
新智元报道
编辑:编辑部
最近,一位哈佛教授痛心疾首地曝出,DeepSeek 本来有机会诞生在美国?原本 DeepSeek 的工程师可以拿到英伟达的全职 offer,美国却没有将他留住,导致「钱学森回国」的故事再一次上演,美国跟「国运级 AI」擦肩而过!
DeepSeek 给美国造成的威胁,还在加剧。
就在昨天,DeepSeek 的日活数已经达到 ChatGPT 的 23%,每日应用下载量接近 500 万!
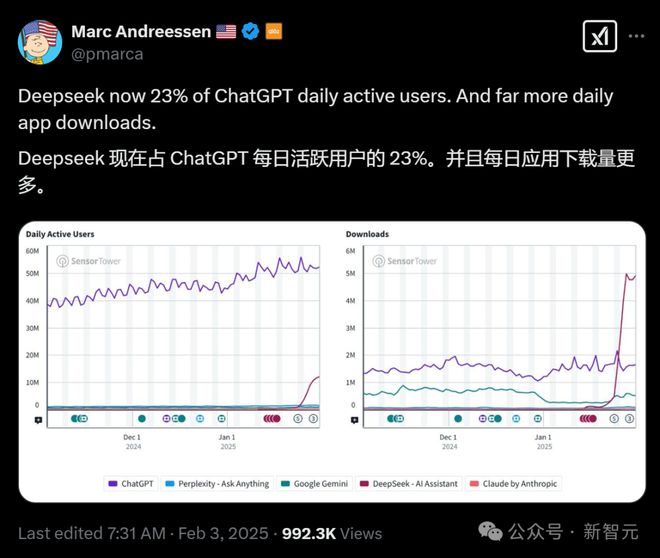
a16z 联创 Marc Andreessen 发文
谁能想到,做出 DeepSeek 关键贡献的人才,本来是可能留在美国的。
最近哈佛大学教授曝出这一惊人事实:DeepSeek 多模态团队的第 4 位工程师,本来可以拿到英伟达的全职 offer。
然而最终,他选择归国加入 DeepSeek,由此的后果就是,美国在 AI 领域的主导地位被动摇,相关公司市值蒸发一万亿,全球 AI 格局也被彻底掀翻。
这种结果是阴错阳差,还是一种必然?
美国错失 DeepSeek,让「钱学森」再次回国
近日,政治学家、哈佛大学教授、前国防计划助理部长 Graham Allison,在X上提问:「谁曾错失了 DeepSeek」?

他在X痛心发帖称,DeepSeek 已刷新对美国 AI 地位的认知,而美国原本有机会留住 DeepSeek 的关键员工之一潘梓正(Zizheng Pan):
(DeepSeek 超越 OpenAI 相关模型)颠覆了我们对美国 AI 主导地位的大部分了解。 这也生动地提醒我们,美国必须多么认真地吸引和留住人才,包括来自中国的人才。
潘梓正,是 DeepSeek 多模态团队的第 4 位多工程师,在开发 DeepSeek 的 R1 模型方面发挥了重要作用。
回国之前,他在英伟达实习过 4 个月,而且拿到了英伟达的全职邀约。
Graham Allison 认为潘梓正之所以如此,是因为硅谷公司未能在美国为他提供这样做的机会。
这种「人才流失」,让 Graham Allison 痛心疾首,甚至将潘梓正回国提升到钱学森归国的高度!

像钱学森、黄仁勋以及马斯克这样的的超级人才可以用脚投票,可以在任何地方施展才华、大张宏图。
他认为,美国应该尽力避免这样的「人才流失」:
美国的大学教练,在寻找并招募世界上最有才华的运动员。 在中美科技竞争中,美国应该尽一切努力避免失去更多的钱学森和潘梓正这样的人才。
英伟达憾失人才
英伟达的高级研究科学家禹之鼎,在得知 DeepSeek 超越 ChatGPT 登顶 App Store 后,分享了当时的实习生潘梓正回国的选择,对他现在取得的成就感到高兴,并分享了对 AI 竞争的观点:

在 2023 年夏季,梓正是英伟达的实习生。后来,当我们考虑是否给他提供全职工作时,他毫不犹豫地选择了加入 DeepSeek。 当时,DeepSeek 的多模态团队只有 3 个人。 梓正当时的决定,至今我仍印象深刻。 在 DeepSeek,他做出了重要贡献,参与了包括 DeepSeek-VL2、DeepSeek-V3 和 DeepSeek-R1 等多个关键项目。我个人对他的决定和所取得的成就感到非常高兴。 梓正的案例是我近年来看到的一个典型例子。很多最优秀的人才都来自中国,而这些人才并不一定只能在美国公司取得成功。相反,我们从他们身上学到了很多东西。 早在 2022 年的自动驾驶(AV)领域,类似的「斯普特尼克时刻」就已经发生过,并且将在机器人技术和大语言模型(LLM)行业继续发生。 我热爱英伟达,并希望看到它继续成为 AGI 和通用自主系统发展的重要推动力。但如果我们继续编织地缘政治议程,制造对中国研究人员的敌对情绪,我们只会自毁前程,失去更多的竞争力。 我们需要更多的优秀人才、更高的专业水平、更强的学习能力、创造力以及更强的执行力。

潘梓正是 DeepSeek-VL2 的共同一作
在 DeepSeek 超越 ChatGPT 登顶 App Store 下载榜第一时,潘梓正在X上分享了自己的感受:
潘梓正 2024 年全职加入 DeepSeek,担任研究员。他曾在英伟达 AI 算法组担任研究实习生。
2021 年,潘梓正加入蒙纳士大学(Monash University)ZIP Lab 攻读计算机科学博士,导师是 Bohan Zhuang 教授和 Jianfei Cai 教授。在此之前,他分别获得阿德莱德大学(University of Adelaide)计算机科学硕士和哈尔滨工业大学(威海)软件工程学士学位。
在博士期间,潘梓正的研究兴趣主要集中在深度神经网络的效率方面,包括模型部署、Transformer 架构优化、注意力机制、 推理加速和内存高效的训练。

Lex Fridman 硬核播客,揭秘中国 AI 新星如何撼动全球格局
就在最近,Lex Fridman 放出了一期长达 5 小时的播客,邀请了 AI2 的模型训练专家 Nathan Lambert 和 Semianalysis 硬件专家 Dylan Patel。
在这期信息量爆棚的谈话中,他们全程聚焦 DeepSeek,讨论了这颗中国 AI 新星如何撼动全球格局、MoE 架构 +MLA 的技术双刃、DeepSeek 开源倒逼行业开放进程、中国式极限优化之道的硬件魔术等。

DeepSeek 到底用没用 OpenAI 数据
这次,几位大佬的谈话内容可谓相当犀利,直指问题核心。
比如这个关键问题:DeepSeek 究竟用没用 OpenAI 的数据?
此前,OpenAI 公开表示,DeepSeek 使用了自家的模型蒸馏。

《金融时报》干脆说,「OpenAI 有证据表明 DeepSeek 用了他们的模型来进行训练」
这在道德和法律上站得住脚吗?
虽然 OpenAI 的服务条款规定,不许用户使用自家模型的输出来构建竞争对手。但这个所谓的规则,其实正是 OpenAI 虚伪的体现。
Lex Fridman 表示:他们和大多数公司一样,本来就是在未经许可的情况下,使用互联网上的数据进行训练,并从中受益的。
大佬们一致认为,OpenAI 声称 DeepSeek 用其模型训练,就是在试图转移话题、让自己独赢。
而且,过去几天还有很多人把 DeepSeek 的模型蒸馏到 Llama 中,因前者在推理上运行很复杂,而 Llama 很容易提供服务,这违法吗?

DeepSeek 的训练成本,为何如此之低
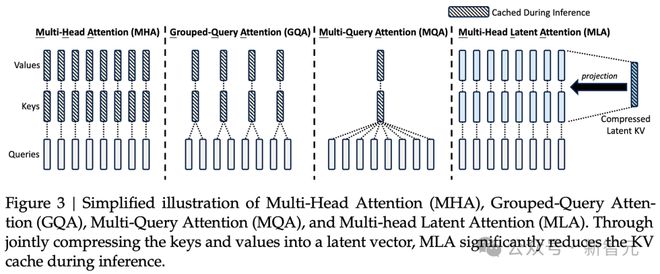
Dylan Patel 表示,DeepSeek 的成本涉及两项关键的技术:一个是 MoE,一个就是 MLA(多头潜注意力)。
MOE 架构的优势在于,一方面,模型可以将数据嵌入到更大的参数空间中,另一方面,在训练或推理时,模型只需要激活其中一部分参数,从而大大提升效率。
DeepSeek 模型拥有超过 6000 亿个参数,相比之下,Llama 405B 有 4050 亿参数。从参数规模上看,DeepSeek 模型拥有更大的信息压缩空间,可以容纳更多的世界知识。
但与此同时,DeepSeek 模型每次只激活约 370 亿个参数。也就是说,在训练或推理过程中,只需要计算 370 亿个参数。相比之下,Llama 405B 模型每次推理却需要激活 4050 亿个参数。
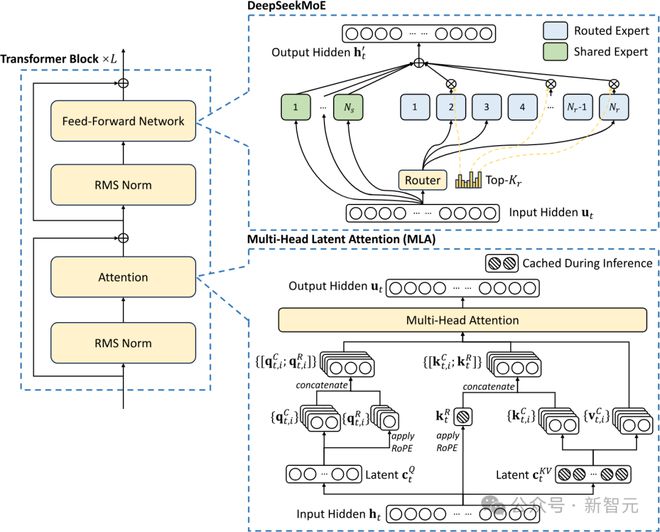
MLA 主要用于减少推理过程中的内存占用,在训练过程也是如此,它利用了一些巧妙的低秩近似数学技巧。
Nathan Lambert 表示,深入研究潜注意力的细节,会发现 DeepSeek 在模型实现方面下了很大功夫。
因为,除了注意力机制,语言模型还有其他组件,例如用于扩展上下文长度的嵌入。DeepSeek 采用的是旋转位置编码(RoPE)。
将 RoPE 与传统的 MoE 结合使用,需要进行一系列操作,例如,将两个注意力矩阵进行复数旋转,这涉及到矩阵乘法。
DeepSeek 的 MLA 架构由于需要一些巧妙的设计,因此实现的复杂性大大增加。而他们成功地将这些技术整合在一起,这表明 DeepSeek 在高效语言模型训练方面走在了前沿。
Dylan Patel 表示,DeepSeek 想方设法提高模型训练效率。其中一个方法就是不直接调用 NVIDIA 的 NCCL 库,而是自行调度 GPU 之间的通信。
DeepSeek 的独特之处在于,他们通过调度特定的 SM(流式多处理器)来管理 GPU 通信。
DeepSeek 会精细地控制哪些 SM 核心负责模型计算,哪些核心负责 allreduce 或 allgather 通信,并在它们之间进行动态切换。这需要极其高深的编程技巧。
DeepSeek 为何如此便宜
在所有声称提供 R1 服务的公司中,定价都远高于 DeepSeek API,而且大多服务无法正常工作,吞吐量极低。
让大佬们震惊的是,一方面中国取得了这种能力,另一方面价格如此之低。(R1 的价格,比 o1 便宜 27 倍)
训练为什么便宜,上文已经提到。为什么推理成本也这么低呢?
首先,就是 DeepSeek 在模型架构上的创新。MLA 这种全新的注意力机制,跟 Transformer 注意力机制不同。
这种多头潜注意力,可以将注意力机制的内存占用减少大约 80% 到 90%,尤其有助于处理长上下文。
而且,DeepSeek 和 OpenAI 的服务成本有巨大差异,部分原因是 OpenAI 的利润率非常高,推理的毛利率超过了 75%。
因为 OpenAI 目前是亏损的,在训练上花费了太多,因此推理的利润率很高。
接下来亮点来了,几位大佬放飞想象,猜测这会不会是一种阴谋论:DeepSeek 精心策划了这次发布和定价,做空英伟达和美国公司的股票,配合星际之门的发布……
但这种猜测立马遭到了反驳,Dylan Patel 表示,他们只是赶在农历新年前把产品尽快发布而已,并没有没有打算搞个大的,否则为什么选在圣诞节后一天发布 V3 呢?
中国的工业能力,已经远超美国
美国无疑在 GPU 等芯片领域领先于中国。
不过,对 GPU 出口管制,就能完全阻止中国吗?不太可能。
Dylan Patel 认为,美国政府也清楚地认识到这一点, 而 Nathan Lambert 认为中国会制造自己的芯片。
中国可能拥有更多的人才、更多的 STEM 毕业生、更多的程序员。美国当然也可以利用世界各地的人才,但这未必能让美国有额外的优势。
真正重要的是计算能力。
中国拥有的电力总和,数量已经惊人。中国的钢铁厂,其规模相当于整个美国工业的总和,此外还有需要庞大电力的铝厂。
即使美国的星际之门真的建成,达到 2 吉瓦电力,仍小于中国最大的工业设施。

就这么说吧,如果中国建造世界上最大的数据中心,只要有芯片,马上就能做到。 所以这只是一个时间问题,而不是能力问题。
现在,发电、输电、变电站以及变压器等构建数据中心所需的东西,都将制约美国构建越来越大的训练系统,以及部署越来越多的推理计算能力。
相比之下,如果中国继续坚信 Scaling Law,就像纳德拉、扎克伯格和劈柴等美国高管那样,甚至可以比美国更快地实现。
因此,为了减缓中国 AI 技术的发展,确保 AGI 无法被大规模训练,美国出台了一系列禁令——通过限制 GPU、光刻机等关键要素的出口,意图「封杀」整个半导体产业。
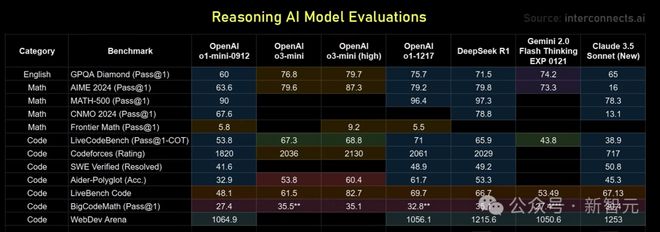
OpenAI o3-Mini 能追上 DeepSeek R1 吗?
接下来,几位大佬对几个明星推理模型进行了实测。

有趣的是,谷歌的 Gemini Flash Thinking,无论从价格还是性能上来看都优于 R1,而且在去年 12 月初就发布了,然而却无人关心……
对此,几位大佬的体感是,它的行为模式不如 o1 那样富有表现力,应用场景较窄。o1 在特定任务上可能不是最完美,但灵活性和通用性更强。
Lex Frieman 则表示,自己个人非常喜欢 R1 的一点,是它会展示完整的思维链 token。
在开放式的哲学问题中,我们作为能欣赏智能、推理和反思能力的人类,阅读 R1 的原始思维链 token,会感受到一种独特的美感。
这种非线性的思维过程,类似于詹姆斯·乔伊斯的意识流小说《尤利西斯》和《芬尼根的守灵夜》,令人着迷。

相比之下,o3-mini 给人的感觉是聪明、快速,但缺乏亮点,往往比较平庸,缺乏深度和新意。
从下图中可以看到,从 GPT-3 到 GPT-3.5,再到 Llama,推理成本呈指数级下降趋势。
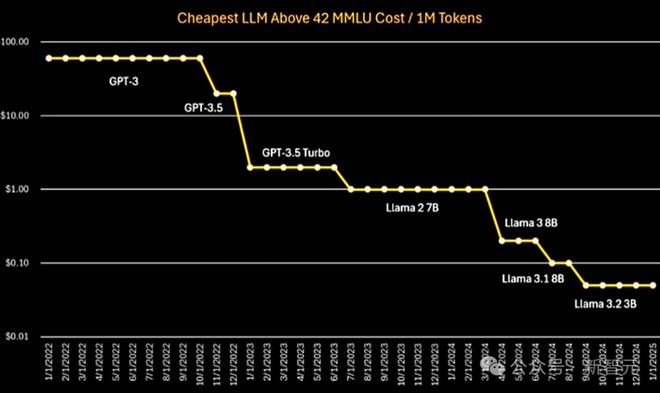
DeepSeek R1 是第一个达到如此低成本的推理模型,这个成就很了不起,不过,它的成本水平并没有超出专家们预期的范围。
而在未来,随着模型架构的创新、更高质量的训练数据、更先进的训练技术,以及更高效的推理系统和硬件(比如新一代 GPU 和 ASIC 芯片),AI 模型的推理成本还会持续下降。
最终,这将解锁 AGI 的潜力。
谁将赢得 AGI 竞赛
最后,几位大佬预测了一番,谁将是 AGI 竞赛的最终赢家。
谷歌似乎是领跑者,因为拥有基础设施优势。
但在舆论场上,OpenAI 似乎是领先者。它在商业化方面已经走在了最前面,拥有目前 AI 领域最高的收入。
目前,谁究竟在 AI 领域赚到钱了,有人盈利了吗?

大佬们盘了盘后发现,从财务报表上看,微软在 AI 领域已经实现了盈利,但在基础设施方面已经投入了巨额资本支出。谷歌、亚马逊也是如此。
Meta 获取的巨额利润来自于推荐系统,并非来自 Llama 等大模型。
Anthropic 和 OpenAI 显然还没盈利,否则就不需要继续融资了。不过单从营收和成本来看,GPT-4 已经开始盈利了,因为它的训练成本只有几亿美元。
最终,谁都无法预料,OpenAI 是否会突然陨落。不过目前,各家公司还会继续融资,因为一旦 AGI 到来,AI 带来的回报难以估量。
人们可能并不需要 OpenAI 花费数十亿美元,去研发「下一个最先进的模型」,只需要 ChatGPT 级别的 AI 服务就足够了。
推理、代码生成、AI 智能体、计算机使用,这些都是 AI 未来真正有价值的应用领域。谁不发力,谁就可能被市场淘汰。
参考资料:






