训练过程中需要更多的数据和计算能力才能获得更好的结果。OpenAI 的研究人员还做了各种其他有趣的事情,才使得 GPT-4 比 GPT-3 有了大幅提升。比如,引入被称为模型稀疏性的概念。
随着推理范式的出现,预训练改进的放缓便可以得到弥补——从本质上讲,它可能代表了一种新的 Scaling Law。
OpenAI 一再表示,推理模型的性能在回答问题前有更多时间思考时会变得更好,这被称为对数线性计算扩展。
那么,这些变化是否意味着 OpenAI 的 1000 亿美元超级计算集群的梦想正在消退呢?对于这个问题,可以肯定的是,所有主流的 AI 开发者都在全速推进极其昂贵的集群建设。
一方面是,大型集群上可以更好地在预训练后改进这些模型、在后训练阶段处理强化学习以及更新或微调模型。
另一方面是,即便预训练模型的改进速度放缓,但只要自己能训出比竞争对手略好的模型,就值得增加数据中心投入。毕竟,LLM 越好,将推理模型融入模型后获得的结果就越好。
最后,如果 GPT 的发展没有加速,是不是就意味着末日论者错了——AI 不会进入所谓的递归自我改进循环,在这个循环中,AI 会一次又一次地找出如何制造下一个更好版本的自己(然后也许会征服我们所有人)?
对此,Marc Andreessen 认为,这种明显的平台期,意味着这样的恐惧目前看来是没有根据的。






