
新智元报道
编辑:编辑部 HNYZ
DeepSeek 开源周第一天就放大招!FlashMLA 强势登场,这是专为英伟达 Hopper GPU 打造 MLA 解码内核。注意,DeepSeek 训练成本极低的两大关键,一个是 MoE,另一个就是 MLA。
就在刚刚,DeepSeek 放出了开源周首日的重磅炸弹——FlashMLA。
这是 DeepSeek 专为英伟达 Hopper GPU 打造的高效 MLA 解码内核,特别针对变长序列进行了优化,目前已正式投产使用。
经实测,FlashMLA 在 H800 SXM5 平台上(CUDA 12.6),在内存受限配置下可达最高 3000GB/s,在计算受限配置下可达峰值 580 TFLOPS。
开源地址:https://github.com/deepseek-ai/FlashMLA
当前已经发布的内容为:
-
对 BF16 精度的支持
-
块大小为 64 的分页 KV 缓存
团队在致谢部分表示,FlashMLA 的设计参考了 FlashAttention-2、FlashAttention-3 以及 CUTLASS 的技术实现。
有网友对此表示,「DeepSeek 王炸开局,FlashMLA 是真正能加速 AGI 进程的」。
快速入门
首先,需要打开终端,输入下面代码安装 setup.py 文件:
这是一个基于 Python 的安装命令,用于编译和安装 FlashMLA 模块,确保其高效运行于特定硬件。
python setup.py install基准测试:
这段代码是一个测试脚本,用于验证 FlashMLA 的功能和性能,并与 PyTorch 的基准实现进行对比。
python tests/test_flash_mla.py使用方法:
下面是一段使用的示例代码。
from flash_mla import get_mla_metadata, flash_mla_with_kvcache tile_scheduler_metadata, num_splits = get_mla_metadata (cache_seqlens, s_q * h_q // h_kv, h_kv) for i in range (num_layers): ... o_i, lse_i = flash_mla_with_kvcache ( q_i, kvcache_i, block_table, cache_seqlens, dv, tile_scheduler_metadata, num_splits, causal=True, ) ...
DeepSeek 训练成本如此之低的两大关键
DeepSeek 的成本涉及两项关键的技术:一个是 MoE,一个就是 MLA(多头潜注意力)。
其中,MLA 的开发耗时数月,可将每个查询 KV 缓存量减少 93.3%,显著减少了推理过程中的内存占用(在训练过程也是如此)。
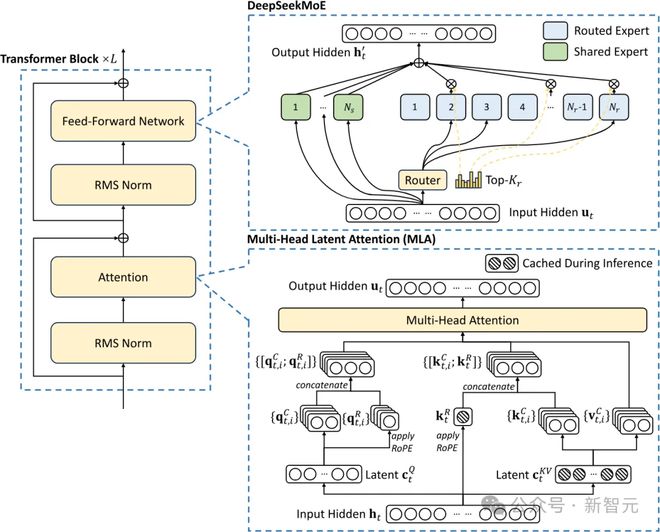
MLA 架构需要一些巧妙的设计,因此实现的复杂性大大增加。而 DeepSeek 成功地将这些技术整合在一起,表明他们在高效语言模型训练方面走在了前沿
多头潜注意力(MLA)
KV 缓存是 Transforme 模型中的一种内存机制,用于存储表示对话上下文的数据,从而减少不必要的计算开销。
随着对话上下文的增长,KV 缓存会不断扩大,从而造成显著的内存限制。
通过大幅减少每次查询所需的 KV 缓存量,可以相应减少每次查询所需的硬件资源,从而降低运营成本。
与标准注意力机制相比,MLA 将每次查询所需的 KV 缓存减少了约 93.3%。
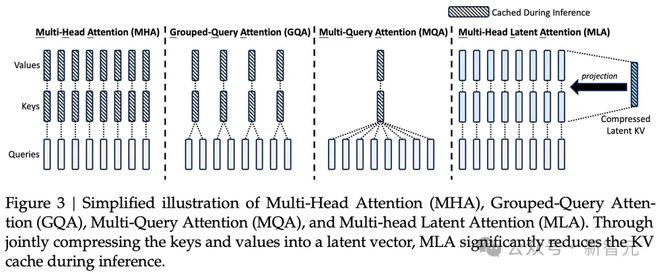
MLA 这种全新多头潜注意力,可以将注意力机制的内存占用减少大约 80% 到 90%,尤其有助于处理长上下文
此外,由于 H20 芯片比 H100 具有更高的内存带宽和容量,DeepSeek 在推理工作负载方面获得了更多效率提升。
除了 MLA,DeepSeek 其他突破性进展还有哪些?
训练(前期和后期)
不是「下一个 token 预测」,而是「多 token 预测」
DeepSeek V3 以前所未见的规模实现了多 Token 预测(MTP)技术,这些新增的注意力模块可以预测接下来的多个 Token,而不是传统的单个 Token。
这显著提高了训练阶段的模型性能,且这些模块可以在推理阶段移除。
这是一个典型的算法创新案例,实现了在更低计算资源消耗下的性能提升。
其他方面,虽然 DeepSeek 在训练中采用了 FP8 精度,但像全球一些顶尖的实验室已经采用这项技术相当长时间了。
DeepSeek V3 采用了我们常见的「混合专家模型」(MoE)架构,个由多个专门处理不同任务的小型专家模型组成的大模型,展现出强大的涌现能力。
MoE 模型面临的主要挑战是,如何确定将哪个 Token 分配给哪个子模型(即「专家」)。
DeepSeek 创新性地采用了一个「门控网络」(gating network),能够高效且平衡地将 Token 路由到相应的专家,同时保持模型性能不受影响。
这意味着路由过程非常高效,在训练过程中每个 Token 只需要调整小量参数(相较于模型整体规模)。
这既提高了训练效率,又降低了推理成本。
尽管有人担心 MoE 带来的效率提升,可能降低投资意愿,但 Dario 指出,更强大的 AI 模型带来的经济效益非常可观,任何节省的成本都会立即被投入到开发更大规模的模型中。
因此,MoE 效率提升不会减少总体投资,反而会加速模型 Scaling 的进程。
当前,包括 OpenAI、谷歌、Anthropic 等一些公司正专注于扩大模型的计算规模,并提高算法效率。
V3 打好了基础,RL 立大功
对于 R1 而言,它极大地受益于其强大的基础模型——V3,这在很大程度上要归功于强化学习(RL)。
RL 主要关注两个方面:格式化(确保输出连贯性)以及有用性与安全性(确保模型实用且无害)。
模型的推理能力,是在对合成数据集进行微调过程中自然涌现的,这与 o1 的情况类似。
值得注意的是,R1 论文中并没有提及具体的计算量,因为披露使用的计算资源,会暴露 DeepSeek 实际拥有的 GPU 数量远超过其对外宣称的规模。
这种规模的强化学习需要庞大的计算资源,特别是在生成合成数据时。
谈到蒸馏,R1 论文最引人注目的发现可能是,通过具有推理能力的模型输出来微调较小的非推理模型,使其获得推理能力。
数据集包含了约 80 万个样本,现在研究人员可以利用 R1 的思维链(CoT)输出创建自己的数据集,并借此开发具有推理能力的模型。
未来,我们可能会看到更多小模型展现出推理能力,从而提升小模型的整体性能。
参考资料:






