
国产大模型在春节期间的一轮轮产品更新,终于让 OpenAI 坐不住了。
北京时间 2 月 1 日,OpenAI 加急上线了 o3-mini 新推理模型,且首次向 ChatGPT 免费用户开放。

来自国产大模型的这波竞争压力,甚至重新让部分海外同行担忧起美国 AI 的竞争力问题。
近期,前 OpenAI 高管、AI 初创巨头 Anthropic 创始人达里奥·阿莫迪 (Dario Amodei),罕见发布了一篇万字长文。在肯定 DeepSeek-R1 模型在特定基准测试中已逼近美国顶尖水平之外,阿莫迪认为 DeepSeek 的突破,更加印证了美国对华芯片出口管制政策的必要性和紧迫性。
而这轮国产 AI 力量中,在 DeepSeek 发布 DeepSeek-R1 模型的几乎同一时间,月之暗面也推出了 Kimi k1.5 新模型。
上述两款推理模型,均全面对标 OpenAI o1 完整版。其中,Kimi k1.5 凭借同时支持文本和视觉推理的特性,成为首个可以比肩 o1 完整版水平的多模态模型。
尽管 OpenAI 展现了下一阶段大模型的技术演进路线,但直到 DeepSeek-R1 和 Kimi k1.5 发布之前,国内一众大模型厂商均尚未推出能够对标 OpenAI o1 完整版的模型。它们的出现,成了国产大模型攻破 OpenAI 技术黑匣子的又一次实力展示。
更重要的是,相比 OpenAI o1 模型付费使用的限制,无论 DeepSeek-R1,还是 Kimi k1.5,都支持用户免费无限调用。

堪比 OpenAI o1 完整版的模型性能,加上免费调用的差异化竞争优势,DeepSeek-R1 和 Kimi k1.5 新模型,成了春节期间国内大模型对 OpenAI 发起突然袭击的两把尖刀。
借助春节舞台,完成某种后来居上式的战略调整,已演变为中国科技公司的保留节目。
2014 年春节前夕,微信首度推出红包功能,未能掀起太多水花。转折发生在 2015 年,借助与春晚合作,斥资 5 亿元推出“摇一摇”红包的微信,在除夕当天使得微信红包收发总量超 10 亿次,并在 2 天内完成了支付宝此前花费 10 年完成的工作——2 亿张银行卡绑定。
微信红包的此番逆袭,后来被马云在阿里内部称为是对支付宝的一场“偷袭珍珠港”,并促使阿里在 2016 也开始重金赞助春晚,通过“集五福”的形式大撒红包。
现在,被 DeepSeek-R1 和 Kimi k1.5 新模型突袭过后的 OpenAI,也不得不调整了自己的新品发布节奏。
在国产大模型的快速技术迭代和模型性能追赶压力之下,即便是 OpenAI,恐怕也受不了几次这样的突袭了。“我们会开发出更好的模型,但我们不会像往年那样保持那么大的领先优势了。”OpenAI CEO 奥特曼在 o3-mini 发布后的问答环节中说道。
A
DeepSeek-R1 和 Kimi k1.5 新模型一经发布,便在海外用户群中引发热议。
英伟达 AI 科学家 Jim Fan 第一时间发帖总结两大模型的相似之处,认为两者都简化了强化学习框架,同时提升了推理性能和效率,并评价两家公司所发表的技术论文,都堪称“重磅”级别。
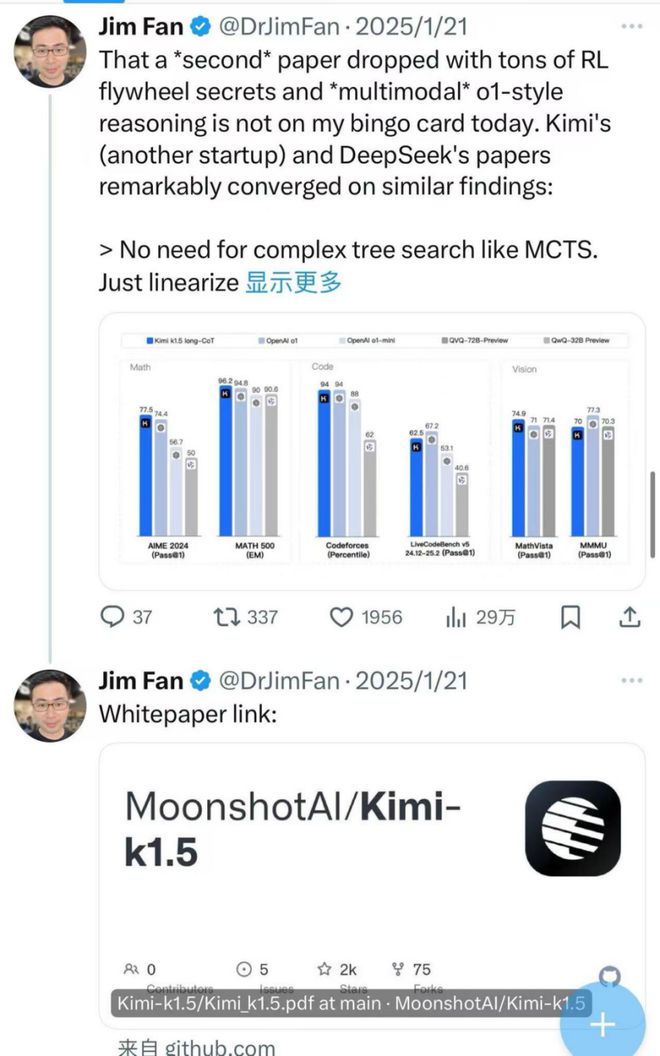
伯克利人工智能博士,Huggingface 机器学习科学家 Nathan Lambert、科技大 V AK 等也纷纷试用 kimi,还有不少业内人士对这两款来自中国的产品进行了测评。

与 DeepSeek-R1 一样,Kimi k1.5 新模型同样展现出了详细的思考过程。
北京时间 1 月 31 日,苹果发布了新一季度财报,以此为契机,选中 Kimi k1.5 推理模型,输入提示词“写一篇苹果财报分析稿,其中尤其要关注中国市场的变化,以及苹果 AI 何时在国产 iPhone 中上线的情况”。
经过一段时间思考,Kimi 给出了苹果 2025 财年第一财季的业绩报告数据,并特意指出其中大中华区营收为 185.13 亿美元,同比下降 11%。
除了给出联网参考的 94 个网页信息之外,Kimi 还列出了自己的详细思考过程。

如果将大模型看作一个数学家,没有加入推理功能之前,大模型在证明了一个新的定理,或者解了一道新的数学题时,只会把答案写出来,不会把思考的过程写出来。但是,有了推理功能的加入,现在大模型就可以把原本只存在于数学家个人头脑中的思考过程,给尽可能完整呈现出来。
Kimi k1.5 推理模型的思考过程,颇有点“授人以鱼不如授人以渔”的作用,将其用来指导学生学习,或者辅助程序员编写代码等,都有了更强的实际用途,大模型从有用,逐渐变得真正好用起来。
更重要的是,相比 DeepSeek-R1,Kimi k1.5 还是 OpenAI 之外首个实现 o1 完整版水平的多模态模型。
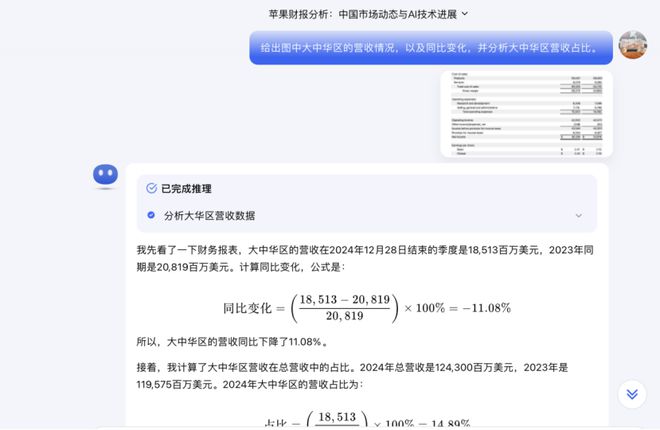
在 Kimi k1.5 推理模式下,上传一张苹果最新一季财报的数据图表,并给出提示词“给出图中大中华区的营收情况,以及同比变化,并分析大中华区营收占比”。
Kimi 不仅读懂了图片中的营收数字,还通过列出数学公式的方式,准确算出了大中华的营收同比下降了 11%,且营收占比也从去年同期的 17%,下降至今年的 15%。
杨植麟曾在一次采访中解释道,长文本就是某种意义上的长推理,“如果我们想让 AI 从完成一两分钟的任务变成完成长周期的任务,那必然要在一个很长的 context(上下文)里,才有可能真正把 AI 进一步往下推进。”
加入图片识别等多模态功能,在某种程度上也可以看作是对长文本准确率的一种提升,这种提升,未来还可能随着无损压缩视频多模态的融入,变得更加强大。
B
对人才的重视和培养,成为 DeepSeek 和月之暗面能够率先做出对标 OpenAI 最新模型 o1 的共性之一。
在 DeepSeek 目前约 150 人左右的团队中,大多是一帮 Top 高校的应届毕业生、没毕业的博四、博五实习生,以及一些毕业才几年的年轻人。
从 2023 年初成立至今,月之暗面更是长期被视为中国大模型创业公司中,技术人才密度最高的玩家之一。
在 Kimi k1.5 中,月之暗面团队找到了一种提升推理效率的原创技术,即 Long2Short 高效思维链。
在 o1 模型中,OpenAI 一般依赖于逻辑链条(Chain-of-Thought,CoT)来逐步推导出解决方案,这是一种用时间换取精准答案的方法。
月之暗面团队开发的 long2short 技术途径,把长思维链(复杂的推理过程)的推理结果“教给”短思维链(简单高效的推理过程),两者进行合并,最后针对“短模型”进行强化学习微调,从而达到提升 token 利用率以及训练效率的目的。
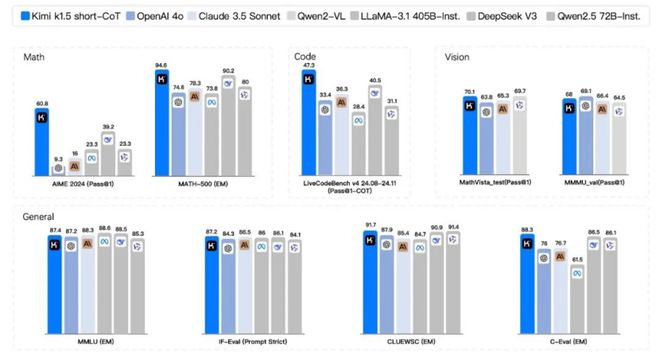
在 Short CoT(短文本)模式下,Kimi k1.5 的能力同样大幅领先 GPT-4o 和 Claude 3.5,领先幅度高达 550%。
良好的产品使用体验正在给 Kimi 带来用户量的增长。根据 SimilarWeb 2024 年 12 月的数据,Kimi 在 web 端排名全球前五,仅次于 ChatGPT、Google Gemini、Claude 和 Microsoft Copilot。
C
在 DeepSeek 和 Kimi 们的突袭之下,来自 OpenAI 等对手的一轮新竞争,已经在赶来的路上。
奥特曼预告中的 OpenAI 新模型 o3-mini 紧急上线,甚至新一代高级语音模型也发布在即,为了在追求 AGI 道路上走得更快,奥特曼更是联手软银孙正义,搞起了 5000 亿美元的算力开发大计划。
可以预见,追赶的压力,或许很快便会再次来到国产 AI 们的头上。
但通过 DeepSeek-R1 和 Kimi k1.5 新模型的这番突袭,一个值得关注的新变动是,国产大模型正在向外界越来越多地证明其自主创新能力,甚至不排除有一天完成对 OpenAI 的真正超越。
近期,Meta 首席 AI 科学家杨立昆(Yann LeCun)在达沃斯“技术辩论”会议上再次提醒道,“我认为当前 LLM(大语言模型)范式的生命周期相当短,可能只有三到五年。五年内,任何清醒的人都不会再使用它们了,至少不会作为 AI 系统的核心组成部分……我们将看到一种新的 AI 架构范式的出现,它可能不会有当前 AI 系统的那些局限性。”
对于任何立志于实现 AGI 的大模型玩家而言,追赶 OpenAI 都绝不是公司成立的初衷和目标,OpenAI 与国产大模型之间的差距,正在逐渐缩小已是不争的客观现实。
斯坦福大学计算机科学系客座教授、谷歌大脑联合创始人吴恩达(Andrew Ng)近期发文指出,DeepSeek 的讨论让许多人认识到一些显而易见的重要趋势,其中之一便是中国在生成式 AI 领域正赶超美国。

2022 年 11 月 ChatGPT 刚刚推出之际,美国在生成式 AI 领域远远领先中国,这一领先差距被业内认为在2-3 年之间。但经过两年发展,OpenAI 对国产大模型的领先优势已经被收缩到 6 个月。
通过 Kimi、DeepSeek 等模型的持续突破,“中国企业展现出强大的创新能力,在视频生成等特定领域甚至已经实现了局部领先。”吴恩达点评道。
国产大模型在技术上的快速迭代能力,甚至引得奥特曼在 o3-mini 的问答环节中,也不得不正视道,OpenAI 的领先优势不会再像往年那么大了。
归根结底,大模型所蕴藏的无限技术创新空间,为国产大模型玩家们,在打造产品差异化方面提供着无限机遇。
更广阔的 AI 创新前景,也将孕育出更多国产大模型的奇袭时刻。






