过年这阵子最火热的话题,恐怕要数《哪吒2》和 DeepSeek。
一个是中国古代神话传说人物,另一个是 AI 领域的后起之秀。本来八竿子打不着的两家,却在这个春节意外地“相映成趣”。

不少人这阵子可能一直有在关注 DeepSeek 的进展,也包括那 83 个小时的保卫战。当他们坐在电影院,看到十二金仙对龙族的争议,看到“捕妖队”抓无辜妖众去炼丹,看到龙族退无可退后的反击,心中或许会十分感慨:果然艺术来源于生活,而生活更加残酷且没有道理。
所以,尽管已经有不少媒体报道过了 DeepSeek,但《节点财经》在这里还是想再讲一讲自己所看到的 DeepSeek,以及该公司模型以外的事。
01 绕过三座山,打开 AI 新世界
这阵子有关 DeepSeek 公司和旗下 AI 大模型的介绍已有很多,因此这里我们不再赘述其成绩,就简单聊一聊它对行业的一些启示。
首先,可以“绕过”算力,用算法弯道超车。
以往,大家普遍认为算力是 AI 的核心,发展 AI 就是要不断的堆算力、堆 GPU。于是我们看到,OpenAI 兴起的时候,不仅英伟达(NVIDIA)因此受益,美国也通过禁售英伟达 GPU 来遏制中国 AI 发展。
而就在大家烧钱堆算力的时候,DeepSeek 选择烧脑改算法。
MLA(多头潜在注意力机制)技术大幅降低了长文本推理成本,MoE(混合专家模型)创新解决了路由崩溃难题,多令牌预测(MPT)显著提升推理速度,这三大创新分别针对 Transformer 架构中的不同瓶颈,成为 DeepSeek 能够以小博大的关键所在。
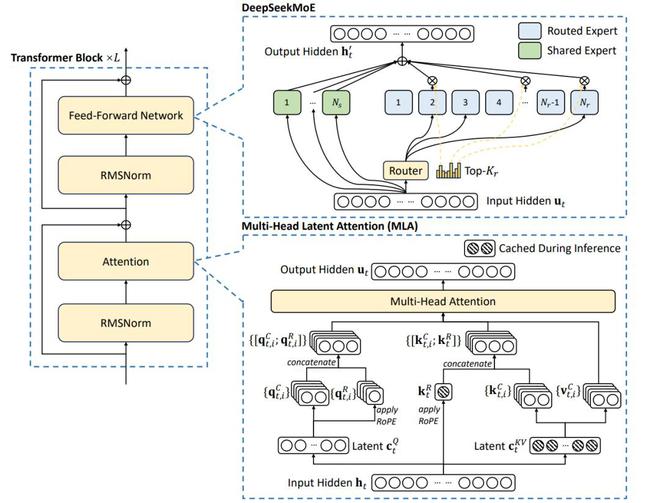
这里举个简单的例子,传统的大模型就好比一家拥有众多服务员和厨师的餐厅,每个服务员从头到尾独立负责自己客人的记菜单、传菜、结账、清洁等工作。当复杂的菜品出现时,全部厨师都围上来讨论谁能做、怎么做。
这就可能会出现多个服务员重复记录相同订单、传菜时堵在厨房门口、厨师资源浪费等重复劳动和效率低下的问题。
而在 DeepSeek 的模型设计中,MLA 技术让所有服务员共享一个智能平板,能实时同步订单、桌号、菜品状态(省去重复记录);上菜时,只有负责上菜的服务员工作,其他人在需要时才会介入(按需分工)。这样既能更快地完成任务,又能保证每部分任务的完成质量。
同时,多令牌预测能让服务员在顾客点主菜后,立马建议甜点和饮料,提前准备服务,而不是等顾客一个个点完,从而使服务更加流畅、体验更好。
MoE 模型则清楚每个厨师都擅长的菜系,在面对复杂的菜品时,模型能够根据菜品的特点,智能地将其分配给最合适的厨师处理,从而提高处理效率,减少不必要的资源浪费。
这些创新技术与架构的运用,让 DeepSeek-R1 的预训练在 2048 块英伟达 H800 GPU(性能受限版本)集群上就能完成,费用只有 557.6 万美元。而 OpenAI 等企业训练模型,则需要数千乃至上万块 Nvidia A100、H100 等顶级显卡,动辄数亿美元的训练成本。
可见,当 AI 行业普遍沉迷于“算力军备竞赛”时,DeepSeek 的“出圈”证明:与其疯狂堆服务器,不如优化算法结构,针对技术瓶颈实施“靶向治疗”,才能让大模型甩掉"耗电怪兽"的帽子,开启低成本高性能的新纪元。
其次,可以“绕过”通用,从垂直场景切入。
根据 DeepSeek 公布的跑分数据显示,DeepSeek-R1 在培训后阶段大规模使用强化学习技术,在数学、代码、自然语言推理和其他任务上,其性能可与 OpenAI o1 正式版本媲美,而价格仅为 o1 的3%。
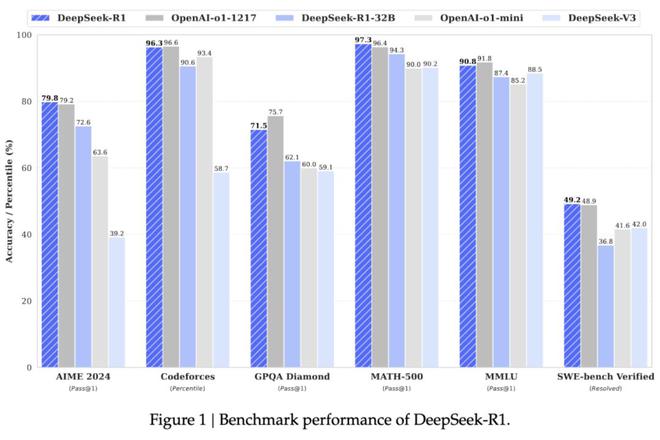
但这并不意味着 DeepSeek-R1 超越了 OpenAI o1,毕竟 OpenAI 优先追求的是“通用智能”,投入大量资金人力,想要的是全能通才的效果。国内企业开发 AI 大模型也大都沿用这一思路,希望自家大模型没有什么明显的能力短板,快速达到可商用水平。
而 DeepSeek 选择从垂直场景切入,先追求在部分领域(如数学、代码)的表现更优,再逐步分阶段完善其他领域的能力。这是一种能够快速成长和建立差异化优势的发展策略。
值得一提的是,文心一言作为扎根于中国市场的大语言模型,根据百度官方的介绍,在多项中文评测中,文心一言 4.0 的表现已经超越了目前最强的 GPT-4 模型。这意味着在理解和生成中文内容方面,文心一言也已成为了全球最顶尖的 AI 模型之一。
因此,《节点财经》认为,中国 AI 企业尤其是创业公司,不必都扎堆死磕“全能大模型”,可选择垂直场景靶向爆破:这样既能规避与通用模型的算力绞杀战,又能通过构建起数据护城河,进而在细分领域闯出一片天。
最后是,可以“绕过”商业,坚持对技术求索。
这次 DeepSeek 之所以能引起这么大的轰动,除了模型本身表现优异、开发和训练成本大幅降低,还有较为重要的一点是,DeepSeek 主张免费开源。
要知道,目前比较知名的其他大模型,无论是国内百度的文心一言、华为的盘古大模型,还是海外的 OpenAI、Llama 等产品,都基于商业化和竞争考量,要么一开始选择了闭源路线,要么逐渐走向闭源,要么虽宣称开源,但却设立了不少限制,并未做到真正意义上的开源。
相比之下,DeepSeek 不仅完全开放代码,还放出了详细的技术报告;不仅开源了自己最大的 671B R1 模型,还帮大家蒸馏量化好了 1.5B~70B 多个尺寸的模型;不仅提供所有的训练数据、训练脚本、论文等,还选择了最宽松的 MIT License 协议,允许任何人免费使用、修改、分发,包括用于商业用途。
DeepSeek 创始人梁文锋此前谈及对于开源的构想是,DeepSeek 未来可以只负责基础模型和前沿的创新,其他公司在 DeepSeek 的基础上构建 To B、To C 的业务。“这一波浪潮里,我们的出发点,就不是趁机赚一笔,而是走到技术的前沿,去推动整个生态发展。”

在《节点财经》看来,或许是因为背靠千亿量化基金,也或许就是纯粹的理想主义,至少从目前来看,DeepSeek 团队重技术突破多过商业变现,要行业繁荣不要垄断优势。
正如英伟达高级研究科学家 Jim Fan 评论的那样:“我们生活在这样一个时代,一家非美国公司正在让 OpenAI 的初衷得以延续,即做真正开放、为所有人赋能的前沿研究。”
02 明枪与暗箭,暴露了谁在心虚
1 月 28 日,多位美国官员指出,DeepSeek 是“偷窃”,正对其影响开展国家安全调查。随后,部分国家和组织也开始“重点关注”DeepSeek:
- 爱尔兰数据保护委员会向 DeepSeek 发出信函,要求其提供有关如何处理爱尔兰公民数据的详细信息;
- 意大利数据保护机构也采取了类似措施,他们认为 DeepSeek 对意大利数百万人数据造成风险,DeepSeek 需要在 20 天时间里作出回应;
- 欧洲消费者组织还认为,DeepSeek 在保护和限制未成年人方面的做法还不够健全,从年龄验证到未成年人数据处理都没有明确的强制执行方案;
而据彭博社报道,近期 OpenAI 与微软展开了一项联合调查,针对 DeepSeek 去年使用 OpenAI API 接口的账户进行审查,并以涉嫌违反服务条款的模型蒸馏为由,取消了他们的访问权限。
在国内舆论场,也有一些所谓的“极客”开始对 DeepSeek 的技术细节发起攻击,声称 DeepSeek 涉嫌“抄袭”或“技术不透明”,并试图通过论文和数据来证明这一点。
当然,以美国为首的西方国家在意的不止 DeepSeek。
华尔街日报日前曾发布报道《It’s Not Just DeepSeek. A Guide to the Chinese AI Companies You Need to Know》,提醒美国人要注意哪些中国大模型公司,并着重指出,百度在中国最早推出面向公众的生成式 AI 文心一言,如今已经拥有 4.3 亿用户。

如果说这些明面上的指控是真是假还有待查证,不能认为是西方国家在刻意抹黑、打压、搞认知战,但在 1 月 25 日~29 日期间,DeepSeek 服务器集群莫名受到每秒超过 2.3 亿次 DDos 恶意请求,攻击总量相当于整个欧洲三天的网络流量总和。

据了解,为了保护 DeepSeek,360 安全响应中心第一时间拉响警报,锁定攻击特征码;华为云启动流量清洗系统,为服务器搭建防护盾;中国红客联盟不到 12 小时就确定了攻击源头全部来自美国,并予以反击。
与此同时,网易雷火的游戏服务器阵列紧急转换为流量缓冲池;大华股份用 AI 识别 0.00017% 的真实用户,菜鸟网络贡献物流算法优化带宽,钉钉开通紧急通讯确保指挥畅通......阿里云、海康威视、泰山云、新华三等企业也都纷纷加入 DeepSeek 保卫战,贡献自己的力量。
1 月 29 日晚 8 点,经过 83 个小时的鏖战,中国互联网企业成功将攻击流量压制 97.2%,捍卫住了 DeepSeek 和中国 AI 产业尊严。
然而,这场中美 AI 角力下的网络安全保卫战只是一个开始。据奇安信 XLab 实验室监测发现,1 月 30 日凌晨,针对 DeepSeek(深度求索)线上服务的攻击烈度突然升级,其攻击指令较 1 月 28 日暴增上百倍。
并且,至少有 2 个 Mirai 变种僵尸网络参与攻击,分别为 HailBot 和 RapperBot。此次攻击共涉及 16 个 C2 服务器的 118 个 C2 端口,分为 2 个波次,分别为凌晨 1 点和凌晨 2 点。
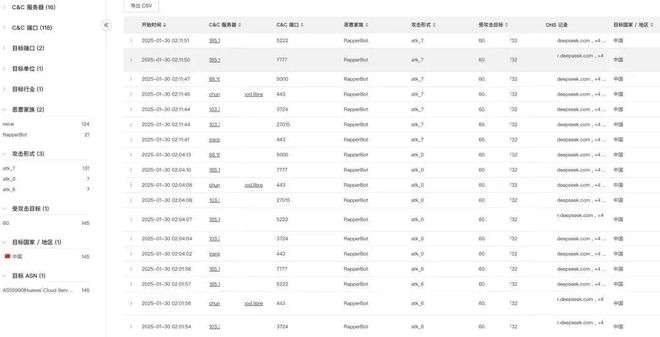
说好的公平竞争、创新取胜,结果是明枪暗箭、防不胜防。
说实话,尽管 DeepSeek 在模型本身和创新路径上确有成绩,但远没有达到超越 OpenAI、算法“封神”的地步。毕竟算力才是大模型可持续发展的必要条件,也是我们的短板,尽管 DeepSeek 找到了一些优化算力使用的方法,但这并不意味着算力需求变得可有可无。
因此,在《节点财经》看来,DeepSeek 的出现,还算不上是技术上的革命性突破,更多的是让大家开始重新思考如今 AI 领域的基础研究角度、商业层面的既有模式。但当下,DeepSeek 却得到了全球“热度”,无所不用其极的围剿,不亚于当年对付华为。
这样的氛围中,心虚的是谁?带节奏的是谁?想要霸权永固的又是谁?其实不言而喻。
总结
DeepSeek 就像是初露锋芒的哪吒,也是纯粹的理想主义者,正试图以技术突破打破封锁,用开源生态重构行业规则。
未来,DeepSeek 能走多远、能开源多久尚未可知,但这想要改变 AI 世界的想法,当下也足以令人兴奋。
毕竟,“因为我们都太年轻,不知道天高地厚。”






