大家蛇年发大财!
国产 AI 新锐 DeepSeek(深度求索) 悄然发布了其最新的 o1 级别推理模型 R1,犹如一颗深水炸弹,先是引爆整个硅谷,随后震惊整个世界!这件事的影响力大家都知道了, 事情还在继续发酵,刚刚 OpenAI 的首席研究 Mark Chen 亲自下场评论 DeepSeek R1,虽然肯定了 DeepSeek R1 的研究发现,但是态度非常微妙,还有 DeepSeek 前实习生工对于 Mark Chen 的回应,整个过程不要太精彩,我整理了一下,分享给大家
Mark Chen “态度微妙” 回应 DeepSeek:既肯定又“划重点”?
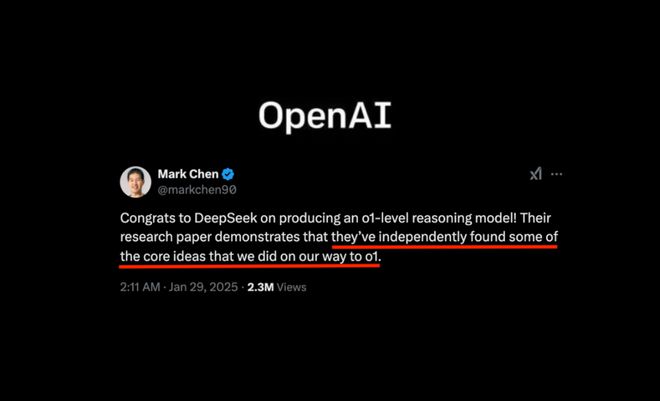
Mark Chen 的推文,表面上是祝贺 DeepSeek 取得的成就,但仔细品味,却能感受到一丝微妙的 “酸味” 和 “防守” 姿态
他首先承认 DeepSeek“独立发现了 OpenAI 在 o1 模型研发过程中的一些核心理念”, 原话:
“祝贺 DeepSeek 成功研发出 o1 级推理模型!他们的研究论文表明,他们独立发现了我们在实现 o1 过程中所采用的一些核心思想”
这无疑是对 DeepSeek 技术实力的一次高调认可,也侧面印证了 DeepSeek 模型的硬核实力

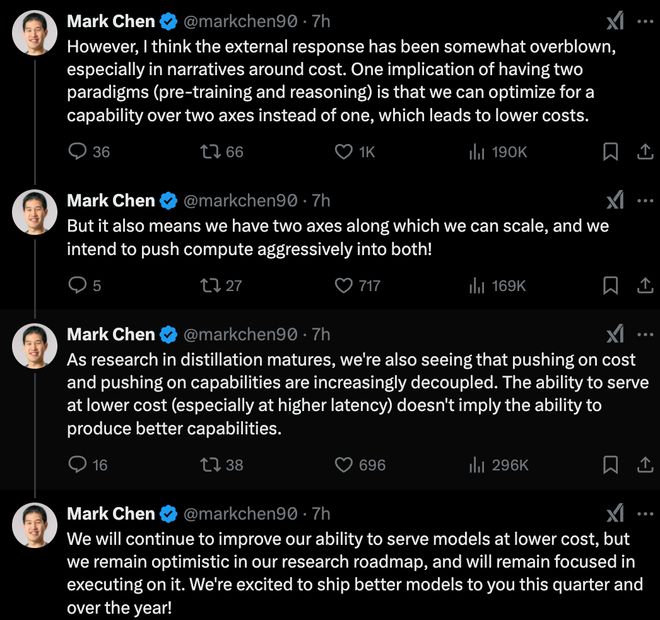
然而,话锋一转,Mark Chen 立即将焦点转移到 “成本” 问题上,认为 “外界对成本优势的解读有些过头”。他抛出了一个略显专业的概念——“双轴优化 (pre-training and reasoning)”, 解释说,将模型训练和推理视为两个可独立优化的维度,可以更有效地控制成本。他的言外之意似乎在暗示:DeepSeek 你在成本控制上做得不错,但我们 OpenAI 也能做到,而且我们还有更全面的优势!
为了进一步 “划重点”,Mark Chen 还提到了“蒸馏技术” 的成熟和 “成本与能力解耦” 的趋势, 暗示 OpenAI 也在积极探索模型压缩和优化技术,降低服务成本。他强调, “低成本服务模型(尤其是在较高延迟下)并不意味着拥有更强的模型能力”, 试图弱化 DeepSeek 在成本方面的优势对 OpenAI 能力优势的冲击
最后,Mark Chen 不忘 “画饼”, 强调 OpenAI 将继续在 “降低成本” 和 “提升能力” 两个方向上 “双管齐下”,并承诺 “今年会发布更优秀的模型”。这番回应,既有对 DeepSeek 技术实力的肯定,也充满了 OpenAI 作为行业领导者的自信和 “捍卫地位” 的意味。毕竟,DeepSeek 这次发布的 o1 模型,直接挑战的是大模型最核心的推理能力,这无疑触动了 OpenAI 的敏感神经
前 DeepSeek 实习生 “扎心”回怼 :OpenAI,说好的“开放”初心呢?
如果说 Mark Chen 的回应还算官方 “过招”, 那么 DeepSeek 前员工 Zihan Wang 对 Mark Chen 回应较为尖锐!(资料显示,他曾就职于 DeepSeek,并深度参与了 RAGEN 项目!) 他还透露自己早在 2022 年就关注 OpenAI,并对其早期的 VPT 和 ChatGPT 项目印象深刻,甚至在伯克利的课程项目也做了类似 VPT 的尝试!曾是 OpenAI 的早期 “粉丝”

Zihan Wang 坦言,他并非有意冒犯,只是好奇曾经以 “开放 AI” 为名的 OpenAI,为何在开源问题上变得如此 “犹豫” 和 “保守”。他回忆起 2022 年 OpenAI 的 VPT 和 ChatGPT 项目,那时他对 OpenAI 的印象是 “开放、创新、引领未来”,充满了乐观和信任。但如今,他感觉 OpenAI “变了”,变得不再像以前那样 “纯粹”,不再像以前那样 “为了更重要的事” 而努力, 似乎更加注重商业利益和竞争优势
DeepSeek 源代码在哪里?
更有趣的来了, 另一位网友 Autark 追问 Zihan Wang ,他直接 “喊话” DeepSeek:“DeepSeek 的源代码在哪里?我说的不是权重或推理支持代码,我要的是真正的源代码!”
面对 Autark 的追问,Zihan Wang 也给出了他了解到的 DeepSeek 官方解释:
“DeepSeek 团队人数有限,开源需要投入额外的大量工作,不仅仅是让训练框架跑起来那么简单 (open-sourcing needs another layer of hard work beyond making the training framework brrr on their own infra)。因此,DeepSeek 目前优先聚焦于迭代下一代模型, 在开源方面,他们优先开源 ‘最小化 + 必要’ 的部分,同时通过发布详细的技术报告,并鼓励社区进行复现, 来弥补开源的不足。”
“华人 AI 力量” 的崛起,中美 AI 竞争的新注脚?
有网友调侃两位来自不同国家的顶级人工智能公司的华人代表在 X 上争论,这可能是 2025 年的一个好兆头
资料显示,Mark chen 高中就读于中国台湾省 National Experimental High School(2004 年 - 2008 年),本科就读于 MIT 的 Mathematics with Computer (2008 年 - 2012)

已经在 OpenAI 工作 6 年 4 个月,今天 1 月刚刚从 OpenAI 研究副总裁升任为首席研究

zihan wang 本科就读于中国人民大学,美国西北大学在读 PhD
zihan wang 2024 年 2 月 - 2024 年 7 月在 DeepSeek 实习,
A. 利用稀疏架构训练专业化语言模型。通过选择最佳的5% 专家进行专业化大语言模型(LLM)调优,能够实现接近完全的性能。该论文作为第一作者在 EMNLP 2024 会议上展示
B. 与团队开发了 DeepSeek-V2,一个拥有 2360 亿参数的模型,采用多头潜在注意力机制来压缩 LLM 效率瓶颈中的 KV 缓存,降低了 42.5% 的成本,生成速度提升了 5.76 倍,获得了 3.5k GitHub 星标和 10 万用户
最后,Zihan Wang 也补充声明:强调他的观点仅代表个人,不代表 DeepSeek 官方立场






