
新智元报道
编辑:编辑部 JHh
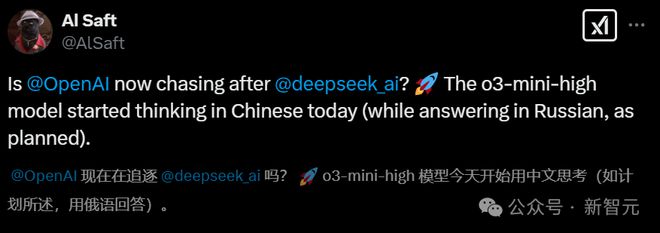
这两天,国外网友纷纷发现 o3-mini-high 在思考过程中居然会经常出现中文!难道真如网友猜测,是借鉴 DeepSeek 了?
国外网友,一觉醒来,发现 o3-mini-high 开始用中文思考了。
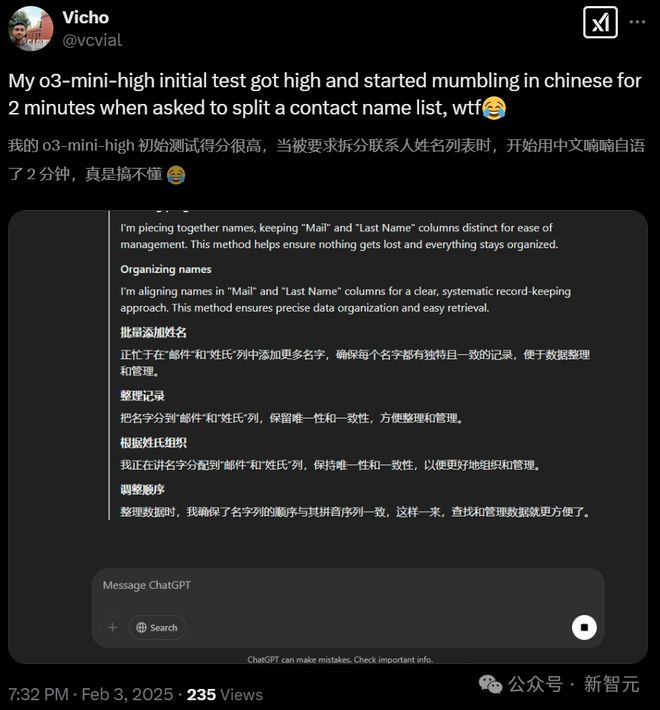
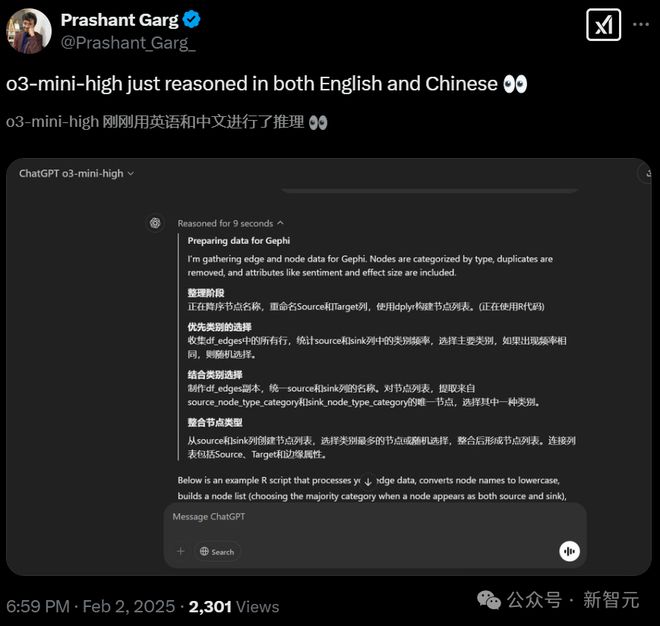
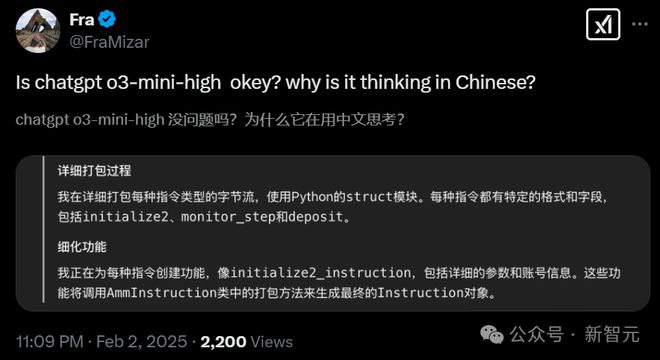
o3-mini-high 作为美国最顶尖的模型之一,竟然在没有用户干预的情况下,如此大量地使用中文进行推理。
如此这般,不禁让网友怀疑,是不是 OpenAI 在「偷师」中国的 DeepSeek 模型。
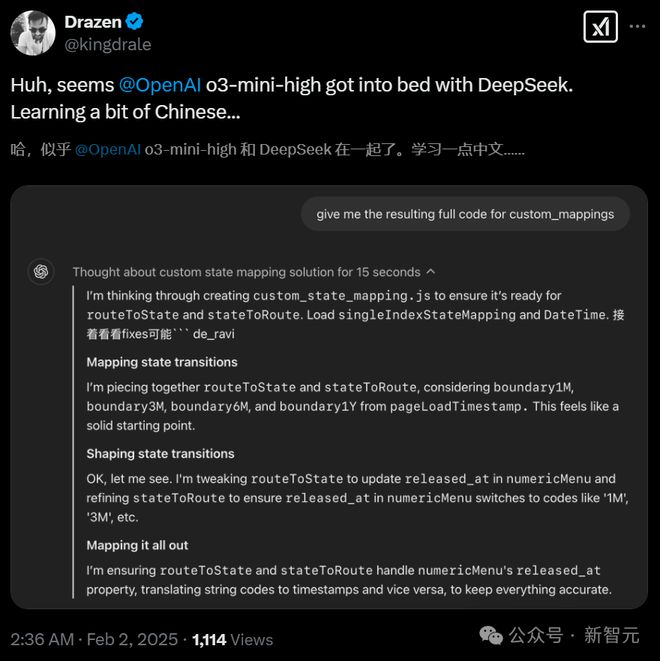
更有意思的是,即便用俄语去提问,o3-mini-high 也会用中文去思考。
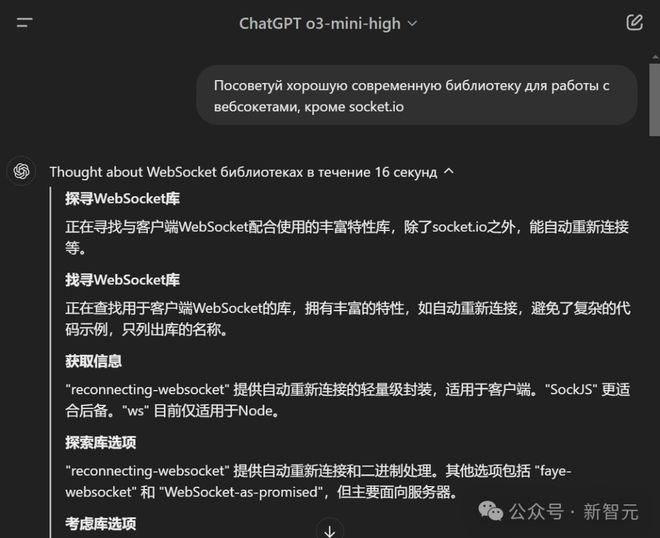
对此,网友纷纷质问起了奥特曼和 OpenAI:「o3-mini 到底为什么要用中文进行推理」?!
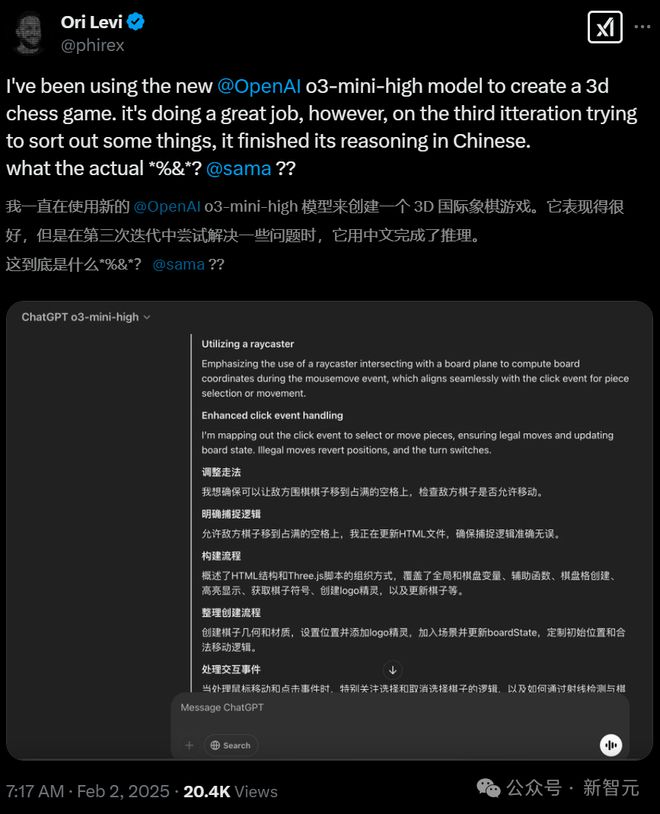
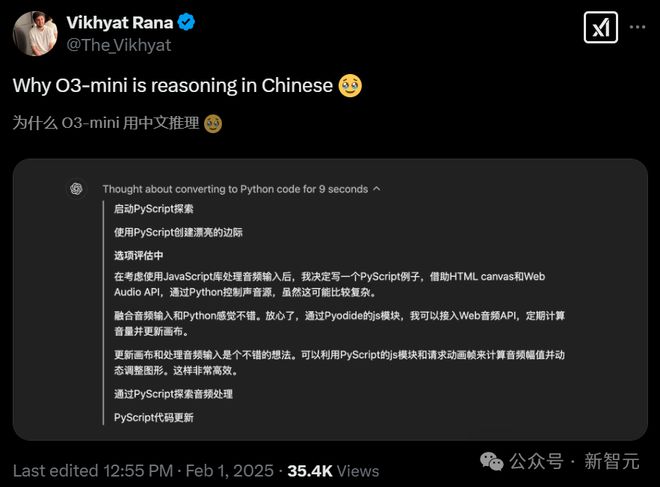
网友 Annalisa Fernandez 则表示,或许中文才是 LLM 的「灵魂语言」。
经此争议,下面这张「DeepSeek/OpenAI 罗生门」梗图,已经在外网迅速传开了。

语言混杂也是老毛病了
当然了,这并不是 OpenAI 的模型第一次发生这种现象。
早在去年 2 月份,就有开发者在 OpenAI 开发者社区上,报道过类似的问题,不过是混合了其他语言。


而在推理模型方面,OpenAI o1 也存在类似的问题。
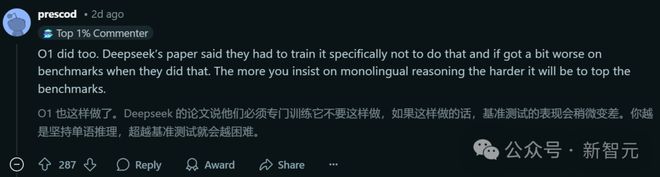
事实上,这种「语言混杂」(language mixing)现象在其他 AI 模型中也有发现。
比如,谷歌的 Gemini 会混杂德语。

为何会突然口吐中文?
那么,究竟是为何才让 o3-mini-high 在推理过程中口吐中文呢?
阿尔伯塔大学助理教授、AI 研究员 Matthew Guzdial 提出了一个切中要害的观点:
「模型并不知道什么是语言,也不知道语言之间有什么不同,因为对它来说这些都只是文本。」
事实上,模型眼中的语言,和我们理解的完全不同。模型并不直接处理单词,而是处理 tokens。以「fantastic」为例,它可以作为一个完整的 token;可以拆成「fan」、「tas」、「tic」三个 token;也可以完全拆散,每个字母都是一个 token。
但这种拆分方式也会带来一些误会。很多分词器看到空格就认为是新词的开始,但实际上不是所有语言都用空格分词,比如中文。
Hugging Face 的工程师 Tiezhen Wang 认同 Guzdial 的看法,认为推理模型语言的不一致性可能是训练期间建立了某种特殊的关联。

他通过类比人类的思维过程,阐述了双语能力的深层含义:掌握双语绝非仅仅局限于能够流利使用两种语言,更是一种独特的思维模式。在这种模式下,大脑会依据当下的场景,本能地挑选最为适配的语言。例如,在进行数学运算时,使用中文往往简洁高效,因为每个数字仅需一个音节;而在探讨「无意识偏见」这类概念时,大脑则会自然地切换到英文,这是由于最初接触该概念便是通过英文。
这种语言切换的过程,恰似程序员在选择编程语言时的自然反应。尽管多数编程语言都具备完成任务的能力,但我们会依据不同需求,选择用 Bash 编写命令行,使用 Python 进行机器学习,因为每种语言都有其特定的最佳适用场景。
「工具的选择需因场合而异」,这一理念对 AI 训练有着重要启示:让 AI 接触多种语言,使其能够学习不同文化所蕴含的独特思维方式。这种包容性不仅能让 AI 更加全面,还能使其更加公平。
在 Reddit 相关帖子下,不少网友表达了相似的观点,即不同的语言各有擅长的领域。
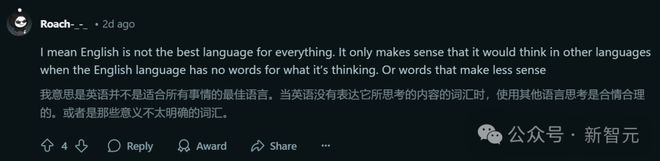


左右滑动查看
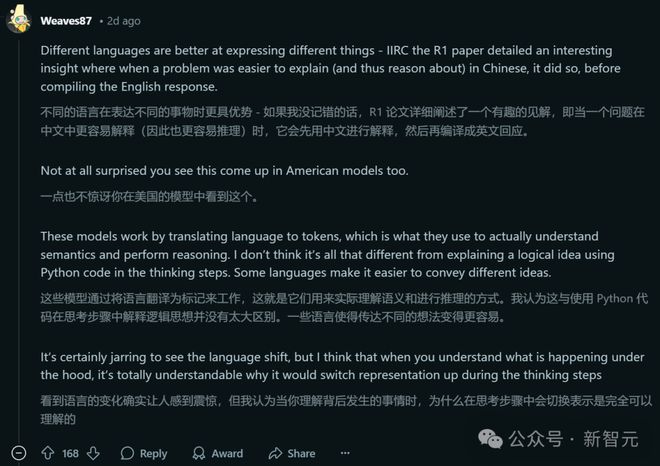
当然,也有另外的推测观点。比如网友 Someone Kong 分析认为,这可能是因为中文更短,所以会在强化学习中获得更多的奖励。
此外,正如网友们反复提到的,DeepSeek 在论文中对这一现象进行了分析。
研究团队发现,当强化学习提示词涉及多种语言时,思维链常常出现语言混杂(language mixing)的现象。
为了减轻语言混杂的问题,DeepSeek 在 RL 训练过程中引入了「语言一致性奖励」,计算方法是 CoT 中目标语言词汇的比例。
尽管消融实验表明,这种对齐方式会导致模型性能的轻微下降,但这一奖励符合人类偏好,使模型的输出更加可读。最后,推理任务的准确度和语言一致性奖励直接相加,形成最终的奖励。
目前,「语言混杂」还亟待解决。
毕竟 DeepSeek-R1 也只是针对中文和英文进行了优化,在处理其他语言的查询时, 也可能出现语言混杂问题。
例如,即使查询是用非英语或非中文的语言提出的,DeepSeek-R1 也可能在推理和回答中使用英文。

论文链接:https://arxiv.org/pdf/2501.12948
或许,正如维特根斯坦所言:「语言的界限就是世界的界限」。

道理是这个道理,但对于那些没学过外语的用户来说,这个推理过程不要也罢!(手动狗头)
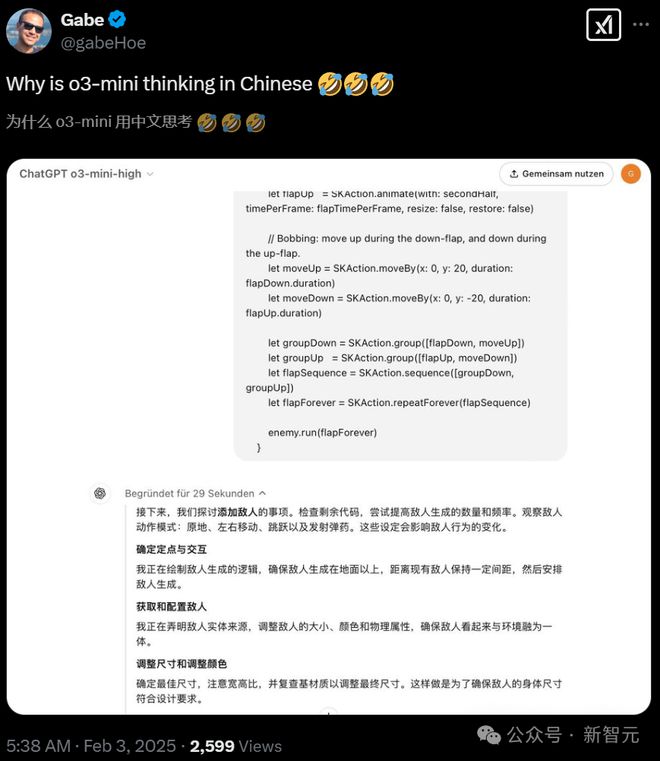
比如网友 Gabe 在看到这么一长串的中文推理后,甚至开始怀疑:「o3-mini 会不会给的都是错误答案。」
有趣的是,就在事件发酵后不久,奥特曼便在 2 月 3 日表示,OpenAI「没有计划」起诉 DeepSeek。
在采访中,奥特曼非常自信地表示,OpenAI 可以继续引领世界:
DeepSeek 无疑是一个令人印象深刻的模型,但我们相信,我们会继续推动技术前沿,推出更多优秀的产品,所以很高兴有一个新的竞争对手。
值得一提的是,OpenAI 本身也面临着多项知识产权侵权指控,主要与模型训练时使用受版权保护的内容有关。

参考资料:






