
【新智元导读】「ChatGPT 搜索」人人都能用了,而且还是无需登录的那种!
新智元报道
编辑:编辑部 JHs
刚刚,ChatGPT 搜索人人可用,登上热搜!

就在今天,OpenAI 紧跟着谷歌 Gemini 2.0 的发布,把 ChatGPT Search 给全面开放了。
不需要注册登录,用法和传统搜索引擎一样。
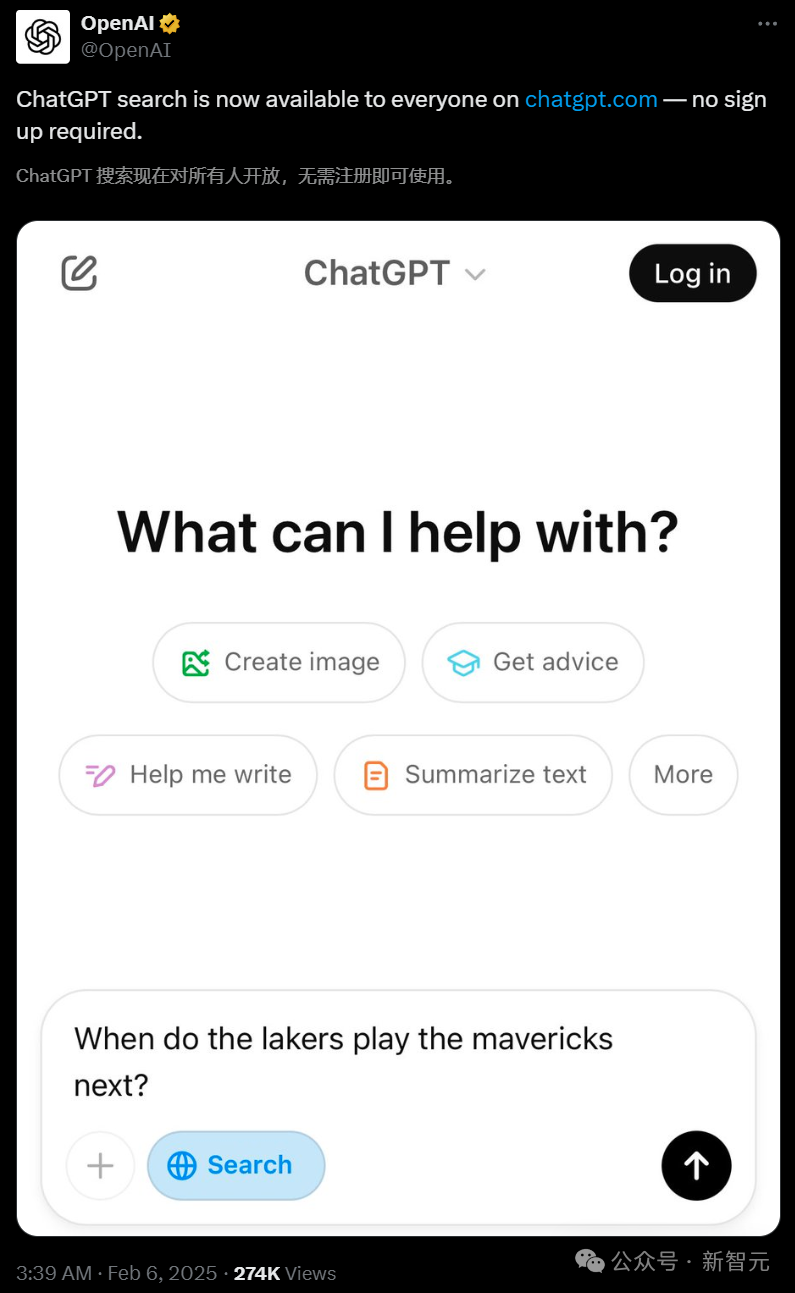
ChatGPT Search:免费体验,无需注册
一直以来,OpenAI 都在模型上领先谷歌一步,如今更是直接在谷歌的发家地「搜索领域」发起了冲锋——
不仅完全学习谷歌搜索的免注册模式,而且相关链接还以类似搜索引擎的方式呈现。
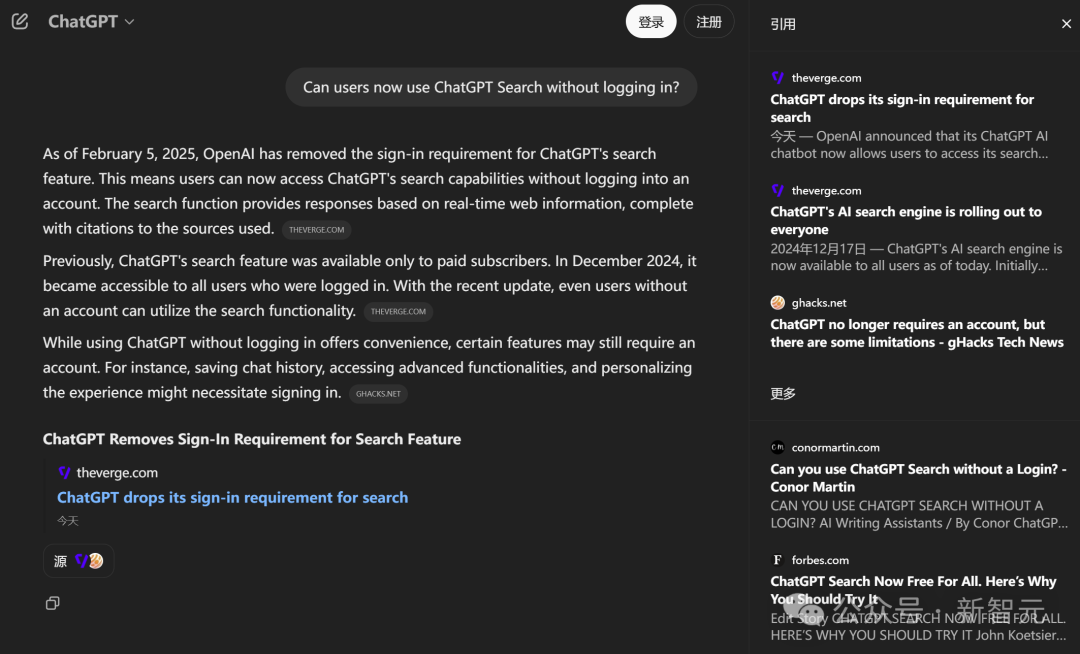
只需在网页版上点击搜索按钮,ChatGPT 就会从互联网上搜索相关信息,包括图片和链接,并在回答时标明信息来源
正如上面 ChatGPT 回答的,早在去年 10 月,OpenAI 就向付费订阅用户推出了搜索引擎功能;同年 12 月,进一步推广给了所有的注册用户。
这次的关键在于:网页版搜索功能,不需要账户,不要登录,和普通网站一样,只要能上网,就能使用 ChatGPT 的搜索功能!
根据搜索引擎优化公司 Semrush 的最新报告,尽管 Google 的搜索用户仍然比 ChatGPT 多出数十亿,但 ChatGPT 真正重塑用户的搜索行为,开始向教育和技术等网站发送越来越多的搜索流量。

ChatGPT 正在蚕食传统搜索引擎市场。
Semrush 的分析发现,ChatGPT 提示中,70% 是独特的,在传统搜索引擎中很少或根本没有见过。
即便在传统的网站类型上, ChatGPT 也有独特的优势:
从 ChatGPT 获得的流量超越 Google 的网站类型包括:与 OpenAI 相关的域名、技术和 AI 平台。
从 ChatGPT 获得的流量超越 Microsoft Bing 的网站类型包括:学术出版商和研究资源,以及教育和技术资源。
截至 2024 年 12 月,在用户数量上,Google 拥有 65 亿独立访客,而 ChatGPT 的独立访客为 5.66 亿。
Semrush 还对受众人口统计进行了对比,发现:
-
ChatGPT 用户较年轻,男性用户居多。
-
ChatGPT 在学生群体中占有优势,而 Google 更受全职工作者、家庭主妇和退休人员的青睐。
考虑到这次 ChatGPT 免登录的新策略,ChatGPT 搜索的访客数量很可能迎来「井喷」!
网友认为谷歌搜索的丧钟,这次可能真的要敲响了。

不止 OpenAI 在做搜索。国内外的 AI 公司,垂涎网络搜索市场已久。
但尚未盈利的 OpenAI,怎么突然免费开放如此重要的功能?
一种可能的解释是,这得益于开源的 DeepSeek 带来的挑战。
300+ 名博士,100 美金/小时,为 AI 打工
除了开放 ChatGPT 搜索之外,OpenAI 还被爆出向博士支付 100 美金/小时,提升模型推理的质量。

比如向众多生物学博士, OpenAI 提出下列问题:
请总结 2024 年 8 月前可用的湿实验方法,将这些方法用于并行评估人类非编码调控 DNA 序列(如启动子和增强子)中多个不同变体对基因表达的影响。
对于每种方法,需说明基因表达的测量方式、变体的识别方法,阐述引入变异的相关方法,并指出每种方法的主要优势和局限性。
若预算在 50,000 美元以下,哪种方法最适合测试数百个不同调控元件中的数千个冠心病相关单核苷酸多态性(SNP) ?
这种博士级问题的问题不限于生物学领域。
据透露,OpenAI 为提升模型处理客户问题的能力,向医学、法律、语言学、计算机科学、物理学等领域提出博士级问题。
OpenAI 会向至少 300 人,每人每小时支付 100 美元报酬,每个问题平均耗时约两小时。OpenAI 利用这些答案,帮助模型学会处理客户提出的类似问题。
Scale AI、Turing 和 Invisible 等公司,也招募经验丰富的程序员或博士,协助 OpenAI、Google、Anthropic 和 xAI 等公司,在 AI 开发的后训练阶段提高模型质量,并借此获得可观收入。
DeepSeek:AI 模型也可以
上周,DeepSeek-R1 惊艳亮相,这或许会给 Scale 这类公司带来变革。
DeepSeek 研究人员称,他们利用 AI 模型而非人力,低成本地生成和解决编程与数学问题。
伯克利的研究人员也用 450 美元达成同样成果,这进一步证实了 DeepSeek 的说法。
这种用 AI 生成数据训练其他 AI 的方式,促使与 Scale 竞争的另一家后训练阶段公司 Labelbox,开始思考商业模式的潜在变革。
Labelbox 首席执行官 Manu Sharma 指出,OpenAI、Google 等 AI 开发公司,交给 Labelbox 等公司协助完成的任务难度正在不断增加。
一年半前,AI 实验室希望模型能从优质英文博客文章中学习。如今,AI 模型已基本掌握这类写作技能,开发者们的关注点也转移到解决复杂编程和数学问题等技能上。
DeepSeek 的创新成果让一些基础编程和数学问题,能由 AI 自行生成和检验。不过,仍有不少极具挑战性的任务,AI 还无法生成训练数据。
AI:有些任务太难了
当前,AI 在跨领域任务上存在困难,比如设计新型火箭飞船,这需要综合运用物理学、数学和机械工程等多方面知识。在药物研发、法律等没有标准答案的领域,AI 的表现也不够理想。
AI 模型在其他方面也存在短板。
目前的 AI 不擅长提出确认性问题,也不善于使用多个工具来获得答案。也就是说,在预订餐厅时,AI 不太会核实用户所在的城市;在编写代码,AI 也不善于使用谷歌搜索获取信息。
Scale 的区域首席技术官(Field CTO )Vijay Karunamurthy 表示,Scale 正在帮助 AI 研究实验室生成训练数据,以改进这两方面的能力。

有时候,模型传达答案的方式与答案本身的正确性,同样重要。
例如,模型需要向患者解释医疗诊断结果时,需要「高情商」的沟通技巧。
Karunamurthy 指出:「人类可以帮助模型学习这种细微的沟通技巧」。
后训练产业变革
Labelbox 首席执行官 Manu Sharma 表示,为了确保工作质量和安全性,像 OpenAI 这样的 AI 公司,越来越多地后训练阶段的工作被转移到公司内部。
而且他们更倾向于,将 Labelbox 等公司作为人才招聘平台,直接雇用并与专家合作,而不是将工作完全外包出去。

Scale 似乎也在顺应这一趋势。
今年 11 月,Scale 公司宣布开始测试「专家匹配」(Expert Match)系统。
研究实验室利用此系统,能够在 Scale 的专家网络中搜索、筛选并邀请专家参与数据治理项目。
Scale 和 Turing 还采取新的发展路径:将 AI 技术整合到咨询公司的业务运营中。
参考资料:
https://x.com/OpenAI/status/1887224584539414983
https://x.com/0xmetaschool/status/1887230376004968693
https://mashable.com/article/chatgpt-web-search-available-all-users-no-account-login-required
https://x.com/steph_palazzolo/status/1887157687000948886
https://www.theinformation.com/articles/will-deepseek-hurt-scale-ais-business-model






