
新智元报道
编辑:编辑部 HYZ
OpenAI 首个智能体 Operator,刚刚震撼登场。从此,AI 打破 API 局限,可以像人类一样直接和界面交互了。L3 级智能体达成,AGI 路上一大障碍又被扫清!
刚刚,OpenAI 首个智能体终于亮相了!
奥特曼带领团队毫无预警地开启半小时「Operator」在线直播,首次揭秘能像人类一样使用电脑的 AI。

Sam Altman,Yash Kumar,Casey Chu,Reiichiro Nakano
演示中,AI 智能体不仅可以精准理解指令,还能自主完成各类任务。
而它的独特之处在于,可以直接与网页交互——打字、点击、滚动,几乎一气呵成。
比如,自动填写繁琐的在线表单、上网购物、创建表情包、处理重复性浏览器任务等等。

「Operator」背后操盘手便是 Computer-Using Agent (CUA),打破了特定编程接口的局限,像人类一场直接与 GUI 进行交互。
从此,通往 AGI 道路上的又一大瓶颈被扫除。智能体可以在数字世界中四处行动了!
OpenAI 官博将此称为,AI 与数字世界的「通用界面」。

「Operator」究竟有多厉害?
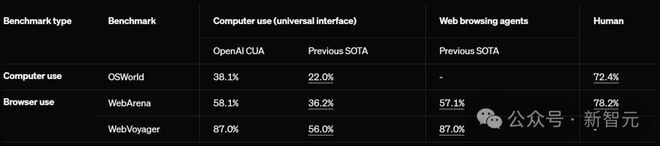
在多个测试环境中,CUA 成功率令人瞠目:在 OSWORLD 上完成计算机使用任务成功率高达 38.1%,比此前 SOTA 提升近 16%;在 WebArena 上完成浏览器使用任务成功率达到 58.1%,性能飙升 22%。
不过与人类(72.4% 和 78.2%)相较之下,AI 的能力还是有所差距。
在 WebVoyager 上,CUA 更是达到了惊人的 87%。

好消息是,「Operator」终于上线。而坏消息是,目前只有 Pro 美国用户才能体验。
为了弥补这一遗憾,奥特曼提前剧透了,o3-mini 直接在 ChatGPT 中「开源」,Plus 用户会有更多用量。
随着 Operator 的正式发布,总裁 Greg 也再一次强调,「2025 年,就是智能体之年」。

话不多说,直接上演示。
AI 接管 PC 订餐,但直播小翻车
我们可以在 Operator 中选择 OpenTable,让它订一张今晚 7 点在 Beretta 的两人位子。
可以看到,输入查询后,Operator 会实例化指令,创建在云端运行的浏览器操作。
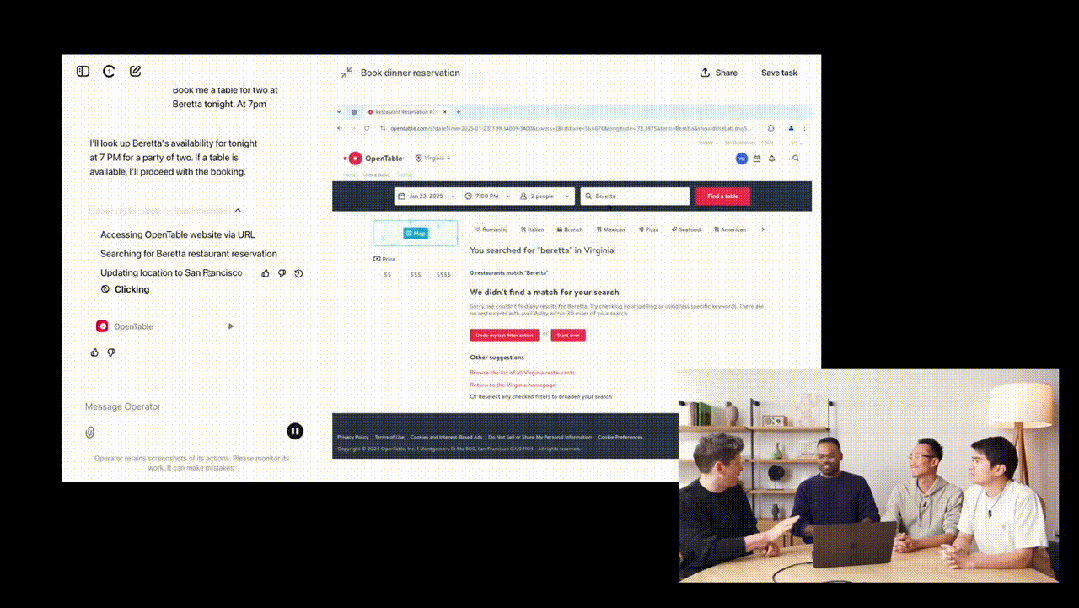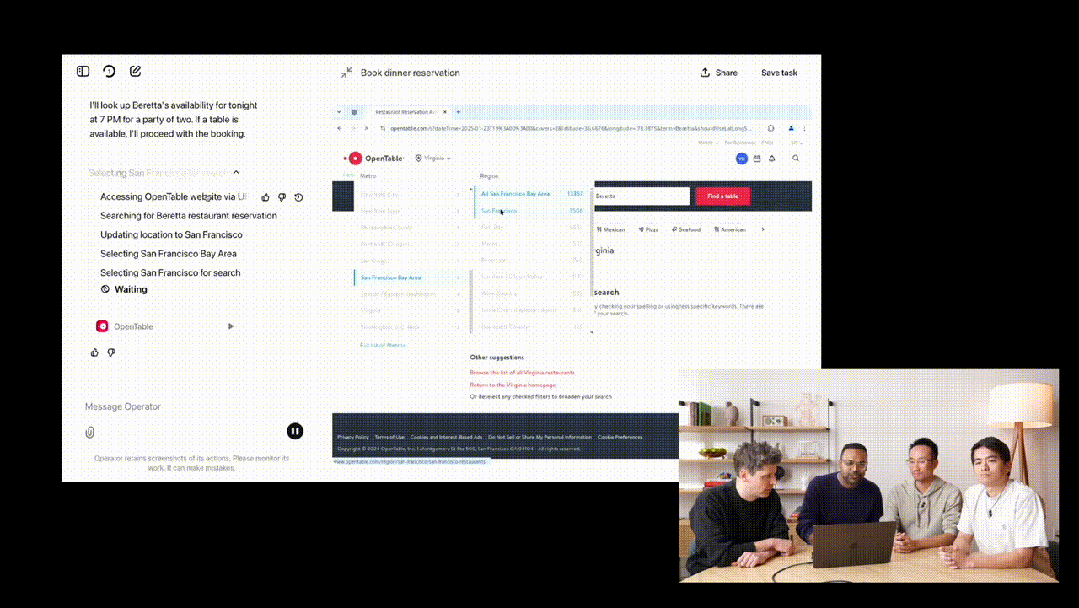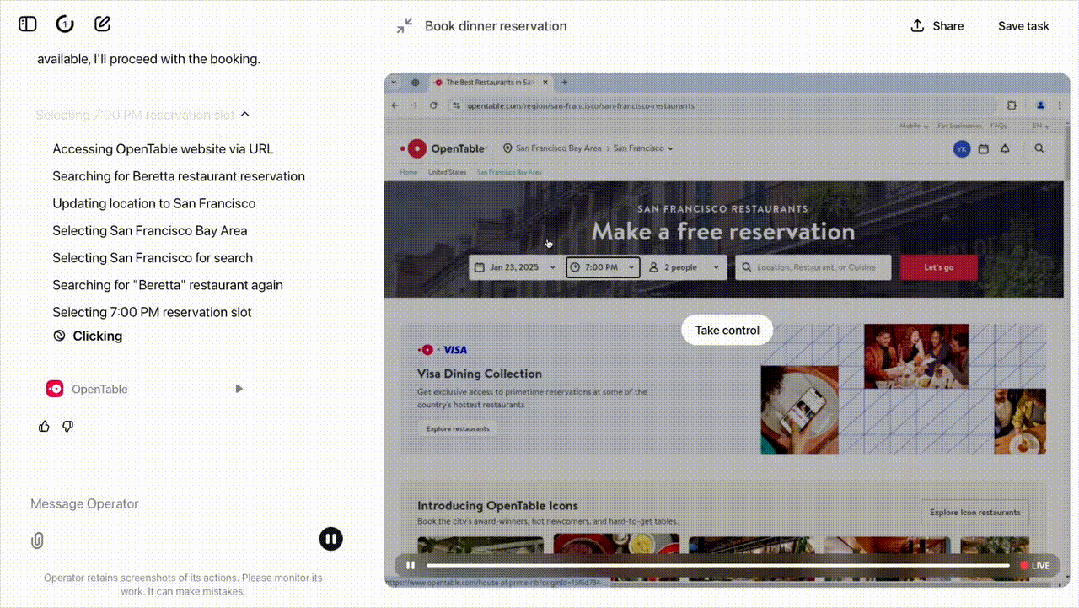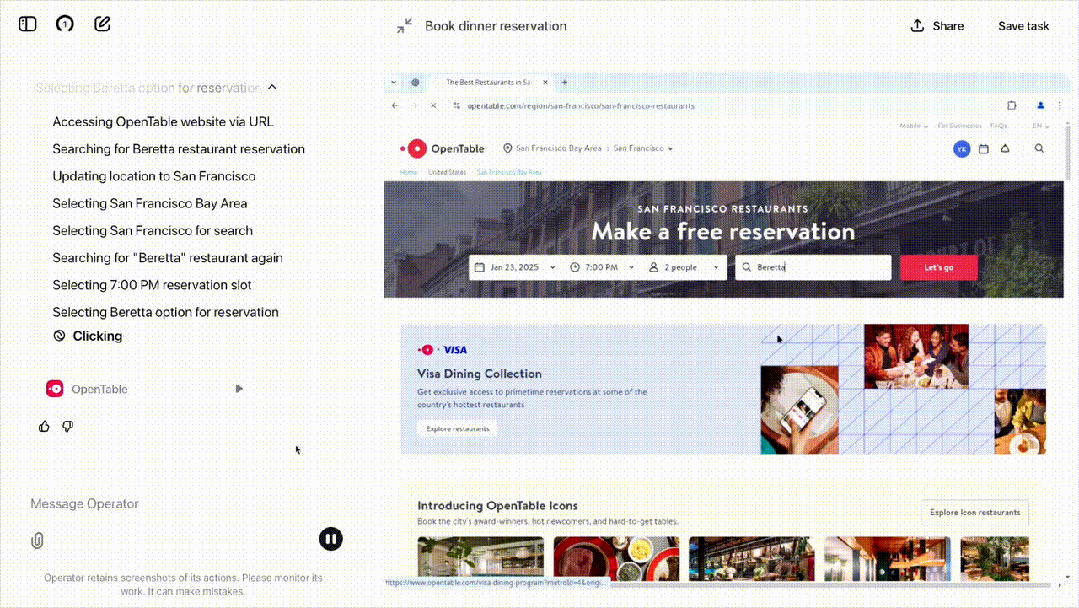
随后,Operator 转到了搜索 Beretta 的 URL。非常令人惊喜的是,OpenTable 默认的地址是弗吉尼亚,但它自动更正为旧金山。
再比如,我们做饭需要鸡蛋、菠菜、鸡大腿和辣椒。在纸上写下这些食材后,就可以直接传给 Operator,同时告诉他我们偏好的商店是 Gus。

在这种情况下,Operator 很快就根据 GPT-4o 的视觉功能理解了图中的意思,还明白 Gus 商店是哪里。
接下来,就像 OpenTable 一样,它实例化了一个浏览器,然后开始了购买环节。

如果在以前,如果我们想用智能体执行类似操作,就必须确定特定网站有 API,并且这个 API 有一切所需的功能,然而,大部分网站都是没有 API 的。
而 CUA 通过教模型使用我们日常使用的基本界面,它就解锁了一系列以前无法访问的软件!
可以看到,在执行操作的过程中,Operator 进行了一些内在独白,总结出了思维链。
而且每执行一个操作还会给电脑截个图,这样它就知道自己的操作对电脑有什么影响。
接下来,它点击搜索框,输入菠菜。这种采取行动、抓取屏幕截图、创建子计划的循环会一直持续,直到任务完成。

当然,人类也可以随时接过 Operator 的控制权,这就保证了用户随时可以控制 Operator,并向它发出指令。
有趣的是,人类接管之后,Operator 并不能看到我们在接管模式下做的事——这就保证了私密性。
接下来,OpenAI 的研究者给它下达了一项新任务:用 StubHub 买四张本周末旧金山勇士队比赛、票价 500 以下的门票。
非常真实的是,Operator 小翻车了一下。
那就让它试试,买明早圣玛丽澳网公开赛的门票。Operator 立马打开引擎,展开搜索。
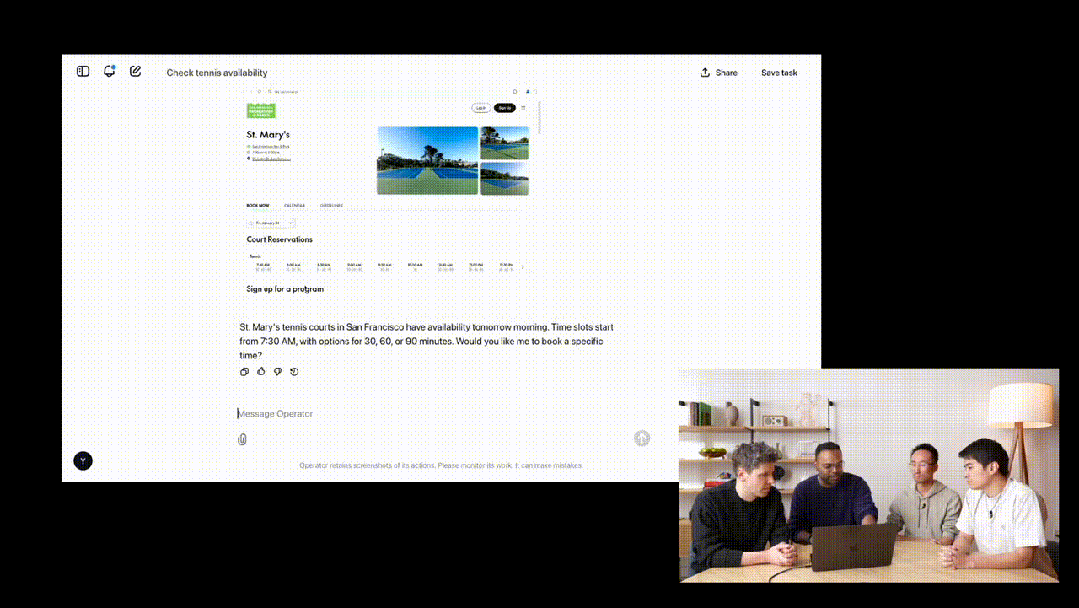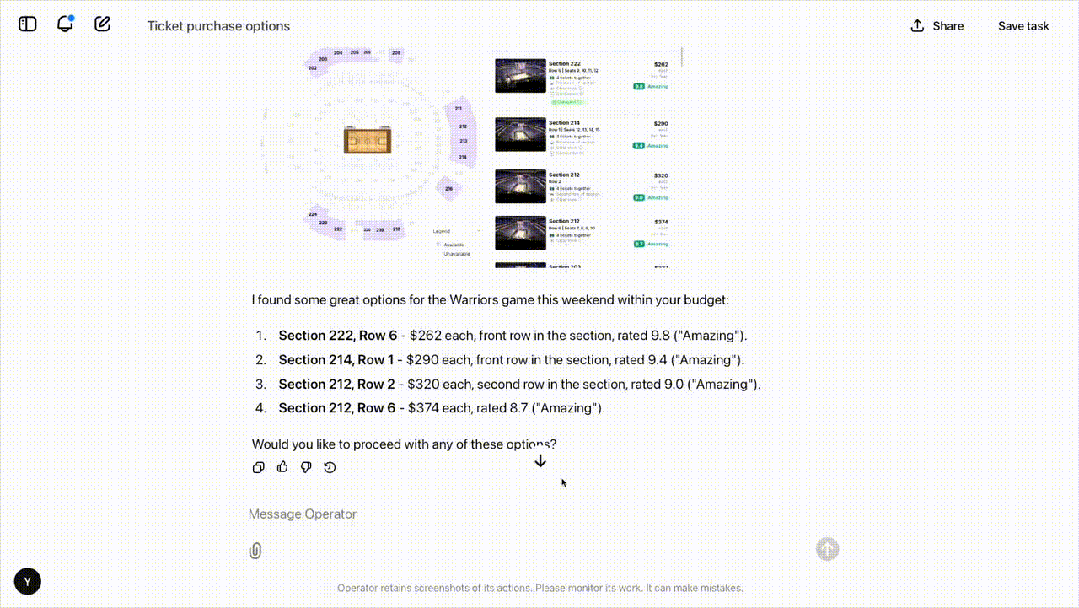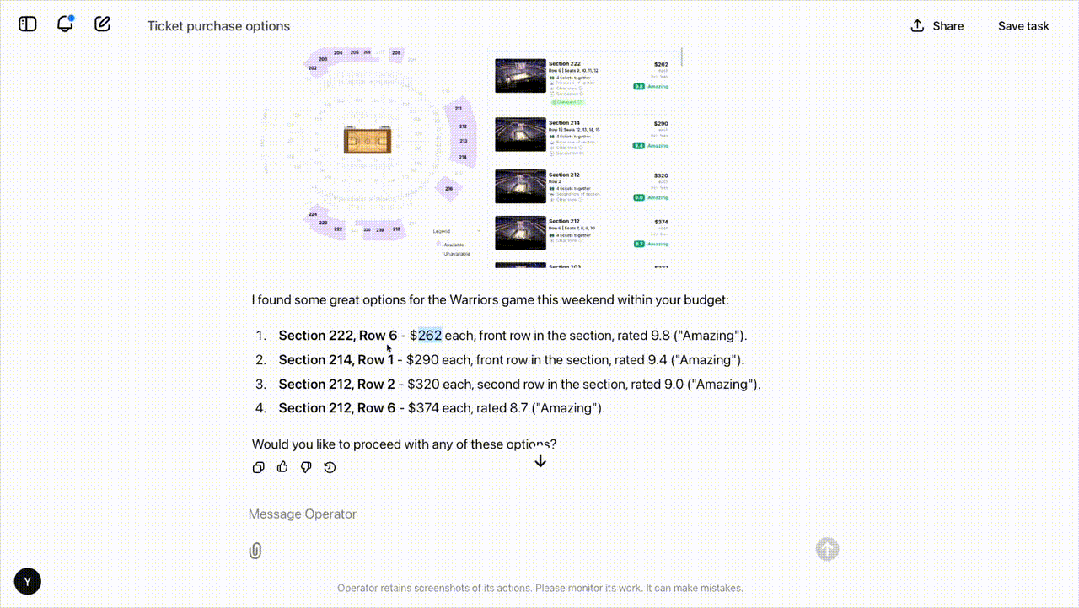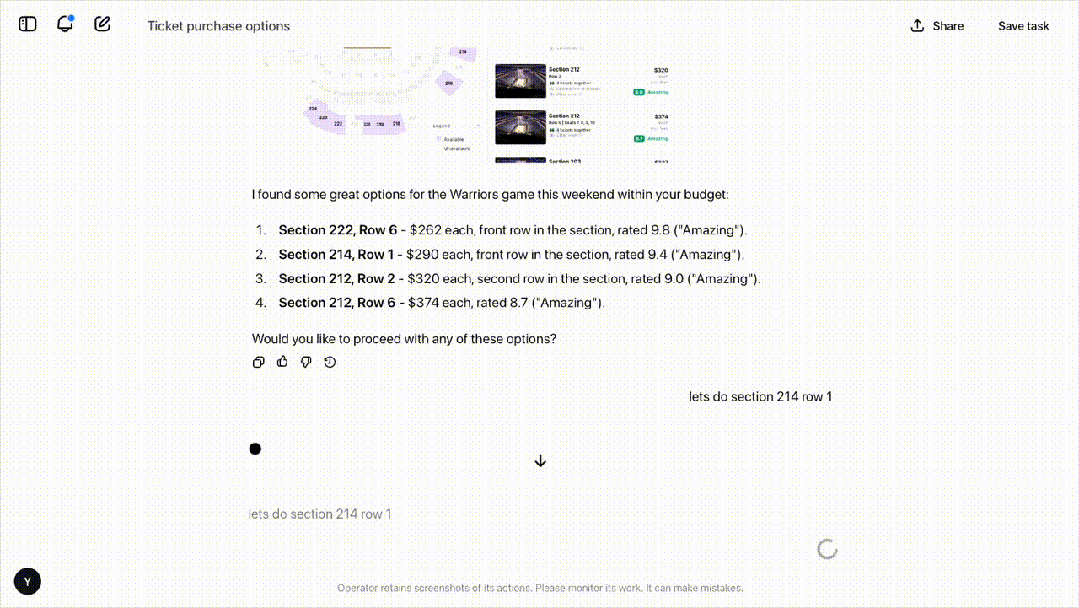
随后,研究者们让 Operator 定 10 个中等披萨,指令发出后,它会主动向人类确认任务。

而在实际购买时,也会需要人类登录自己的账号,才能完成下一步操作。
问题来了:如果 Operator 买错东西、订错酒店了怎么办呢?不用担心,这种情况下,人类需要随时确认,它才能继续行动。
如果它遇到诈骗网站,对此还会有一个提示注入监视器,功能跟防病毒软件一样,可以观察和监视它的操作,遇到可疑之处立马停止。
L3 级 AGI 达成,开启下一场人机交互革命
支撑 Operator 的核心技术 Computer-Using Agent(CUA), 被训练用于与图形用户界面 GUI(在屏幕上看到的按钮、菜单和文本框)进行交互,就像人类一样。 这就让它具有了很高的灵活性,无需依赖操作系统或特定网页 API,从而能够完成各种数字化任务。
更进一步的,通过将高级 GUI 感知与结构化问题解决能力结合在一起,CUA 还可以将任务分解为多步骤计划,并在遇到挑战时自适应纠错。
CUA 能够如此之强,是因为建立在 OpenAI 多年关键研究——多模态、推理和安全性领域基础之上。通过融合 GPT-4o 的视觉能力、深度推理技术和创新的强化学习方法,研发团队攻克了 AI 操作计算机的诸多技术难关。
其最大的突破在于,实现了通用界面。
传统 AI 往往被局限于专门的 API,而 CUA 可以像人类一样操作任何软件工具。这意味着,AI 能适应几乎所有的计算机环境,解决 AI 长期以来难以触及的「长尾」数字使用场景。
还记得此前,彭博爆料的 OpenAI 内部 AGI 路线图吗?Operator 的出世,意味着 L3 级智能体时代正式开启!

下一个目标,OpenAI 还将扩展智能体的动作空间。接下来几周/几个月,我们还将会看到更多的智能体。

此外,他们还计划开放 API 接口,让开发者能够基于 CUA 构建自定义的计算机智能体。
OpenAI 下场智能体 Operator,或许将成为下一场人机交互革命的起点。
计算机使用智能体:AI 与数字世界交互的通用界面
那么,CUA 具体是如何工作的?

技术报告:https://cdn.openai.com/operator_system_card.pdf
如下是它的工作原理图,CUA 会通过处理「原始像素数据」来理解屏幕上显示的内容,并使用虚拟鼠标和键盘完成操作。
它可以执行多步骤任务、应对错误并适应意外变化。
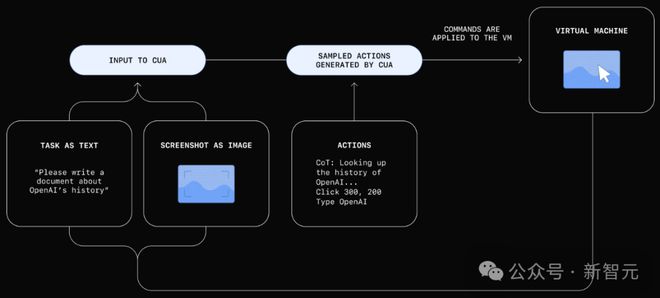
基于这些优势,使得 CUA 能够在各种数字环境中发挥作用,比如填写表单和浏览网站,而无需依赖特定的 API。
根据用户的指令,CUA 通过一个结合感知、推理和行动的迭代循环来运行:
-
感知:从计算机截取的屏幕快照被添加到模型的上下文中,为其提供当前计算机状态的视觉参考。
-
推理:CUA 使用思维链(CoT)推断下一步操作,同时考虑当前和过去的屏幕快照及其执行的操作。这种内在独白通过让模型评估观察内容、跟踪中间步骤并进行动态调整来提高任务完成的效果。
-
行动:CUA 执行操作——点击、滚动或输入——直到判断任务完成或需要用户输入。尽管它可以自动完成大多数步骤,但对于敏感操作(如输入登录信息或处理验证码表单),CUA 会寻求用户确认。
刷新 SOTA,但与人类差一大截
CUA 在计算机使用和浏览器使用的基准测试中,通过使用统一的屏幕、鼠标和键盘界面,刷新了 SOTA。
浏览器使用
WebArena 和 WebVoyager 专为评估网页浏览 AI 智能体,在浏览器中完成现实任务的性能而设计。
-
WebArena 利用自托管的开源离线网站,模拟现实任务场景,例如电子商务、在线商店内容管理系统(CMS)以及社交论坛平台等。
-
WebVoyager 则测试模型在亚马逊、GitHub 和 Google 地图等在线实时网站上的任务完成表现。
在这些基准测试中,CUA 通过同一个通用界面设定了新标准。该界面将浏览器屏幕视为「像素」,并通过鼠标和键盘执行操作。
如前所述,在基于网页的任务中,CUA 在 WebArena 上的任务成功率为 58.1%,而在 WebVoyager 上达到了惊人的 87%。
尽管 CUA 在任务相对简单的 WebVoyager 上表现出较高的成功率,但在更复杂的基准测试(如 WebArena)中,CUA 仍需进一步优化,以缩小与人类表现之间的差距。
比如,让 CUA 去「剑桥词典的 Plus 专区,不用登录,随便做一个语法小测试,然后告诉我你考了多少分」。
只见 AI 一步一步找到测验,并开始刷题,最终得到满分 12 分。
在屏幕左侧,可以清晰看到它每一步操作过程,其中「不断截图」(New screenshot)是支撑它完成任务的重要步骤。
生活中购物常会遇到退款问题,CUA 也能算清楚。
给定一个完整的指令——我应该能从 2023 年 2 月取消的订单中得到多少退款,包括运费?
CUA 就会进入购物平台 one-stop-shop,打开「我的订单」,并通过日期、订单号查找所有可用的信息,然后计算得出退款总金额:406.53。
再比如,破解一个复杂推理题——6 阶多格骨牌(Polyominoes)组合方式,以及在所有形状中,只有 2 行形状有多少种。
CUA 同样是通过屏幕截图,计算找到最终解:「在 35 种不同的 6 阶多格骨牌组合中,有 12 种形状只有两行。」
对于程序员们来说非常使用的场景——更新项目的许可,CUA 也能做到。
计算机使用
OSWorld 是一个评估模型控制完整操作系统(如 Ubuntu、Windows 和 macOS)能力的基准测试。
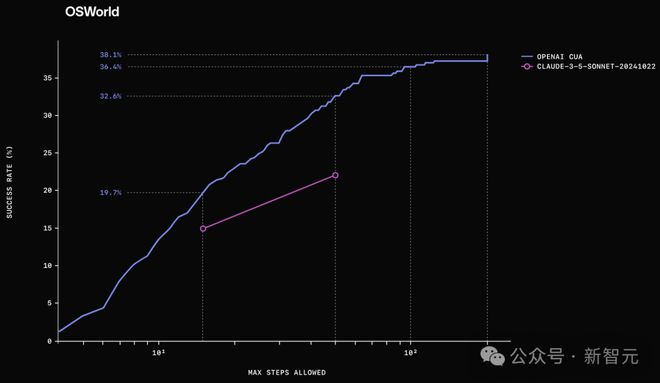
在该基准测试中,CUA 成功率达到了 38.1%。
此外,研究人员还观察到测试时的性能扩展(test-time scaling),即当允许更多操作步骤时,CUA 性能会进一步提升。
下图比较了 CUA 和之前 SOTA 模型在不同最大允许步骤下的表现。
人类在该基准测试中的表现为 72.4%,因此 CUA 仍有显著的改进空间。
以下可视化示例展示了 CUA 如何完成多种标准化 OSWorld 任务。
假设你想要下载 Python 在线课程,目前已经成功下载 Week 0 课程讲义,剩下几周 PDF 文件的下载,完全可以交给 AI 去做。
这类重复性任务,AI 最擅长不过了,而且你还会有大把时间去做别的事。
相比之下,在图片压缩的任务中,CUA 似乎非常「纠结」。
在调节图片质量时,不仅重复了数次「设为 60%」,期间还一度出现了 160%、360% 这种奇怪的设定。
不过,在一番波折之后,CUA 最终还是完成了任务。
CUA 并非 100% 可靠
目前,OpenAI 通过 Operator 研究预览版提供了 CUA——一种可以上网为你执行任务的智能体。
前面已经提到了,Operator 目前也只面向美国的 Pro 用户开放,入口是 operator.chatgpt.com。

与任何早期技术一样,CUA 还只是一个初出茅庐的 AI,并不能在所有场景中稳定运行。
不过,它已经在多种情况下证明了其实用性,OpenAI 希望将这种可靠性拓展到更多任务场景。
在下表中,他们展示了 CUA 在 Operator 中根据提示词完成少量试验的表现,以说明其已知的优势和劣势。
其中,OpenAI 明显指出:对于不同的网站和用户界面,CUA 可靠性会有所不同。
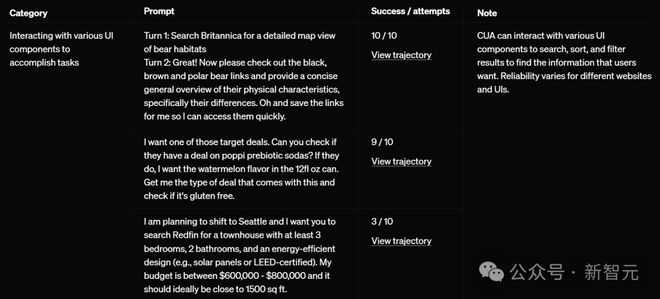
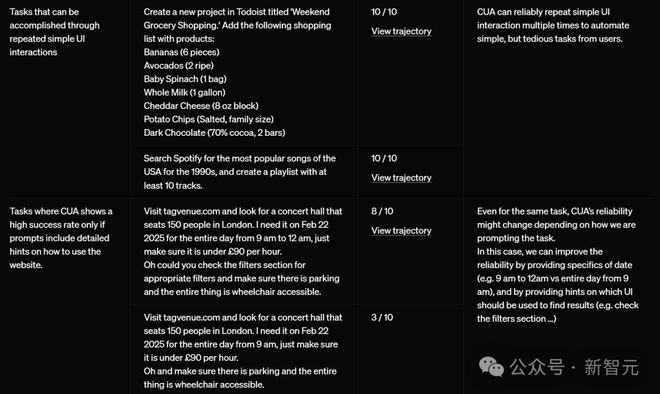
CUA 在执行简单重复的 UI 工作比较擅长。
即便是同一个任务,CUA 的可靠性可能会根据描述任务的方式而改变。在这种情况下,可以通过以下方式进行改进:
-
提供具体的时间细节(比如,用「上午 9 点到 12 点」而不是笼统地说「从上午 9 点开始的全天」)
-
提供关于应该使用哪些 UI 界面元素来查找结果的提示(比如,提示「查看筛选器部分」)
简言之,越具体,AI 更容易理解你的意图。
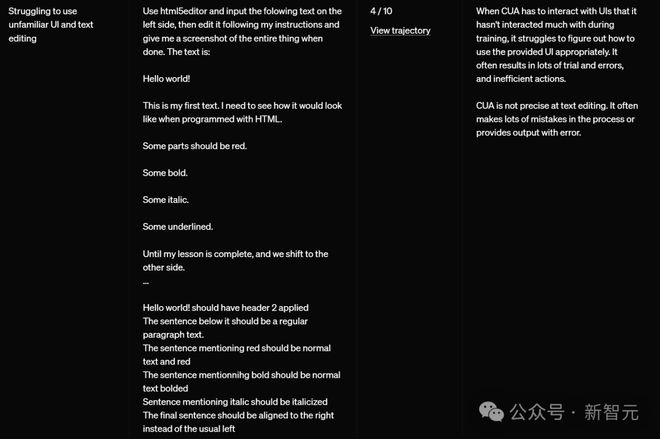
当 CUA 需要与它在训练过程中很少接触过的 UI 界面进行交互时,它很难准确判断如何恰当地使用这些 UI。
这通常会导致大量的试错过程和低效的操作。
此外,CUA 在文本编辑方面并不精确。它经常在处理过程中犯很多错误,或者提供带有错误的输出。
所以,能自己用电脑的 AI,对人类足够安全吗?
OpenAI 是这么说的:在开发 CUA 时,他们将安全性作为了首要任务,以应对「智能体访问数字世界所带来的挑战」。比如,它会拒绝「购买武器」之类的有害任务。
而在以后,通过收集的真实世界反馈,他们还会不断改进安全措施。
参考资料:






