
智东西
作者徐豫
编辑漠影
智东西 1 月 29 日报道,国产 AI 之光 DeepSeek-R1 正快速平替 OpenAI、Meta、Google 的模型,成为应用开发者的新选择。
该模型在知名 AI 开源社区 Hugging Face 上的下载量已超 70 万次,日增40%。
▲DeepSeek-R1 跻身 Hugging Face 最受喜爱的模型前十名(图源:Clem Delangue X 主页)
不过,DeepSeek 强劲的增长势头,也引起了美方的高度关注。
今日凌晨 CNBC 报道称,美国海军基于“潜在安全和道德问题”,已要求内部人员禁止使用DeepSeek 模型。
据玉渊谭天消息,昨天,美国多名官员回应 DeepSeek 对美国的影响,称其“蒸馏”技术是“偷窃”,正对其影响开展国家安全调查。
同日,DeepSeek 官网的服务状态页面显示:“近期 DeepSeek 线上服务受到大规模恶意攻击,注册可能繁忙,请稍等重试。已注册用户可以正常登录,感谢理解和支持。”玉渊谭天向奇安信安全专家咨询并独家了解道,DeepSeek 这次受到的网络攻击,IP 地址都在美国。

截至发稿,在 Chatbot Arena 大模型榜单中,DeepSeek-R1 基准测试排名已升至全类别大模型第二,超过 OpenAI 的 o1 和 o1-mini 模型,仅次于 Anthropic 的 Claude3.5 Sonnet,热度持续攀升。
一、DeepSeek 衍生模型数量日增 30%,下载量超 320 万
Hugging Face 首席科学官 Thomas Wolf 今天接受彭博社采访时,透露了 DeepSeek-R1 开源模型上线一周后增势强劲,并且该公司有计划在 DeepSeek-R1 的基础上,自研开源项目 Open-R1。
Hugging Face 社区内的开发者们正在公开复现 DeepSeek-R1。主页的 135 万个模型中,检索“DeepSeek”相关的模型有将近 2700 个。
Hugging Face 联合创始人兼 CEO Clem Delangue 1 月 28 日发帖称,DeepSeek-R1 的衍生模型至少有 500 种。
Thomas Wolf 今天给出了最新数据,用 DeepSeek-R1 搭建的模型至少有 670 个,累计下载量超 320 万次,日增约 30%;而 DeepSeek-R1 的下载量超过 70 万次,日增 40%。
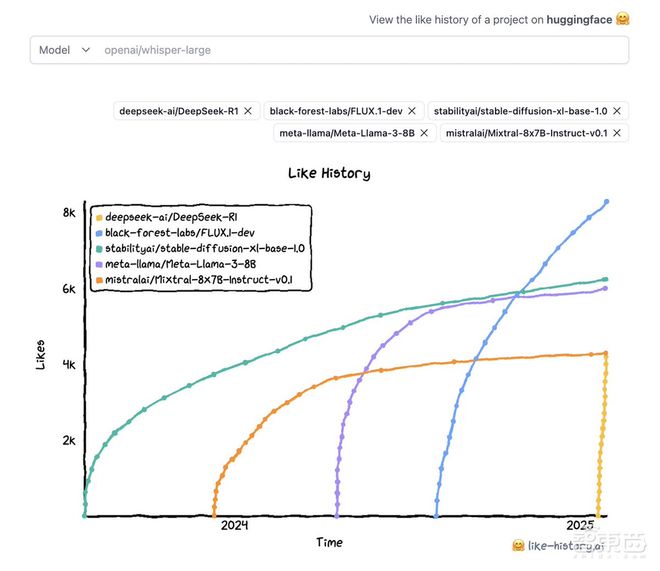
据 Clem Delangue 透露,DeepSeek-R1 已进入该社区史上最受喜爱的模型前十名之列。
截至 1 月 29 日,Hugging Face 社区点赞数排行前十的 AI 模型依次是:
1、黑森林实验室的 FLUX.1-dev
2、CompVis 的 stable-diffusion-v1-4
3、Stability AI 的 stable-diffusion-x1-base-1.0
4、Meta 的 Llama-3-8B
5、BigScience 的 bloom
6、Stability AI 的 stable-diffusion-3-medium
7、DeepSeek 的 DeepSeek-R1
8、Mistral AI 的 Mixtral-8x7B-Instruct-v0.1
9、Meta 的 Llama-2-7B
10、Meta 的 Llama-2-7B-chat-hf
二、Hugging Face 开搞 Open R1,要研究透 DeepSeek
跟上众多开发者的潮流,Hugging Face 也打算基于 DeepSeek-R1 复刻一套自己的新模型,即Open-R1项目。
据 Hugging Face 官网 1 月 28 日介绍,Open-R1 项目将重建 DeepSeek-R1 的数据和训练管道,并在这个过程中验证其效果、突破其上限,从而增强推理的透明度,以及积累可复制的经验。
不同开发商的复刻方法不尽相同。针对 DeepSeek-R1 遗留的特定推理数据收集方法、未公开模型训练代码、训练时的计算和数据缩放定律等问题,Open-R1 计划通过以下步骤补齐这些空白板块:
首先,从 DeepSeek-R1 中提取高质量推理数据集,来复制 R1-Distill 模型。
然后,复制 DeepSeek 用于创建 R1-Zero 的纯 RL 管道,这个过程将涉及为数学、推理和代码任务,整理新的大规模数据集。
最后,可以通过多阶段训练,实现从基础模型到 SFT(监督微调),再到 RL(强化学习)的模型进阶。
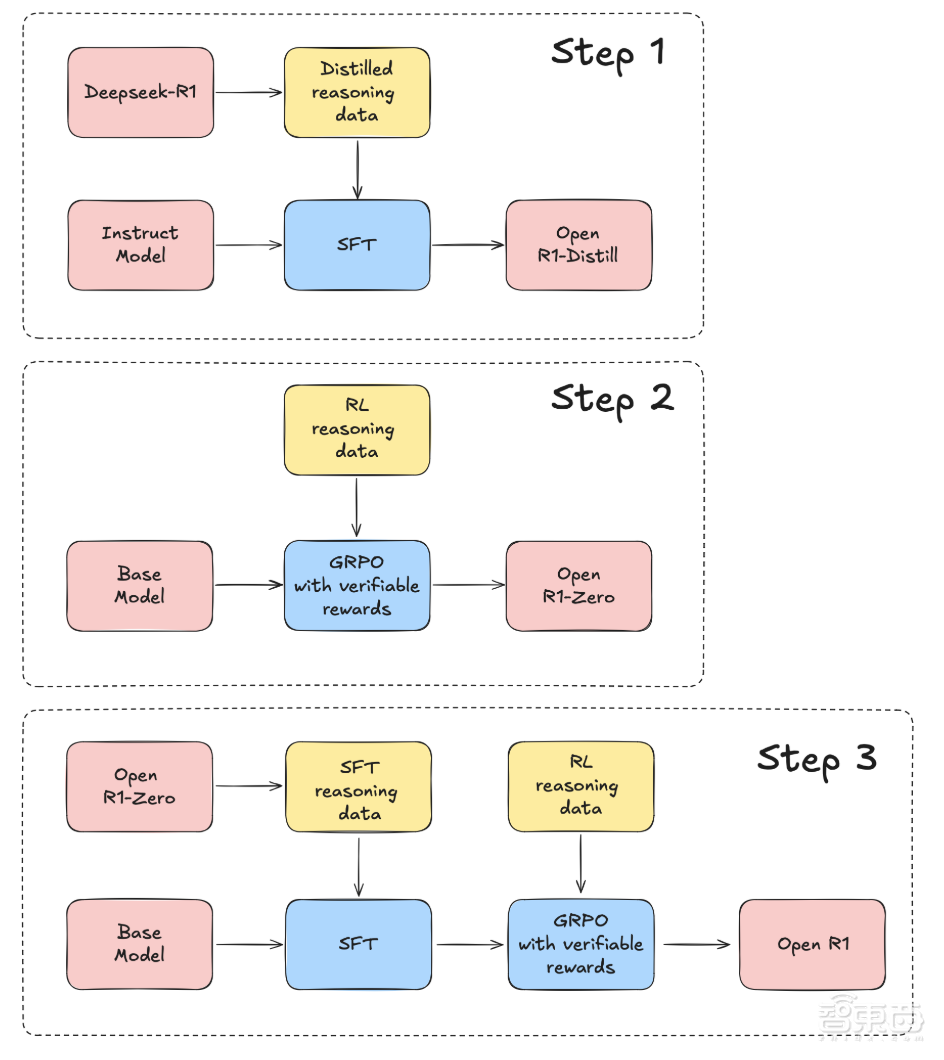
▲Open-R1 复刻 DeepSeek-R1 的计划示意图(图源:Hugging Face 官网)
按照 Thomas Wolf 的预期,其团队将在接下来的几个月内弄清楚这些细节问题,并应用于 Open-R1 项目。
三、谷歌前 CEO:全球 AI 的转折点已经到来
这场有关 DeepSeek 的硝烟,不仅仅笼罩了 OpenAI、Meta、Google 等一众主流模型开发商,使其着手研究如何降低模型的开发成本;也进一步蔓延至中美两国的 AI 博弈大局。
不到两周前,美国商务部工业和安全局(BIS)才颁布了芯片出口限制最新规定。其中,BIS 共拉黑了 11 家与先进 AI 技术有关的中国实体。
在 The Verge 昨晚的报道中,OpenAI 前政策研究员 Miles Brundage 称,像 DeepSeek-R1 这种推理模型通常需要使用大量 GPU,会受到美国芯片出口管制的干扰。
在 Miles Brundage 看来,DeepSeek-R1 使用了两个关键的优化技巧,一是更高效的预训练,二是思维链推理强化学习,这在一定程度上使其能以更少的 GPU 数量、更便宜的 GPU,推动 DeepSeek-R1 实现了更强大的性能。因此,Miles Brundage 称,美国对 GPU 实施有效的出口管制,比以往任何时候都更为重要。
不过,OpenAI 首席研究官 Mark Chen 则倾向于外界夸大了 DeepSeek-R1 的成本优势。他一方面认可了 DeepSeek 独立开发出了 OpenAI o1 级别的推理模型,但另一方面认为两者在开发成本上的差距并没有那么大,仍然对 OpenAI 的技术路线持乐观态度。因此,从某种意义上说,DeepSeek 还是有被先进 GPU 卡脖子的风险。
另外,有不少观点认为 DeepSeek-R1 的出现将惠及部分美国科技巨头。
《华尔街日报》1 月 27 日报道称,DeepSeek-R1 的技术突破意味着,不少美国科技巨头可能不必花费太多时间、精力和算力,来训练他们的 AI 模型。
而且这些模型都是开源的,开发人员可以检查和修改其代码,并用它来构建自己的应用程序。这可以帮助更多小企业花费比闭源模式低得多的成本,用上 AI,并且开源可以促进更多合作和实验。
摩根士丹利分析师 Brian Nowak 称,苹果也将因 DeepSeek 等大模型的任何进展中受益匪浅,原因是苹果“拥有现存最有价值的消费技术分发平台”。
谷歌前 CEO Eric Schmidt 昨天告诉《华盛顿邮报》,他认为美国需要加大开源 AI 研发力度,开发出更多开源模型,鼓励先进 AI 实验室共享训练方法,以及投资星际之门等 AI 基础设施,以应对 DeepSeek 的迅速发展。
Eric Schmidt 还一改去年“美国领先”的说辞,在《华盛顿邮报》专栏文章中称,DeepSeek 的崛起标志着全球 AI“转折点”的到来,证明了中国可以用更少的资源与大型科技公司竞争。
结语:国产模型出圈新路线,Meta、Hugging Face 等争相模仿
目前,有的团队和机构正在研究、复刻 DeepSeek-R1,有的尝试用该模型重塑自家模型,例如 Meta、Hugging Face、UC 伯克利、港科大等。
同时,2025 年开年,DeepSeek-R1 将推理模型竞赛推向新拐点,有望凭借低算力、高性价比的技术路线,开拓国产模型的全球市场。
春节期间 DeepSeek 掀起的这场 AI 风暴,仍在中美乃至全球科技、政金界产生持续影响,并不断发酵。这已经成为改变 AI 科技产业趋势的风向标事件,智东西将持续跟进相关进展和报道,敬请关注。






