
出品网易科技态度栏目
作者袁宁
编辑丁广胜
DeepSeek 给全世界人民,拜!年!了!

当 DeepSeek 从登顶中美应用商店免费榜,蔓延到成为X、微博、小红书的热门话题,这场关于 AI 的狂欢也逐渐从技术范畴,走到了国运叙事。网友纷纷戏称“建议连夜安排 DeepSeek 上春晚”。
春晚可能是赶不上彩排了,但这个年无疑难忘今宵。

(黑神话悟空制作人冯骥表示 DeepSeek 为国运级别的科技成果)
事情从 DeepSeek 发布新模型起,经过中美再次对账,美国芯片封锁好像不仅没起到作用,反而激发了中国的创新?
一时间,各大主流媒体开始跟进,铺天盖地的报道下,持续看涨的英伟达股价大跌。
一众大佬开始现身评价:特朗普表示 DeepSeek 给美国人工智能产业敲响了警钟,ScaleAI 创始人则暗戳戳表示中国人太努力,meta 更是连夜成立四个专项小组研究其技术原理……

(《华尔街日报》:硅谷对中国制造的人工智能模型赞不绝口)

(《纽约时报》:DeepSeek 是如何颠覆人工智能的)

(《时代杂志》:DeepSeek 引发股市混乱)
DeepSeek 是什么?为什么是它让硅谷科技大佬集体破防?它又凭什么造成了美股的震荡?你需要知道这些:
一、DeepSeek 是什么?
简单来说,DeepSeek 是一家中国的人工智能研究公司。旗下产品为 DeepSeek,可以在 PC 端和移动端使用。

首先,区别于硅谷 AI 企业依赖明星科学家的模式,DeepSeek 核心团队不到 150 人,没有“明星”,也没有“海归”,人才构成完全本土。
创始人梁文锋,80 后,本硕均毕业于浙江大学。他曾透露,DeepSeek 员工都是一些 Top 高校的应届毕业生、没毕业的博四、博五实习生,还有一些毕业才几年的年轻人。此前,雷军以千万年薪招揽的 95 后“天才 AI 少女”罗福莉,就曾是 DeepSeek 的团队成员。
此外,背靠量化私募公司幻方量化,DeepSeek 至今没有融资,完全靠自有资金运行。同时,它也是国内除大厂外,唯一拥有万张 A100 芯片的公司。

( 2019 年,梁文锋在金牛奖颁奖仪式上,发表主题演讲《一名程序员眼里中国量化投资的未来》,当时幻方管理的资金规模就已破百亿。)
二、AI 界的“拼多多”,让硅谷连夜查账
宣称能力可以对标 GPT 系列的模型并不少,为什么偏偏是 DeepSeek 让硅谷 AI 圈集体大破防?

核心在于其极致低价的模型成本。
据介绍,对标 GPT-4o 的模型 DeepSeek-V3,仅使用了 2000 块英伟达芯片,训练成本不到 558 万美元,是同类模型的1/10。
要知道,OpenAI 给特朗普画的”星际大饼“可是价值 5000 万美元。

Meta 内部员工更是吐槽:“我们一个高管的年薪就够训练整个 DeepSeek 模型了,而这样的高管我们有几十个,公司怎么向股东交代?“
其实,早在这次产生爆炸影响力之前,DeepSeek 就已经凭借其极致性价比,在去年 5 月出圈。获得“AI 界拼多多”称号的同时,也带动国内大厂打起了大模型价格战。
但值得注意的是,区别于赔钱换流量的模式,DeepSeek 在低价的同时仍然保持盈利。
梁文锋曾介绍:我们只是按照自己的步调来做事,然后核算成本定价。我们的原则是不贴钱,也不赚取暴利。这个价格也是在成本之上稍微有点利润。
三、算力神话破灭?华尔街估值地震
而 DeepSeek 能够保持低成本的原因,则在于其架构创新。
其首创 MLA(多头潜在注意力机制)与 DeepSeekMoE 架构,将显存占用降至传统模型的5%-13%,并通过强化学习实现“无监督推理突破”——模型可自主反思纠错,甚至展示数万字思维链。
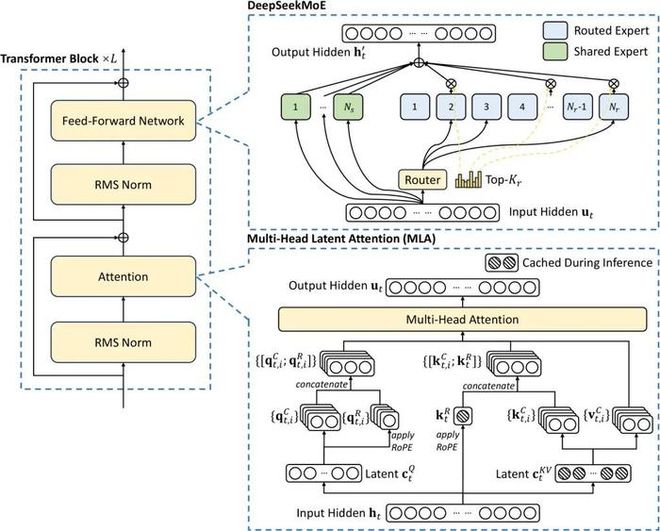
换句话说,仅用很少的 AI 芯片,通过算力效率提高,模型也能实现同样的智能。打破 AI 产业对芯片依赖迷信的同时,也无疑给那些认为仅靠巨额资金就能遏制竞争的巨头们,当头一棒。
正因如此,DeepSeek-R1 发布次日,英伟达、博通股价分别暴跌 16.9% 和 17.4%,微软、谷歌跟跌,欧洲 ASML、西门子能源跌幅超7%。

四、挑战 OpenAI 霸权,用开放击穿闭源护城河
此外,DeepSeek 更是将代码、训练方法、论文全部公开,并在 MIT 协议下允许商业应用。
在”X“上我们已经可以看到伯克利、港科大等学生已用几十美元成功复现模型,被英伟达科学家称为“非美国公司践行 OpenAI 初心”。
(伯克利博士用 DeepSeek 复现模型能力)
要知道,OpenAI 的 API 定价几乎为 DeepSeek 的 30 倍,而 DeepSeek 应用更是当前唯一支持免费联网与深度思考的模型。试问什么会比免费更香?
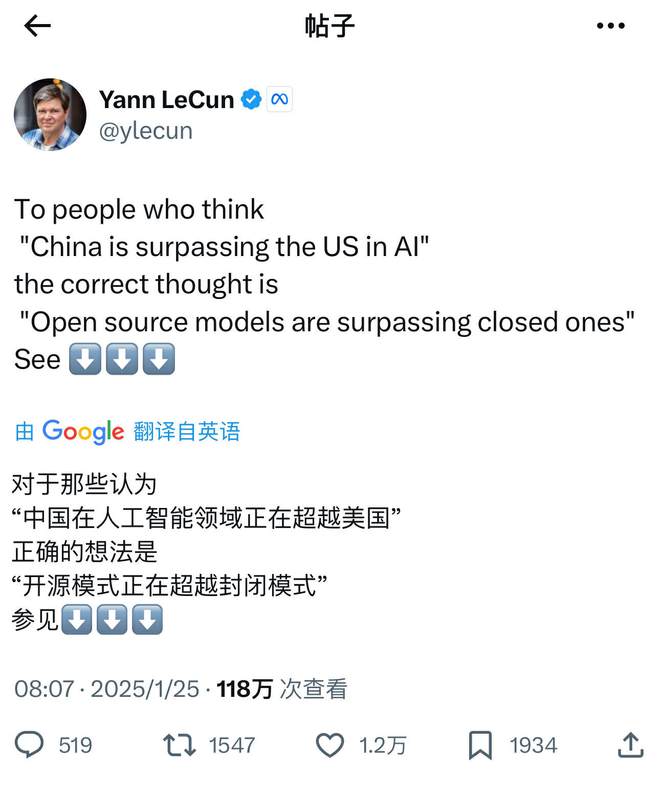
——DeepSeek 的开源生态直接动摇了硅谷“闭源垄断——高额订阅”的盈利逻辑。正如深度学习之父杨立昆所言:“这不是中美之争,而是开源对闭源的超越”。
以上就是,DeepSeek 此次引起巨大反响的原因。
One More Thing
更令人惊喜的是,更多人看到了 DeepSeek 具备的“本土灵魂”。借着年味,小红书上的用户已经开始尝试用 DeepSeek 写诗,写春联。

(Midjourney 创始人使用 DeepSeek 之后的评价)
而 DeepSeek 能够带来的惊喜显然不止于此,就在今天除夕,DeepSeek 再次推出新模型。
辞旧迎新,2025 年的 AI 江湖,好戏刚刚开场。期待中国科技早日从“追赶叙事”走向“定义叙事”。






