
新智元报道
编辑:乔杨
70 年前科学家们所畅想的「机器常识」被 LLM 实现了吗?Nature 最近的一篇评论文章给出了否定的答案,并坚定地指出:常识推理是 AGI 的必备品。
自从 2022 年 ChatGPT 横空出世以来,LLM 进入了一日千里、突飞猛进的发展阶段。
一些专家和研究人员推测,这些模型的问世,代表着我们向「通用人工智能」(AGI)的实现迈出了决定性的一步,从而完成了人工智能 (AI) 研究 70 年来的探索。
这一历程中的一个重要里程碑之一,就是机器能够展现出「常识」。
对人类来说,「常识」是关于人和日常生活的「显而易见的事情」。比如,我们可以从经验中知道,玻璃是易碎的,或者给吃素的朋友端上来一盘肉是不礼貌的。
然而,在「常识」这一点上,即使是当今最先进、最强大的 LLM 也常常达不到要求。

一名机器人艺术家在 2022 年英国 Glastonbury 音乐节上为表演者作画
LLM 非常善于在涉及记忆的测试中取得高分,比如 GPT-4 最为人称道的成绩之一,就是可以通过美国的医生和律师执业考试,但依旧很容易被简单的谜题搞迷糊。
如果你问 ChatGPT「Riley 很痛苦,之后她会感觉如何?」,它会从很多个选项中挑出「觉察」(aware)作为最佳答案,而不是对人类来说显而易见的「痛苦」(painful)。
为了弥补这方面的缺陷,很多这类的选择题都被纳入到流行的基准测试中,用于用于衡量 AI 对常识的掌握。
然而,这些问题很少能够真正反映现实世界,包括人类对物理定律的直觉理解,以及社交互动中的背景和语境。因此,要量化出 LLM 的「类人」程度仍然是一个尚未解决的问题。
相比于 AI,我们可以发现人类认知的一些不同之处。
首先,人类善于处理不确定和模糊的情况,会满足于一个「令人满意但未必最佳」的答案,很少消耗大量的认知资源去执着于找到最佳的解决方案。
其次,人类可以在「直觉推理」和「深思熟虑」的模式之间灵活切换,从而更好地应对小概率的突发情况。
AI 能否实现类似的认知能力?我们又如何如何确切地知道 AI 系统是否正在获得这种能力?
这就不仅仅是 AI 或计算机科学的问题,还需要涉足发展心理学、认知哲学等学科,同时我们也需要对人类认知过程的生物基础有更深入的了解,才能设计更好的指标来评估 LLM 的表现。
AI 发展出常识,从何时开始?
机器常识的研究,还是要追溯到深度学习领域不得不提的一个时间点——1956 年,新罕布什尔州达特茅斯的那场暑期研讨会。
这场会议将当时顶尖的 AI 研究人员聚集在了一起,随后就诞生了基于逻辑的符号框架,使用字母或逻辑运算符来描述对象和概念之间的关系,用于构建有关时间、事件和物理世界的常识知识。
例如,一系列「如果发生……,那么就会发生……」的语句可以被手动编程到机器中,用于教会一个常识性事实,比如不受支持力的物体会因为重力而下落。
这类研究确立了机器常识的愿景,即构建能够像人类一样有效地从经验中学习的计算机程序。
从技术角度定义,这个目标就是制造一台机器,在给定一组规则的情况下,「根据已知内容和信息,自行推断出范围足够广泛的直接结果」 。

在加州举行的机器人挑战赛中,一个人形机器人向后摔倒
因此,机器常识不仅限于有效学习,还包括自我反思和抽象等能力。
从本质上讲,常识需要事实知识,也需要利用知识进行推理的能力。仅仅是记住大量事实是不够的,从现有信息中推断出新信息同样重要,这样才能在新的或不确定的情况下做出决策。
20 世纪 80 年代时,研究人员开始进行早期尝试,希望赋予机器以常识和决策能力,主要的手段是创建结构化的知识数据库,例如 CYC、ConceptNet 等项目。
CYC 这个名字的灵感来源于「百科全书」(encyclopedia),不仅包含了事物间的关系,还尝试使用关系符号来整合上下文相关的知识。
因此,凭借 CYC,机器能够区分事实知识(例如「美国第一任总统是乔治·华盛顿」)和常识知识(例如「椅子是用来坐的」)。
ConceptNet 项目有类似的原理,同样是将关系逻辑映射到一个由三元词组构成的庞大网络(例如「苹果」—「用来」—「吃」)。
然而,无论是 CYC,还是 ConceptNet,都不具备推理能力。
常识推理的挑战性在于模糊性,因为在提供更多信息后,情况或问题就会变得很难确定。
比如,想要回答「Lina 和 Michael 正在节食,他们来做客时我们要准备蛋糕吗?」这个问题,如果添加了另一个事实「他们有 cheat days」,答案就会变得相对复杂且难以抉择。
基于符号和规则的逻辑无法处理这种模糊性,甚至依靠概率生成下一个 token 的 LLM 也无济于事,因为引入关于「cheat days」的额外信息不仅会降低确定性,还会完全改变语境。
AI 系统如何应对这种未见的、不确定的情况,将直接决定机器常识进化的速度,我们要做的,就是开发出更好的评估方法来跟踪相关进展,但「衡量常识」这个任务并没有看起来这么容易。
LLM 有常识吗?这很难评
目前评估 AI 系统常识推理能力的 80 多项著名测试中,至少 75% 是多项选择测验。然而,从统计的角度来看,这样的测验最多也只能给出模棱两可的结果。
向 LLM 提出一个相关领域的问题,并不能揭示模型是否拥有更广泛的事实知识,因为 LLM 在响应特定查询时,并不会以统计学上有意义的方式从知识库中进行采样。
比如,即使向 LLM 提出两个非常相似的问题,也可能会得到截然不同的答案。
对于不涉及多项选择题的测试,比如为图像生成合适标题,也很难完全探测到模型的多步骤和常识性推理能力。
不涉及多项选择测验的测试(例如,为图像生成适当的图像标题)不会完全探测模型显示灵活、多步骤、常识性推理的能力。
因此, 机器常识相关的测试方案和方法仍需要发展,从而更清楚地区分「知识」和「推理」。
有一种方法可以用于改进当前测试,就是要求 AI 解释给出当前答案的理由。例如,一杯咖啡放在室外会变凉,这是常识,但其中的推理过程涉及热传递、热平衡等物理概念。
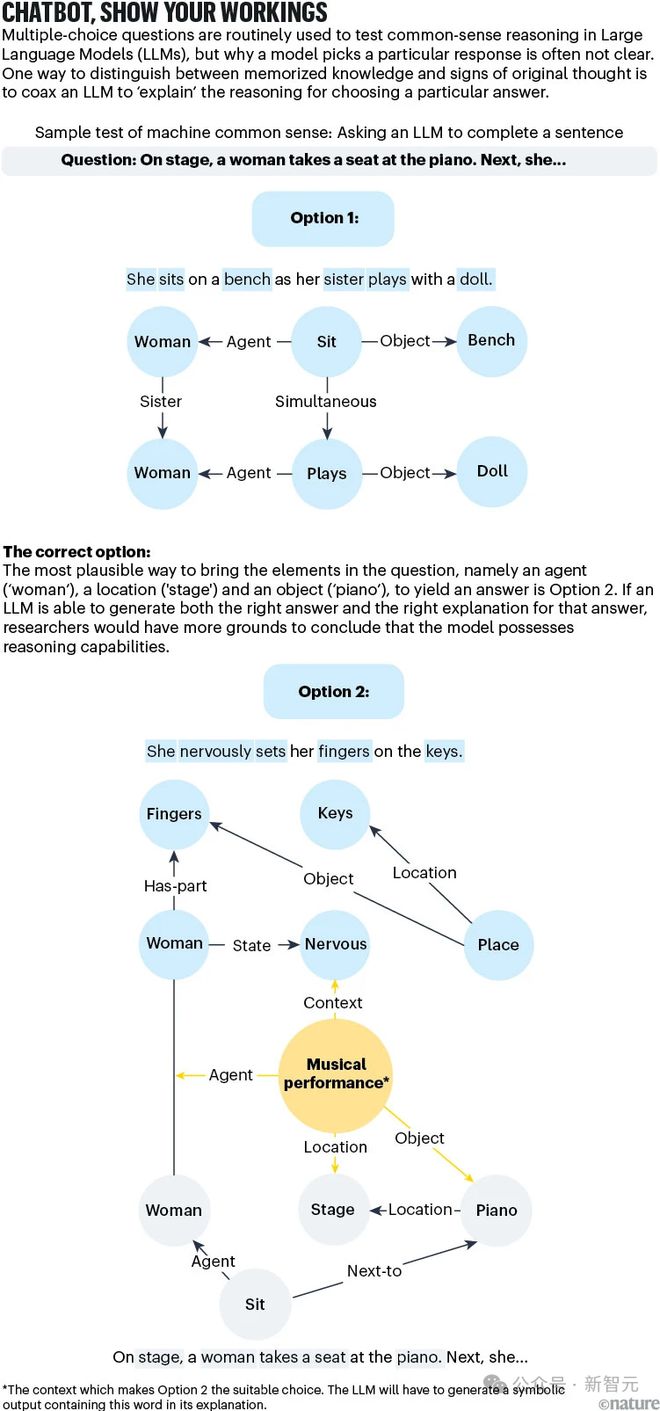
尽管 LLM 可能会生成正确的答案(「因为热量逸散到周围的空气中」),但基于逻辑的响应将需要逐步的推理过程来解释原因。
如果 LLM 能够使用 CYC 项目开创的那种符号语言来复现出正确的原因揭示,我们就更有理由认为,模型不仅仅是通过参考训练语料来查找答案,而是确实发展出了常识推理能力。
另一类开放式测试,就是考察 LLM 的计划或战略规划能力。
想象一个简单的游戏:能量令牌随机分布在棋盘上,玩家需要在棋盘上移动 20 次,收集尽可能多的能量并将其放到指定的地方。
在这类游戏中,人类不一定能找到最佳解决方案,但常识推理足以支持我们拿到合理的分数。那 LLM 呢?
研究人员进行测试后发现,模型的表现远远低于人类。
从 LLM 的行为来看,它似乎理解了游戏规则:它可以棋盘上移动,有时也能找到能量令牌并收集起来,但会犯各种看似愚蠢的错误,比如将能量令牌丢在错误的位置。
鉴于 LLM 会犯这种有常识的人都不会犯的错误,因此我们很难期待这种模型在解决更混乱的现实规划问题时,能够有更出色的表现。
下一步怎么走
为了系统地奠定机器常识的基础,可以考虑采取以下步骤:
「把盘子做大」
研究人员需要超越单纯的 AI 或计算机科学领域的经验,涉足认知科学、哲学和心理学等学科,找出关于人类如何学习、如何应用常识的关键原理。
这些原则应该能够指导我们,创建能够进行类人推理的 AI 系统。
拥抱理论
与此同时,研究人员需要设计全面的、理论驱动的基准测试,反映广泛的常识推理技能,例如理解物理特性、社交互动和因果关系。
这些基准测试的目标,必须是量化 AI 系统跨领域概括常识知识的能力,而不是专注于一组狭窄的任务 。
超越语言的思考
夸大 LLM 能力的风险之一就是夸大了语言的重要性,这会让我们与另一个重要愿景脱节——构建能在混乱现实环境中感知、导航的具身系统。
DeepMind 联合创始人 Mustafa Suleyman 就认为,实现「有能力」的 AI(capable)可能是比 AGI 更切实可行的里程碑。
至少在人类基本水平上,如果要构建具有物理能力的人工智能,具体化的机器常识是十分必要的。然而,目前的 AI 似乎仍处于获取幼儿水平身体智力的早期阶段。
令人欣喜的是,研究人员开始在以上所有方面取得了进展,但仍有很长的路要走。
随着人工智能系统,尤其是 LLM 成为各种应用的主要内容,理解人类推理的能力将在医疗保健、法律决策、客服和自动驾驶等领域产生更可靠和值得信赖的结果。
例如,具有社交常识的客服机器人将能够推断出用户的沮丧情绪,即使没有明确的表达出来。
从长远来看,也许机器常识领域的最大贡献,将是让人类更深入地了解自己。
参考资料:






