
新智元报道
编辑:peter 东乔杨
当我们在欢呼 Deepseek 超越 ChatGPT 时,来自美国的艾伦人工智能研究所(Ai2)推出了基于强化学习的新一代开源模型Tülu 3 405B,不仅能够媲美 GPT-4o,更在多项关键基准测试中超越了 DeepSeek v3。
2024 年 11 月,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B 和 70B,在性能上超越了同等参数的 Llama 3.1 Instruct 版本,并在长达 82 页的论文中公布其训练细节,训练数据、代码、测试基准一应俱全。

论文链接:https://arxiv.org/pdf/2411.15124
1 月 30 日,更大杯的Tülu 3 405B 震撼登场。
Tülu 3 405B 在许多标准的基准测试中均实现了与 Deepseek v3 和 GPT-4o 相当或更优的性能,而且也超越了许多先前发布的后训练开源模型(同等参数规模),包括 Llama 3.1 405B Instruct 和 Nous Hermes 3 405B。

各项基准结果比较,最后一列是强化学习优化过的Tülu 3 405B 的表现,在多项指标上超越了 Deepseek V3
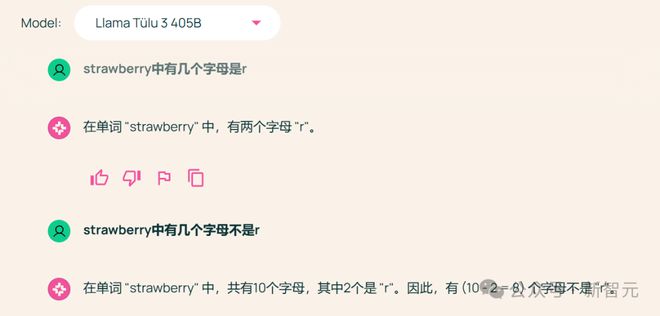
不过在官网提供的体验版上试了试,效果也并不是那么好,对于经典的数 Strawberry 中有几个r的问题,Tülu 3 同样扑街,不过之后需要推理的问题,模型倒是给出了正确的回答思路。
demo 传送门:https://playground.allenai.org/
至于其生成出的一些与蛇相关的格言,大多都没有理解传统文化中「蛇」的寓意,显得牛头不对马嘴。

对于想体验本地大模型的读者,Tülu 3 8B 和 70B 已支持 ollama 下载,可以方便地集成使用,相信 405B 也会尽快上线 ollama 平台。
Tülu 3 的炼丹术如何
早期的语言模型后训练工作遵循了由 InstructGPT 等模型开创的标准方法,包括指令微调(instruction-tuning)和偏好微调(preference fine-tuning)。
自此以后,后训练方法的复杂性和精密度不断增加,但大多数成功的后训练模型对其训练数据、代码或训练方法的披露非常有限。在众多后训练研究中,Ai2 罕见地选择了完整发布训练数据、方法和研究成果,包括最新的Tülu 3 在内。
仓库地址:https://github.com/allenai/open-instruct
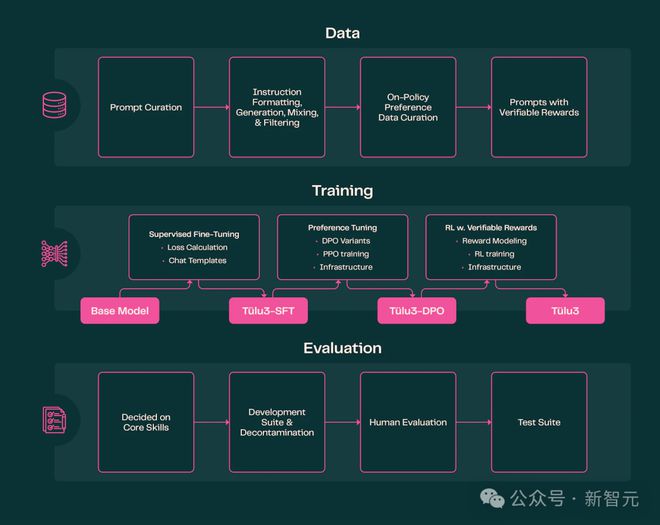
Tülu 3 的全部构建流程如下图所示,包括主要包括数据、训练和评估三部分。
Tülu 3 项目始于确定通用语言模型的关键期望能力,包括知识、推理、数学、编程、指令遵循、日常聊天和安全性。
其中最关键的模型训练,是在预训练语言模型(即 Llama 3 Base)的基础上采用四阶段后训练配方,四阶段依次是:
1)精心策划和合成式提示(prompt);其使用的提示词来源如下:

2)在精心挑选的提示词以及相应生成内容的混合数据集上进行监督微调,以针对核心技能优化模型;同时为了保证模型安全性,使用如下带有攻击性提示词的数据,训练Tülu 3 让其尽可能不会被攻破。

3)结合离线和在线策略偏好数据以应用偏好微调;
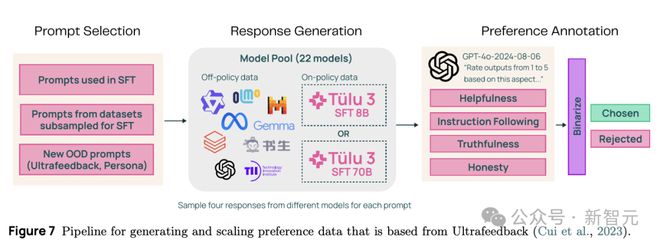
具体来说,就是在之前提示词的基础上,再生成一些不同的新提示词,通过 22 种开源大模型生成回答,让 GPT-4o 对各模型给出的回答在有用程度、真实性、诚实性及指令遵循上的表现进行打分,决定是否接受该回答作为训练数据。
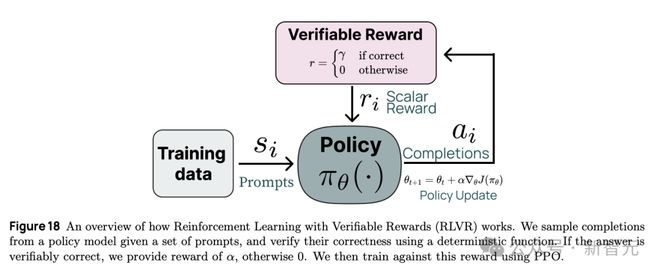
4)一种新的基于强化学习(RL)的方法,通过可验证奖励来增强特定技能;
具体来说,Tülu 3 使用了一种独创的后训练方法,称为:可验证奖励强化学习(Reinforcement Learning from Verifiable Rewards,简称 RLVR),流程图如下所示。
这种新的训练方法专门针对具有可验证结果的任务,例如数学问题求解和指令遵循问题。根据训练数据和提示词,明确判断问题是否完成,从而更新策略函数。
有趣的是,训练采用的可验证奖励强化学习框架在更大规模(例如 405B)上对数学性能的提升更为显著,这与 DeepSeek-R1 报告中的发现类似,即相比 70B 和 8B 参数规模,405B 模型由强化学习带来的提升更为明显。
对此,可能的解释是小型模型从更多样化的数据中受益更多,而大型模型更适合处理需要专门数据的复杂任务。
训练Tülu 3 405B 时使用了 32 个节点(256 个 GPU)并行运行。对于推理,可使用 vLLM 部署模型,采用 16 路张量并行,同时利用剩余的 240 个 GPU 进行训练。
鉴于计算成本有限,超参数调整受到限制。训练时遵循了「参数更大的模型采用较低学习率」的原则,这与 Llama 模型之前的实践一致。

上图展示了在 405B 的参数量上,MATH 数据集的可验证奖励、KL 散度和模型响应长度随训练轮次的变化曲线,总体而言,可验证奖励像在 8B 和 70B 设置中观察到的那样上升。
图中星号标记对应最终检查点的位置。论文表示,团队本打算训练更长时间,但由于计算资源限制而被迫停止。由于在训练过程中没有观察到数学性能饱和,进一步训练可能会进一步提升性能。
总体来看,Tülu 3 采用了全新的后训练框架,包括完全开源的数据(Tülu 3 Data)、评估(Tülu 3 Eval)、训练代码(Tülu 3 Code)以及开发配方(Tülu 3 Recipe),并在性能上超越了同尺度的开源及闭源模型。
Tülu 3 标志着开放后训练研究的一个新的里程碑。凭借 Ai2 披露的信息和研究成果,其他人可以在开放的基础模型上继续构建,并针对多样化任务进行微调以实现高性能,这为在多目标和多阶段训练框架内推进后训练研究铺平了道路,其提出的训练方法也值得开发者借鉴。
参考资料:






