白小交西小风发自凹非寺
量子位公众号 QbitAI
刚刚,EMNLP 2024最佳论文奖新鲜出炉!
5 篇中榜论文中,华人学者参与三篇,分别来自 CMU、上海交通大学、中国科学院大学等机构。

其中,Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method主要由中科院网络数据科学与技术重点实验、中国科学院大学的学者完成。
论文一作 Weichao Zhang;通讯作者郭嘉丰,现任中科院网络数据科学与技术重点实验室常务副主任。
这项研究提出了一个新的数据集和方法,用于检测给定文本是否为 LLM 预训练数据的一部分,有助于提高 LLM 训练数据透明度。

EMNLP’24 今年收录论文总共2978 篇,比去年增长5%,其中 2455 篇主会议论文,523 篇 workshop 论文。

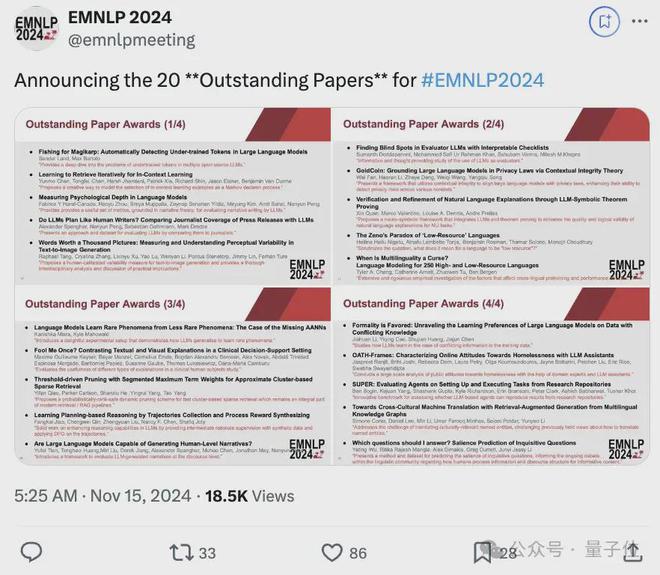
除最佳论文外,杰出论文也揭晓了,超半数华人学者参与。
顺便提一嘴,EMNLP 2025 将于明年 11 月5-9 日,在中国苏州举办!
国内学者们可以搓搓手准备起来了~
接下来,具体康康获奖论文有哪些~
上交大 CMU 等团队获最佳论文
此次共有 5 项研究成果获得 EMNLP’24 最佳论文奖。
1、An image speaks a thousand words, but can everyone listen? On image transcreation for cultural relevance
(图像能表达千言万语,但每个人都能倾听吗?关于图像再创造的文化相关性)

这篇来自 CMU 的论文研究了图像跨文化再创作任务。鉴于多媒体内容兴起,翻译需涵盖图像等模态,传统翻译局限于处理语音和文本中的语言,跨文化再创作应运而生。
作者构建了三个包含 SOTA 生成模型的管道:e2e-instruct 直接编辑图像,cap-edit 通过字幕和 LLM 编辑后处理图像,cap-retrieve 利用编辑后的字幕检索图像,还创建了概念和应用两部分评估数据集。
结果发现,当前图像编辑模型均未能完成这项任务,但可以通过在循环中利用 LLM 和检索器来改进。
2、Towards Robust Speech Representation Learning for Thousands of Languages
(为数千种语言实现稳健的语音表征学习)

这篇来自CMU、上海交大、丰田工业大学芝加哥分校的论文,介绍了一种名为 XEUS 的跨语言通用语音编码器,旨在处理多种语言和声学环境下的语音。
研究通过整合现有数据集和新收集的数据,构建了包含 4057 种语言、超 100 万小时数据的预训练语料库,并提出新的自监督任务(声学去混响)增强模型鲁棒性。研究结果显示,XEUS 在多个下游任务中表现优异,在 ML-SUPERB 基准测试中超越了其他模型,如在多语言自动语音识别任务中实现 SOTA,且在语音翻译、语音合成等任务中也表现出色。
该团队超半数都是华人,其中一作William Chen目前是 CMU 语言技术研究所的硕士生,此前获得佛罗里达大学计算机科学和历史学学士学位。

3、Backward Lens: Projecting Language Model Gradients into the Vocabulary Space
(逆向透镜:将语言模型梯度投射到词汇空间)

了解基于 Transformer 的语言模型如何学习和调用信息成为行业一个关键目标。最近的可解释性方法将前向传递获得的权重和隐藏状态投射到模型的词汇表中,有助于揭示信息如何在语言模型中流动。
来自以色列理工学院、特拉维夫大学的研究人员将这一方法扩展到语言模型的后向传递和梯度。
首先证明,梯度矩阵可以被视为前向传递和后向传递输入的低秩线性组合。然后,开发了将这些梯度投射到词汇项目中的方法,并探索了新信息如何存储在语言模型神经元中的机制。
4、Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method
(大语言模型的预训练数据检测:基于散度的校准方法)

这篇论文作者来自中科院网络数据科学与技术重点实验、中国科学院大学、中关村实验室、阿姆斯特丹大学。
通讯作者郭嘉丰,现为中国科学院计算技术研究所研究员、中国科学院大学教授、北京人工智能研究院研究员,中科院网络数据科学与技术重点实验室主任。目前研究方向是信息检索(Neural IR)和自然语言理解的神经模型。

他们的研究旨在解决大语言模型预训练数据检测问题,因模型开发者不愿透露训练数据细节,现有方法在判断文本是否为训练数据时存在局限。
基于这样的原因,他们提出 DC-PDD 方法,通过计算文本的词元概率分布与词元频率分布的交叉熵(即散度)来校准词元概率,从而判断文本是否在模型预训练数据中。实验在 WikiMIA、BookMIA 和新构建的中文基准 PatentMIA 上进行,结果显示 DC-PDD 在多数情况下优于基线方法,在不同模型和数据上表现更稳定。
5、CoGen: Learning from Feedback with Coupled Comprehension and Generation
(CoGen,结合理解和生成,从反馈中学习)

来自康奈尔大学的研究团队研究了语言理解和生成能力的耦合,提出在与用户交互中结合两者以提升性能的方法。
具体通过参考游戏场景,部署模型与人类交互,收集反馈信号用于训练。采用联合推理和数据共享策略,如将理解数据点转换为生成数据点。
实验结果显示,耦合方法使模型性能大幅提升,理解准确率提高 19.48%,生成准确率提高 26.07%,且数据效率更高。在语言方面,耦合系统的有效词汇增加,与人类语言更相似,词汇漂移减少。
杰出论文
再来看看杰出论文的获奖情况,此次共有 20 篇论文上榜。
GoldCoin: Grounding Large Language Models in Privacy Laws via Contextual Integrity Theory,香港科技大学研究团队完成,论文共同一作 Wei Fan、Haoran Li。
团队提出了一个新框架,基于情境完整性理论来调整大语言模型使其符合隐私法律,提高其在不同情境下检测隐私风险的能力。

Formality is Favored: Unraveling the Learning Preferences of Large Language Models on Data with Conflicting Knowledge,南京大学团队完成,论文共同一作 Jiahuan Li、Yiqing Cao。
论文研究了大语言模型在训练数据中存在冲突信息时的学习倾向。

科技巨头获奖团队有微软,Learning to Retrieve Iteratively for In-Context Learning提出了一种创造性的方法,模拟上下文学习示例的选择作为马尔可夫决策过程。

Towards Cross-Cultural Machine Translation with Retrieval-Augmented Generation from Multilingual Knowledge Graphs,由 Adobe、苹果与罗马大学研究人员联合完成。
论文探讨并挑战了在跨文化机器翻译中翻译文化相关命名实体的传统方法。

此外值得一提的是,华人学者、加州大学洛杉矶分校计算机科学系副教授Nanyun Peng团队这次赢麻了,她参与/指导的三篇论文都获奖了。
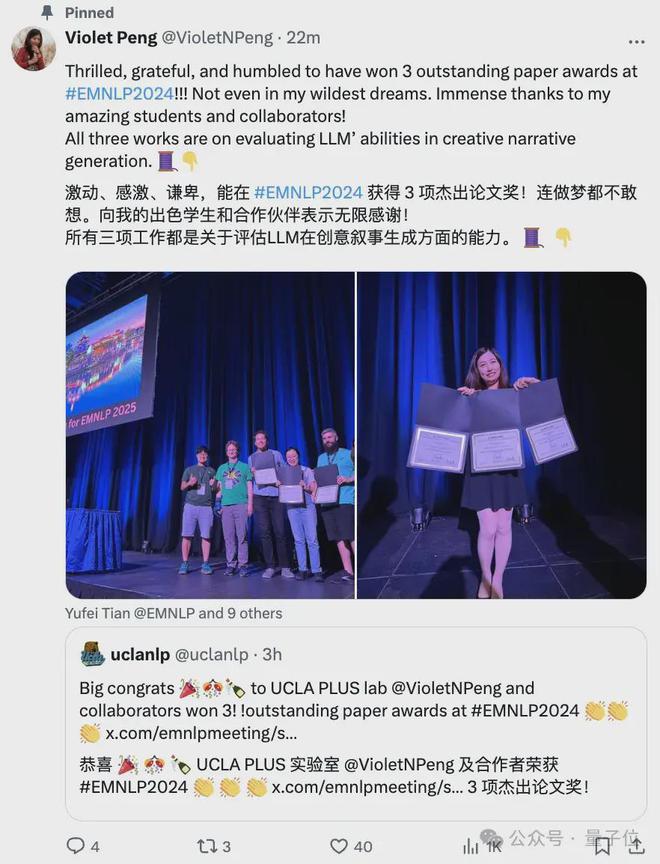
三项工作都是关于评估 LLM 在创意叙事生成方面的能力,分别为:
- Measuring Psychological Depth in Language Models(测量语言模型中的心理深度)
- Do LLMs Plan Like Human Writers? Comparing Journalist Coverage of Press Releases with LLMs(大语言模型能像人类作家一样规划吗?通过与记者对新闻稿的报道比较来评估)
- Are Large Language Models Capable of Generating Human-Level Narratives?(大语言模型能生成人类水平的叙述吗?)
以下是完整获奖名单:




最佳论文链接:
[1]https://arxiv.org/abs/2404.01247
[2]https://arxiv.org/abs/2407.00837
[3]https://arxiv.org/abs/2402.12865
[4]https://arxiv.org/abs/2409.14781
[5]https://www.arxiv.org/abs/2408.15992
参考链接:
[1]https://x.com/emnlpmeeting/status/1857176170074460260?s=46






