允中发自凹非寺
量子位公众号 QbitAI
自回归文生图,迎来新王者——新开源模型 Infinity,字节商业化技术团队出品,超越 Diffusion Model。

值得一提的是,这其实是从前段时间斩获 NeurIPS 最佳论文VAR衍生而来的文生图版本。

在预测下一级分辨率的基础上,Infinity 用更加细粒度的 bitwise tokenizer 建模图像空间。同时他们将词表扩展到无穷大,增大了 Image tokenizer 的表示空间,大大提高了自回归文生图的上限。他们还将模型大小扩展到 20B。
结果,不仅在图像生成质量上直接击败了 Stable Diffusion3,在推理速度上,它完全继承了 VAR 的速度优势,2B 模型上比同尺寸 SD3 快了 3 倍,比 Flux dev 快 14 倍,8B 模型上比同尺寸的 SD3.5 快了 7 倍。

目前模型和代码都已开源,也提供了体验网站。
来看看具体细节。
自回归文生图新王者
在过去自回归模型和扩散模型的对比中,自回归模型广受诟病的问题是生成图像的画质不高,缺乏高频细节。
在这一背景下,Infinity 生成的图像细节非常丰富,还能够生成各种长宽比图像,解掉了大家过去一直疑虑的 VAR 不支持动态分辨率的问题。
具体性能上面,作为纯粹的离散自回归文生图模型,Infinity 在一众自回归方法中一鸣惊人,远远超过了 HART、LlamaGen、Emu3 等方法。
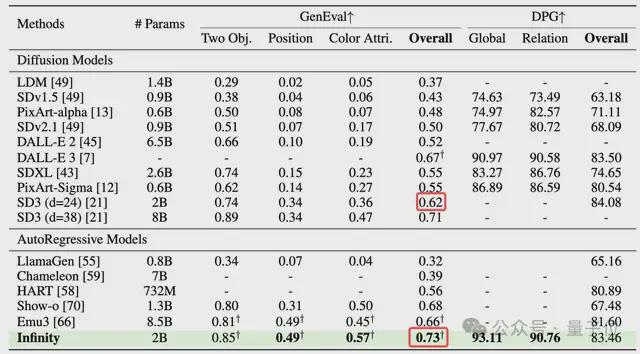
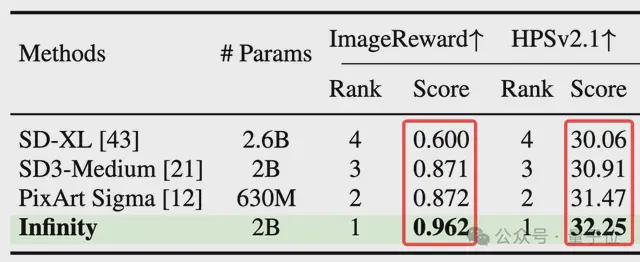
与此同时,Infinity 也超过了 SDXL,Stable diffusion3 等 Diffusion 路线的 SOTA 方法。
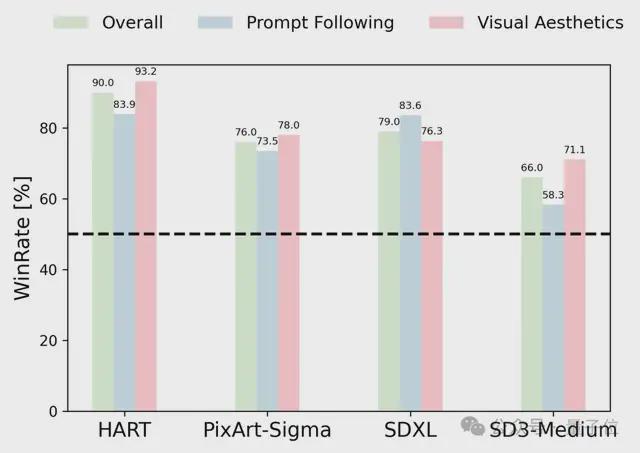
人类评测上,用户从画面整体、指令遵循、美感三个方面对于 Infinity 生成图像和 HART、PixArt-Sigma、SD-XL、SD3-Meidum 生成图像进行了双盲对比。
其中 HART 是一个同样基于 VAR 架构,融合了 diffusion 和自回归的方法。PixArt-Sigma、SD-XL、SD3-Meidum 是 SOTA 的扩散模型。
Infinity 以接近 90% 的 beat rate 击败了 HART 模型。显示了 Infinity 在自回归模型中的强势地位。
此外,Inifnity 以 75%、80%、65% 的 beat rate 击败了 SOTA 的扩散模型如 PixArt-Sigma、SD-XL、SD3-Meidum 等,证明了 Infinity 能够超过同尺寸的扩散模型。
那么,这背后具体是如何实现的?
Bitwise Token 自回归建模提升了模型的高频表示
大道至简,Infinity 的核心创新,就是提出了一个 Bitwise Token 的自回归框架——
抛弃原有的“Index-wise Token”,用 +1 或-1 构成的细粒度的“Bitwise Token”预测下一级分辨率。
在这个框架下,Infinity表现出很强的 scaling 特性,通过不断地scaling视觉编码器(Visual Tokenizer)和 transformer,获得更好的表现。
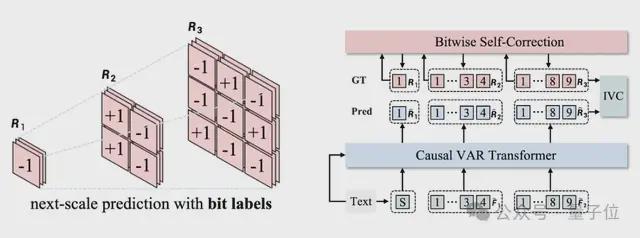
在 Bitwise Token 自回归框架中,关键技术是一个多尺度的比特粒度视觉编码器(Visual Tokenizer)。
它将H×W×3 大小的图像编码、量化为多尺度的特征:1×1×d,2×2×d,…,h×w×d。其中d是视觉编码器的维度,每一维是 +1 或-1。词表的大小是 2d。过去的方法中,会继续将d维的特征组合成一个 Index-wise Token(索引的范围是0~2d-1,用这个 Index-wise Token 作为标签进行多分类预测,总共类别是词表大小,即 2d。
Index-wise Token 存在模糊监督的问题。如下图所示,当量化前的连续特征发生微小扰动后(0.01 变成-0.1),Index-wise Token 的标签会发生剧烈变化(9 变成1),使得模型优化困难。
而 Bitwise Token 仅有一个比特标签发生翻转,其他比特标签仍能提供稳定监督。相比于 Index-wise Token,Bitwise Token 更容易优化。
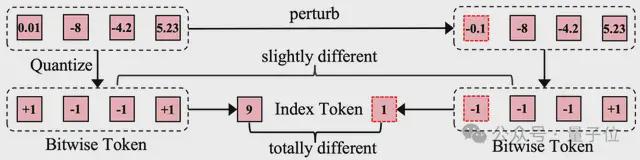
研究人员在相同的实验设置下对比了 Index-wise Token 和 Bitwise Token。
结果显示,预测 Bitwise Token 能够让模型学到更细粒度的高频信号,生成图像的细节更加丰富。

无穷大词表扩展了 Tokenizer 表示空间
从信息论的角度来看,扩散模型采用的连续 Visual Tokenizer 表示空间无穷大,而自回归模型采用的离散 Visual Tokenizer 表示空间有限。
这就导致了自回归采用的 Tokenizer 对于图像的压缩程度更高,对于高频细节的还原能力差。为了提升自回归文生图的上限,研究人员尝试扩大词表以提升 Visual Tokenizer 的效果。
但是基于 Index-wise Token 的自回归框架非常不适合扩大词表。基于 Index-wise Token 的自回归模型预测 Token 的方式如下图左边所示,模型参数量和词表大小正相关。
当d=32 的时候,词表大小为 232,预测 Index-wise Token 的 transformer 分类器需要有 2048×232=8.8×1012=8.8T 的参数量!
光一个分类器的参数量就达到了 50 个 GPT3 的参数量,这种情况下扩充词表到无穷大显然是不可能的。
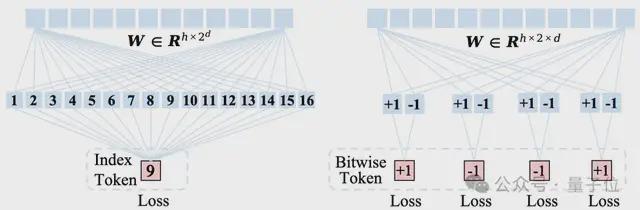
研究人员的解决方法简单粗暴,如上图右边所示,丢掉索引,直接预测比特!有了 Bitwise Token 自回归建模后,研究人员采用d个 +1 或-1 的二分类器,并行地预测下一级分辨率 +1 或-1 的比特标签。做出这样的改变后,参数量一下从 8.8T 降到了 0.13M。所以说,采用 Bitwise Token 建模自回归后,词表可以无限大了。
有了无限大词表,离散化的 Visual Tokenizer 落后于连续的问题似乎没有这么严重了:
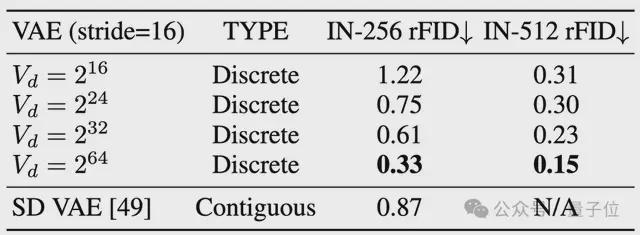
如上表所示,当词表大小放大到后,离散的视觉编码器在 ImageNet 上重建的 FID 居然超过了 Stable Diffusion 提出的连续的 VAE。

从可视化效果来看,无限大词表(Vd=232),相比于小词表,对于高频细节(如上图中的人物眼睛、手指)重建效果有质的提升
Model Scaling 稳步提升效果
解决了制约生成效果天花板的视觉编码器的问题后,研究人员开始了缩放词表和缩放模型的一系列实验。
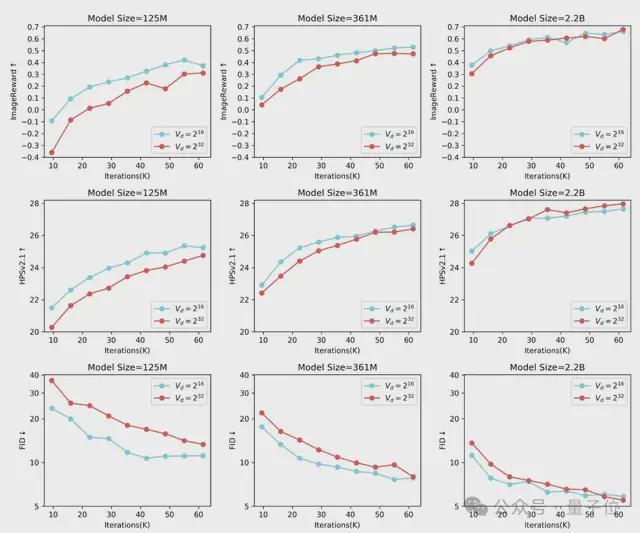
研究发现,对于 125M 的小模型,使用 Vd=216 的小词表,相比于 Vd=232 的大词表,收敛的更快更好。
但是随着模型的增大,大词表的优势逐渐体现出来。当模型增大到 2B 并且训练迭代超过 50K 以后,大词表取得了更好的效果。最终 Infinity 采取 Vd=232 的大词表,考虑到 232 已经超过了 int32 的数值范围,可以认为是无穷大的数,这也是 Infinity 的命名由来。
总结来看,(无穷)大词表加大模型,加上充分的训练后,效果要明显好于小词表加大模型。
除了 scaling 词表以外,研究人员还做了对 Infinity 模型大小的 scaling 实验。
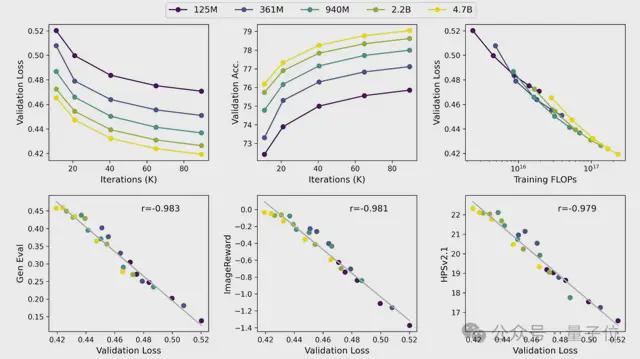
他们在完全相同的实验设定下比较了 125M、361M、940M、2.2B、4.7B 五个不同尺寸大小的模型。
可以看到,随着模型的增大和训练资源的增加,验证集损失稳步下降,验证集准确率稳定提升。另外,研究人员发现验证集 Loss 和各项测试指标存在很强的线性关系,线性相关系数高达 0.98。
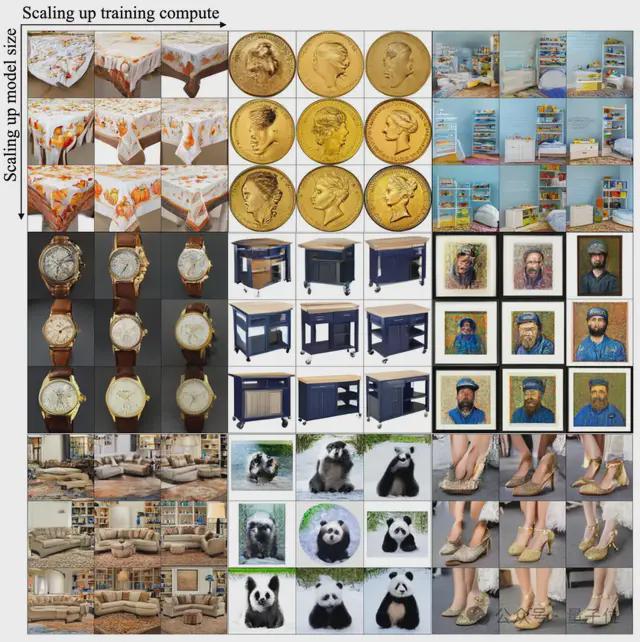
下图每个九宫格对应同一个提示词在不同模型大小、不同训练步数的生成图像。
- 从上往下分别是:逐渐增大模型规模,对应 125M、1B、5B 模型生成的图像。
- 从左往右分别是模型训练的步数逐渐增多后生成的图像。
我们能明显看出:Infinity 有着良好的 scaling 特性,更大的模型、更多的训练,能够生成语义结构、高频细节更好的图像。
另外 Infinity 还提出了比特自我矫正技术,让视觉自回归文生图模型具有了自我矫正的能力,缓解了自回归推理时的累计误差问题。

Infinity 还能够生成各种长宽比图像,解决了 VAR 不支持动态分辨率的问题。
下图列出了 Infinity 和其他文生图模型对比的例子。
可以看到,Infinity 在指令遵循,文本渲染、画面美感等方面都具有更好的表现。

除了效果以外,Infinity 完全继承了 VAR 预测下一级分辨率的速度优势,相比于扩散模型在推理速度上具有显著的优势。
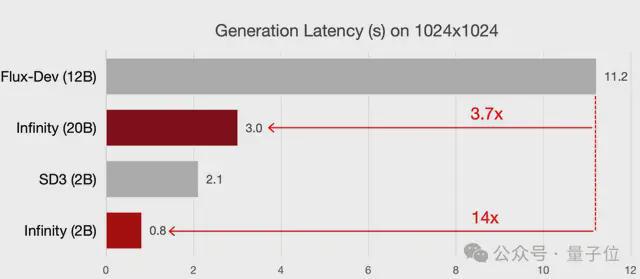
2B 模型生成 1024x1024 的图像用时仅为 0.8s,相比于同尺寸的 SD3-Medium 提升了 3 倍,相比于 12B 的 Flux Dev 提升了 14 倍。8B 模型比同尺寸的 SD3.5 快了 7 倍。20B 模型生成 1024x1024 的图像用时 3s,比 12B 的 Flux Dev 还是要快将近 4 倍。
目前,在 GitHub 仓库中,Infinity 的训练和推理代码、demo、模型权重均已上线。
Infinity 2B 和 20B 的模型都已经开放了网站体验,感兴趣的同学可以试一试效果。
开源地址:https://github.com/FoundationVision/Infinity






