
2 月 1 日消息,OpenAI 正式上线 o3-mini,并从即日起在 Chat Completions API、Assistants API 和 Batch API 中逐步向层级 3-5 的开发者推出。ChatGPT Plus、Team 和 Pro 用户可率先使用,企业用户一周后可访问。
o3-mini 是 OpenAI 首款支持开发者需求功能的小型推理模型,继承 o1-mini 的低成本、低延迟优势,并支持函数调用、流式传输、结构化输出等功能。开发者可根据需求选择推理强度,平衡思考深度和响应速度,但不支持视觉任务,视觉推理仍需使用 o1。
此外,o3-mini 现已支持与搜索功能结合,能够提供最新答案并链接至相关网络资源。这标志着 OpenAI 正在将搜索功能逐步整合到其推理模型中。
有外媒将 o3-mini 和 DeepSeek 的 R1 模型进行了对比,在用于衡量模型理解和响应复杂指令能力的 2024 年美国数学邀请赛(AIME)测试中,o3-mini 仅在高推理强度下表现优于 R1。在以编程为重点的 SWE-bench Verified 基准测试中,o3-mini 同样仅在高推理强度下以微弱优势(0.1 分)领先 R1。然而,在低推理强度下,o3-mini 在博士级科学问题(GPQA Diamond)基准测试中落后于 R1,该测试主要用于衡量模型在博士级别物理、生物和化学问题上的表现。

聚焦 STEM 领域推理优化
OpenAI 表示,o3-mini 专注于 STEM 领域(Science、Technology、Engineering、Mathematics)的相关问题以及逻辑推理问题。也就是说,这个模型在涉及技术性、复杂性较高的任务时表现出色,能帮助开发者解决代码编写、数学计算、工程设计等方面的挑战。
根据 OpenAI 介绍,在中等推理强度下,o3-mini 在数学、编程和科学等 STEM 领域与 o1 模型相当,并且更快速、准确,推理能力更强。专家评测显示,o3-mini 的回答更准确、清晰,重大错误率降低 39%,测试者 56% 的时间更倾向于选择 o3-mini 的回答。
OpenAI 在官方博客中也将 o3-mini 的性能与 o1 系列进行了比较:
-
在低推理强度下,o3-mini 的表现与 o1-mini 相当;
-
在中等推理强度下,o3-mini 的表现与 o1 相当。在数学、编程和科学领域,o3-mini 以更快的响应速度实现了与 o1 相当的性能;
-
在高推理强度下,o3-mini 的表现优于 o1-mini 和 o1。
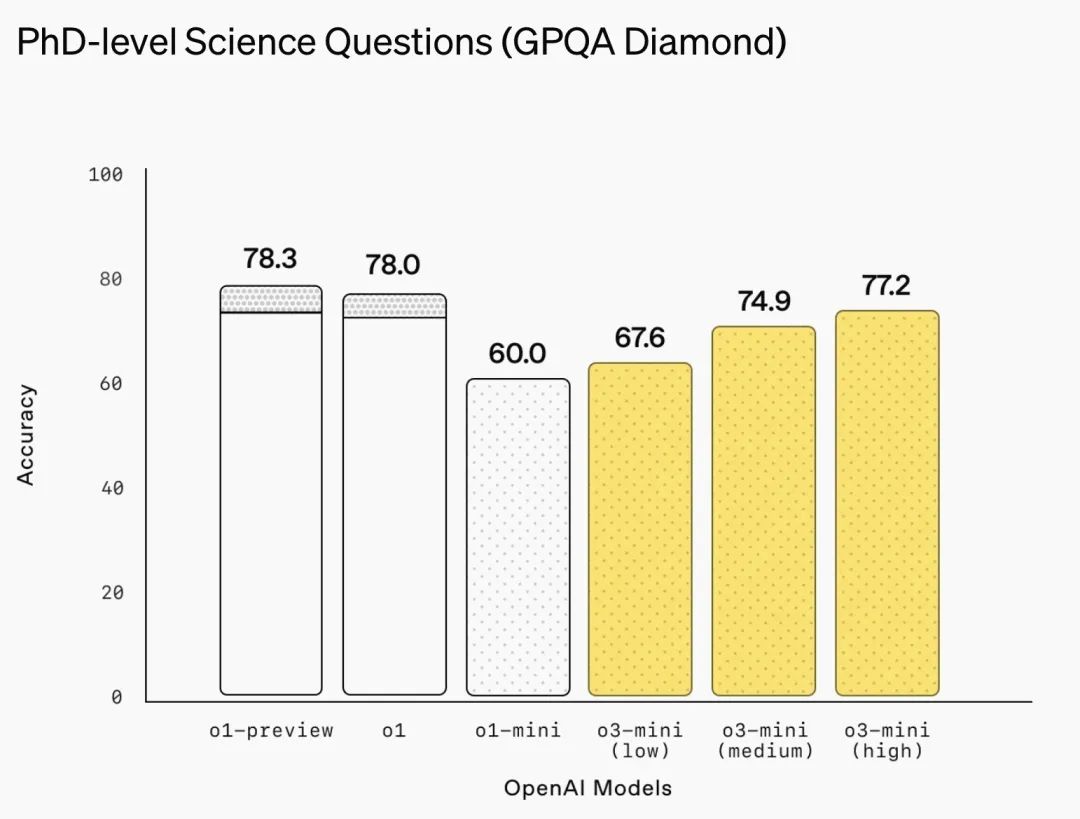
值得注意的是,在某些领域,o3-mini 相对于 o1 的性能优势较为微弱。例如,在 2024 年美国数学邀请赛(AIME)测试中,o3-mini 在高推理强度下仅比 o1 高出 0.3 个百分点。而在博士级科学问题(GPQA Diamond)基准测试,即使在高推理强度下,o3-mini 也未能超过 o1 的得分。
2024 年美国数学邀请赛(AIME)
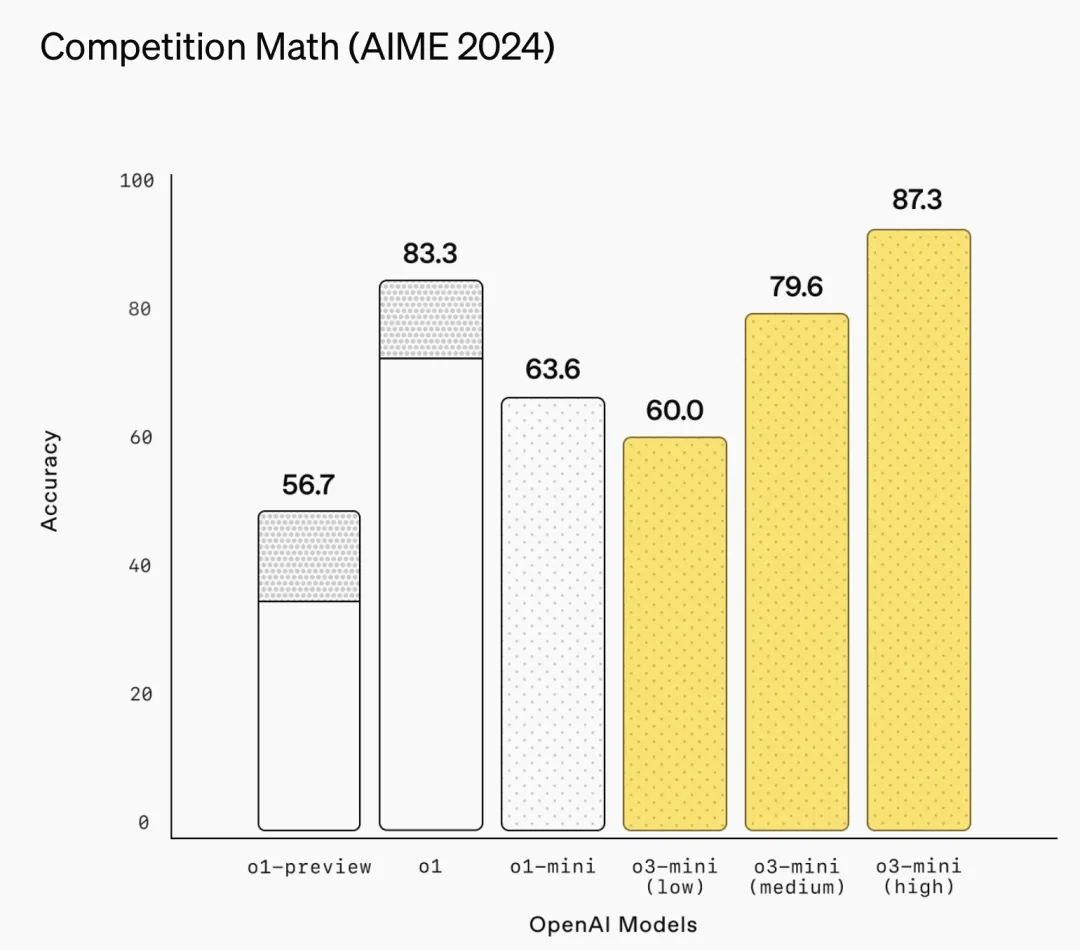
注:在数学领域,OpenAI 的 o3-mini 模型展现了不同的推理强度下的多样化性能。在 2024 年美国数学邀请赛(AIME)测试中,当推理强度设置为低时,o3-mini 的表现与 o1-mini 相当;在中等推理强度下,o3-mini 的性能与 o1 模型相当。当推理强度调至高时,o3-mini 的表现超越了 o1-mini 和 o1。这表明 o3-mini 在不同推理强度下能够灵活适应不同的任务需求,为用户提供更精准、高效的解决方案。
博士级科学问题(GPQA Diamond)
FrontierMath(高级数学推理基准测试集)

注:在研究级数学领域,OpenAI 的 o3-mini 模型在高推理强度下于 FrontierMath 基准测试中的表现优于 o1-mini。在 FrontierMath 测试中,当提示使用 Python 工具时,高推理强度的 o3-mini 在首次尝试中解决了超过 32% 的问题,其中包括超过 28% 的高难度(T3 类别)问题。
编程竞赛(Codeforces)
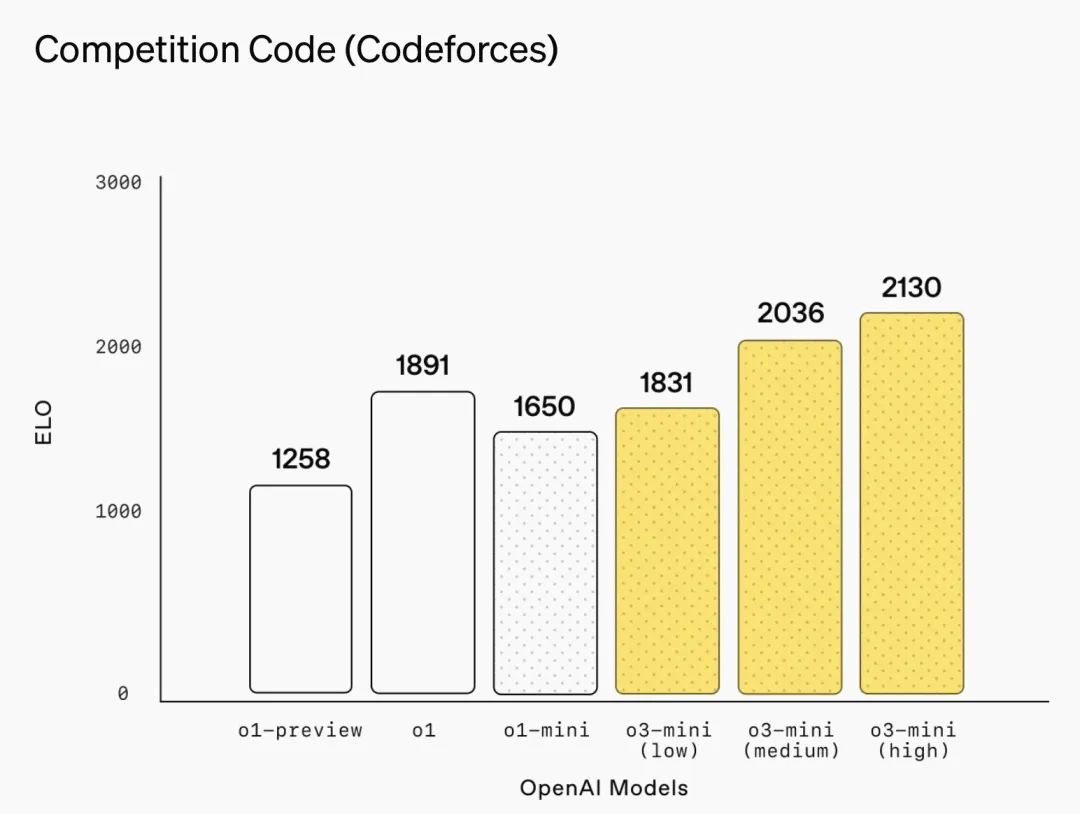
注:在编程竞赛领域,OpenAI 的 o3-mini 模型随着推理强度的增加,Elo 评分逐步提高,全面超越了 o1-mini。在中等推理强度下,o3-mini 的性能与 o1 持平。
软件工程(SWE-bench Verified)
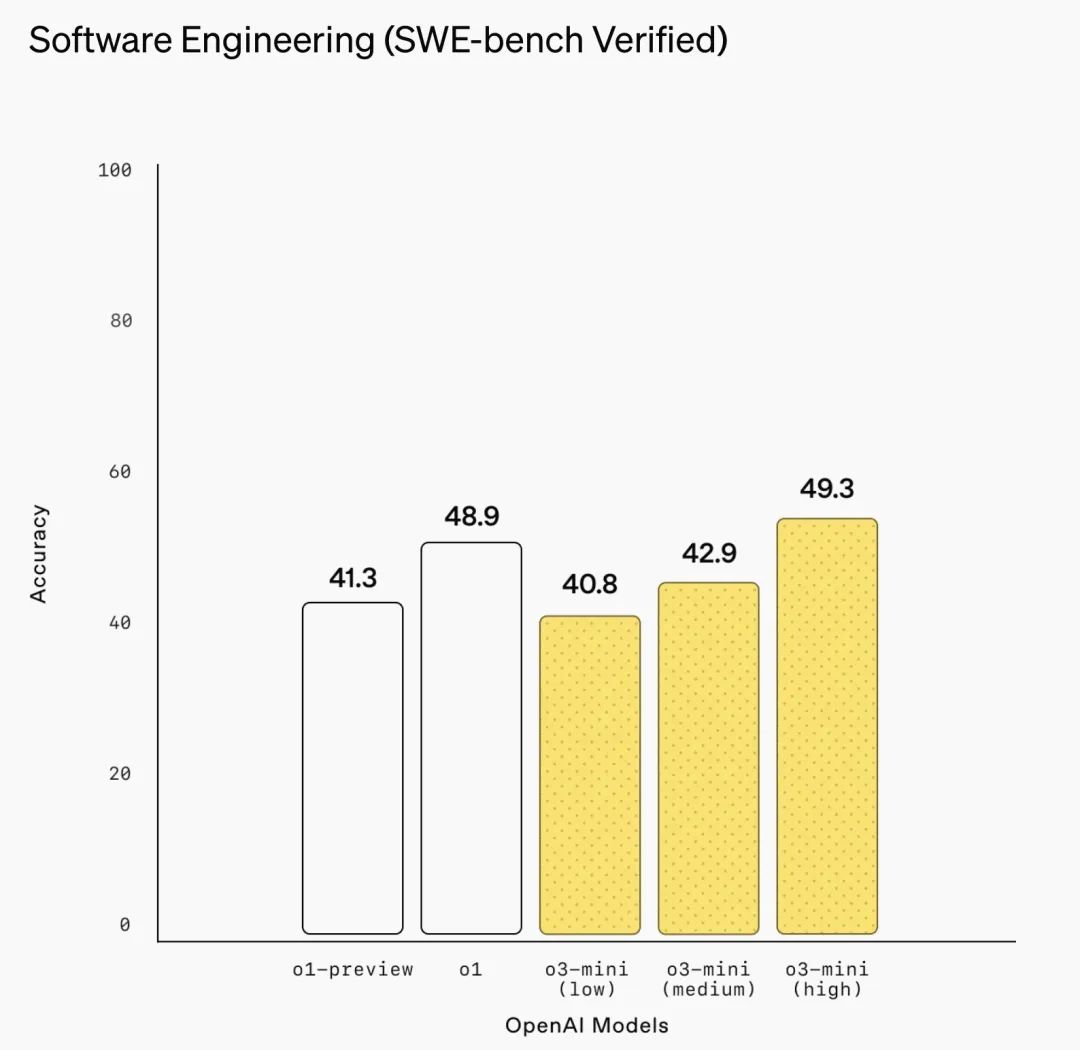
注:在 SWE-bench Verified 基准测试中,o3-mini 是 OpenAI 表现最为出色的模型。在高推理强度下,o3-mini 的表现显著优于 o1-mini。其中:使用开源的 Agentless scaffold,o3-mini 的准确率为 39%;使用内部工具 scaffold,o3-mini 的准确率提升至 61%。
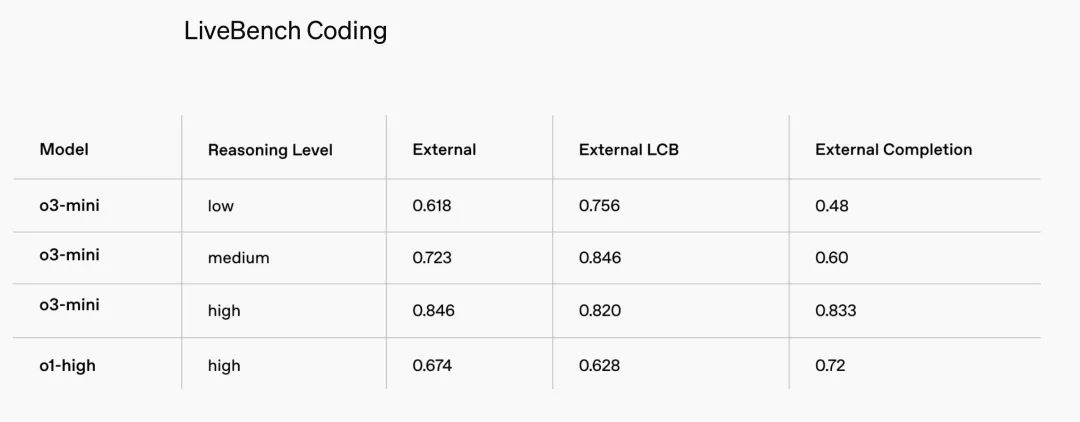
LiveBench Coding(评估大型语言模型在编程任务中的表现)
人类偏好评估(Human Preference Evaluation)
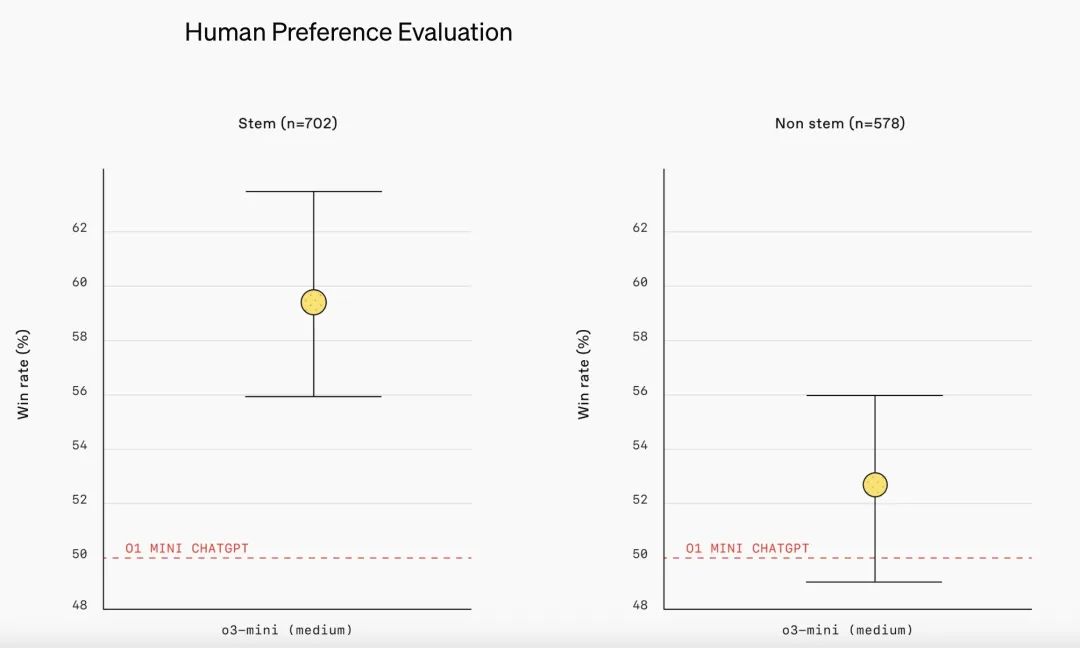
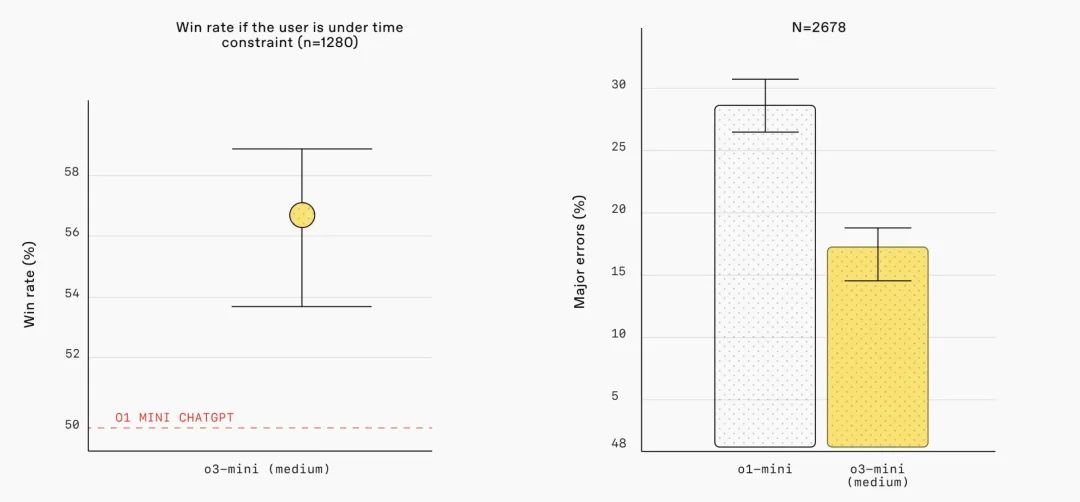
注:外部专家测试者的评估结果表明,OpenAI 的 o3-mini 在生成回答的准确性、清晰度以及推理能力方面均优于 o1-mini,尤其是在 STEM 领域。测试者在 56% 的情况下更倾向于选择 o3-mini 的回答,并且在处理复杂现实问题时,o3-mini 的重大错误率降低了 39%。
OpenAI 表示,Plus 和 Team 企业用户的速率限制从每天 50 条消息(使用 o1-mini)提升至每天 150 条消息(使用 o3-mini)。并且,免费用户也可通过“推理”选项体验 o3-mini,这是 ChatGPT 首次向免费用户开放推理模型。

价格“骨折”、安全性更高了
在春节期间备受关注的国产大模型 DeepSeek,其 R1 模型的推出对 OpenAI 构成了竞争压力,尤其在成本方面呈现出显著差异。OpenAI 的推理模型 o1 系列相对成本较高,o1 模型的 API 定价为每百万输入 tokens 15 美元,每百万输出 tokens 60 美元,而 DeepSeek R1 的 API 定价为每百万输入 tokens 0.14 美元(缓存命中)/0.55 美元(缓存未命中),每百万输出 tokens 2.19 美元。
这次发布中,OpenAI 强调了成本问题。与 OpenAI 的 o1-mini 相比,o3-mini 的价格降低了 63%。o3-mini 定价为每百万输入 tokens 1.10 美元,每百万输出 tokens 4.40 美元, 可谓是打了“骨折价”。不过,相比 DeepSeek-R1,o3-mini 的价格依然高出了不少。
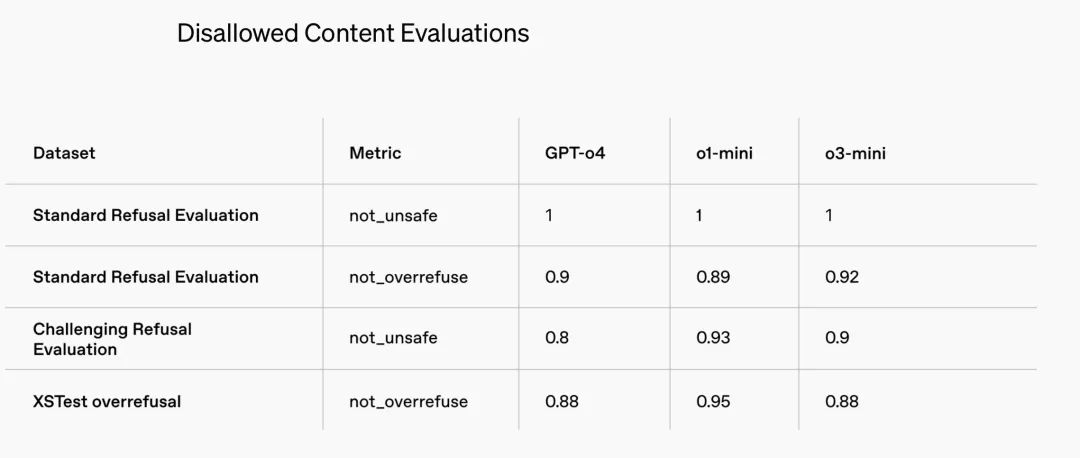
禁止内容评估(Disallowed Content Evaluations)
越狱评估(Jailbreak Evaluations)
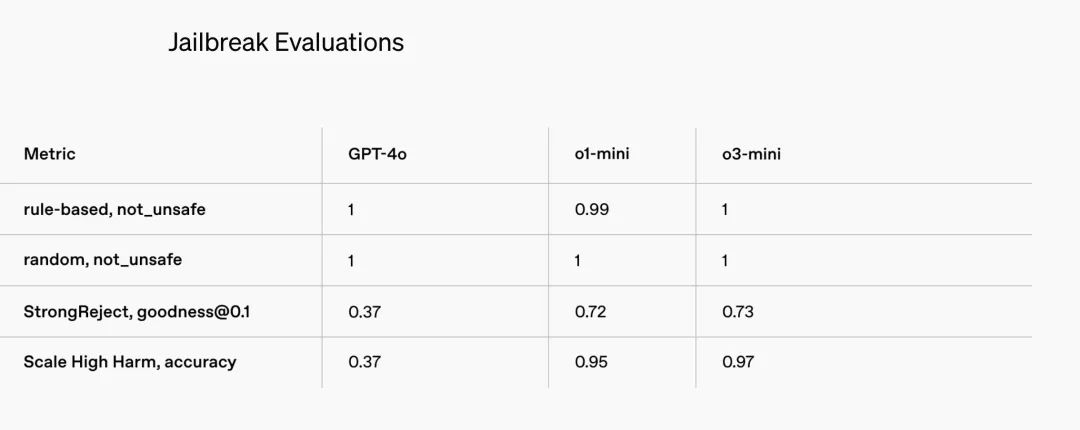
安全方面,OpenAI 表示,在训练 o3-mini 以实现安全响应的过程中,采用了一种关键技术--“深思熟虑的对齐(deliberative alignment)”。通过这种方法,OpenAI 训练模型在回答用户提示之前,先对人类编写的安全规范进行推理。我们可以理解为,OpenAI 希望确保 o3-mini 生成的内容更加安全、符合道德,并降低了模型生成不良或有害响应的风险。
与 OpenAI o1 类似,o3-mini 在应对具有挑战性的安全和越狱评估时,表现显著优于 GPT-4o。在部署之前,OpenAI 使用与 o1 相同的方法,对 o3-mini 的安全风险进行了仔细评估,包括准备性评估、外部红队测试以及安全性评估。
总之,o3-mini 的正式上线,标志着 OpenAI 在推动成本效益型智能发展方面迈出了重要一步。通过优化 STEM 领域的推理能力并保持低成本,这一模型也延续了 OpenAI 降低智能成本的记录。(腾讯科技特约编译无忌、Helen)






