
新智元报道
编辑:编辑部 HNYs
Phi-4 系列模型上新了!56 亿参数 Phi-4-multimodal 集语音、视觉、文本多模态于一体,读图推理性能碾压 GPT-4o;另一款 38 亿参数 Phi-4-mini 在推理、数学、编程等任务中超越了参数更大的 LLM,支持 128K token 上下文。
今天,微软 CEO 纳德拉官宣,Phi 系列家族新增两员:Phi-4-multimodal 和 Phi-4-mini。

这是微软 Phi 系列小模型(SLM)中的最新模型,尤其是 Phi-4-multimodal 是微软的首款多模态模型。
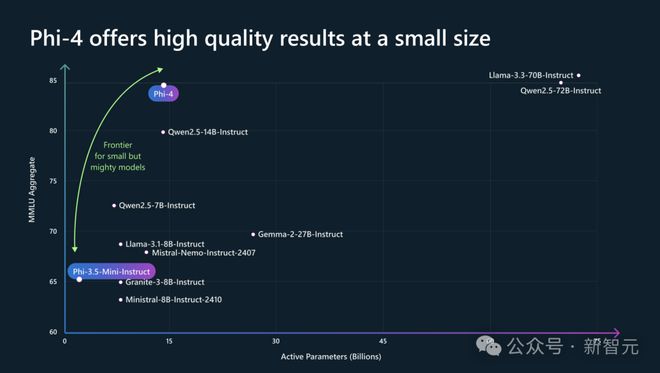
这两款模型虽然参数不大(56 亿和 38 亿),但性能强劲,甚至不输一些大型的开源模型,例如 Llama-3.3-70B-Instruct、Qwen2.5-72B-Instruct。
其中,Phi-4-multimodal 是一款单体模型,采用混合 LoRA 技术,集成了语音、视觉和文本多模态能力,皆可在同一表示空间内同时处理。
Phi-4-mini 支持 128k 上下文,还可以借用函数调用功能,在基于文本的任务中表现出色,以紧凑的形式提供了高精度和可扩展性。
与此同时,Phi-4 新款模型 39 页技术报告新鲜出炉了。

值得一提的是,Phi-4-mini 在 Math-500 数学测试集中,拿下了 90.4 分惊人的成绩,与蒸馏千问 7B 后的 DeepSeek R1、o1-mini 不相上下。

现在,Phi-4-multimodal 可以在 Azure AI Foundry、HuggingFace 和 NVIDIA API Catalog 中使用,开发者可以在 NVIDIA API Catalog 上探索 Phi-4-multimodal 的全部潜力,从而轻松地进行实验和创新。

传送门:https://huggingface.co/microsoft/Phi-4-multimodal-instruct
Phi-4-multimodal,微软首个多模态
Phi-4-multimodal 作为微软首个全模态语言模型,标志着微软人工智能开发的一个新里程碑。
它是一个 56 亿参数的模型,将语音、视觉和文本处理无缝集成到一个统一的架构中。
通过利用先进的跨模态学习技术,该模型实现了更自然、更具上下文感知能力的交互,使设备能够同时理解和推理多种输入模态。
无论是解释口语、分析图像还是处理文本信息,它都能提供高效、低延迟的推理——同时还针对设备端执行和减少计算开销进行了优化。
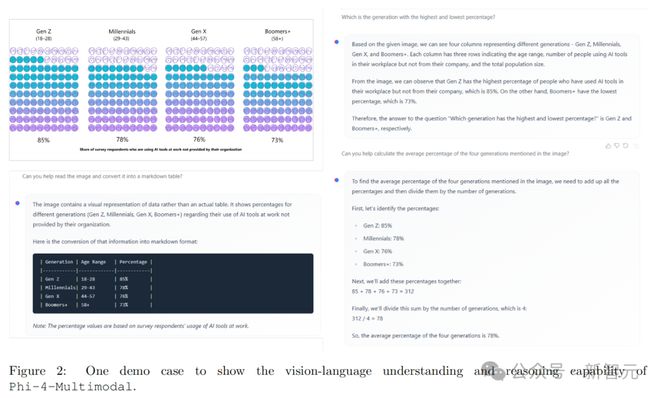
举个栗子,上传一张与不同时代(Z世代、千禧一代、X世代、婴儿潮一代等)在工作中使用非组织提供的 AI 工具的百分比图像。
Phi-4-multimodal 看懂图之后,就能帮你出一个 Markdown 形式的表格,并且与之相关的问题均可以答对。
原生支持多模态
Phi-4-multimodal 是一个单一模型,采用了混合 LoRA(Low-Rank Adaptation)技术,集成了语音、视觉和语言功能,所有这些都在同一个表示空间内同时处理。
其结果是一个统一的单一模型,能够处理文本、音频和视觉输入,无需复杂的处理流程或为不同模态使用单独的模型。
Phi-4-multimodal 基于一种全新的架构,显著提升了效率和可扩展性。它拥有更大的词汇量以改进处理能力,支持多语言功能,并将语言推理与多模态输入相结合。所有这些都集成在一个强大、紧凑且高效的模型中,非常适合在设备端和边缘计算平台上部署。
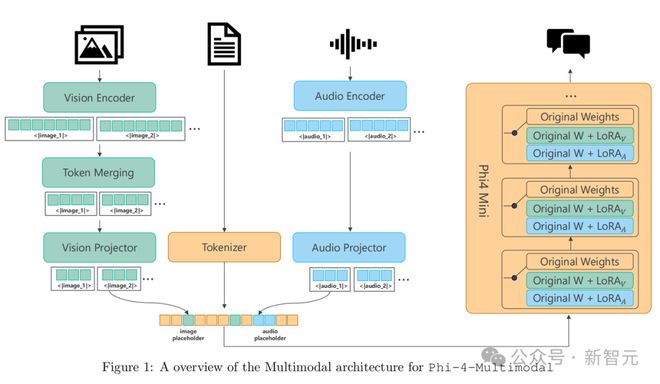
Phi-4-multimodal 整体架构
解锁新能力
Phi-4-multimodal 能够同时处理视觉和音频内容。
下图 1 展示了当视觉内容的输入为合成语音时,模型在图表/表格理解和文档推理任务上的表现。与其他现有的能够同时处理音频和视觉信号作为输入的最先进多模态模型相比,Phi-4-multimodal 在多项基准测试中取得了显著更强的性能。

Phi-4-Multimodal-Instruct 音频和视觉基准
Phi-4-multimodal 在语音相关任务中展现了卓越的能力,成为多个领域的领先开源模型。
它在自动语音识别 (ASR) 和语音翻译 (ST) 方面超越了 WhisperV3 和 SeamlessM4T-v2-Large 等专业模型。该模型以惊人的 6.14% 词错误率登顶 Huggingface OpenASR 排行榜,超过了截至 2025 年 2 月之前的最佳表现 6.5%。
此外,Phi-4-multimodal 是少数成功实现语音摘要并达到与 GPT-4o 模型相当性能水平的开源模型之一。
在语音问答 (QA) 任务中,该模型与 Gemini-2.0-Flash 和 GPT-4o-realtime-preview 等相近模型存在差距,因为其较小的模型规模导致事实性问答知识的能力较弱。
下图 2 比较了不同 AI 模型在语音识别、语音翻译、语音问答、音频理解和语音摘要等类别中的表现。模型包括 Phi-1-Multimodal-Instruct、Qwen-2-Audio、WhisperV3、SeamlessM4T-V2-Large、Gemini-2.0-Flash 和 GPT-4-turbo-preview-10-01-2024。
Phi-4-Multimodal-Instruct 在语音识别和翻译中表现优异,而 Gemini-2.0-Flash 和 GPT-4o-RT-preview 在问答和音频理解任务中领先。
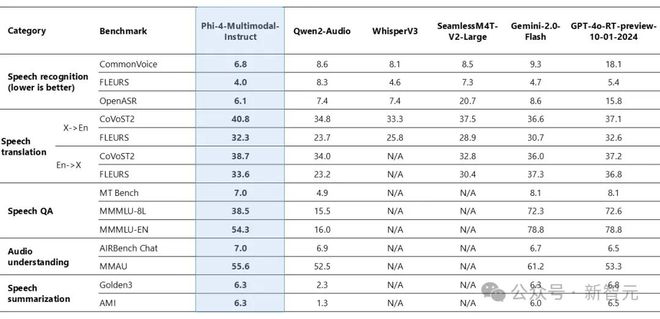
图2:Phi-4-Multimodal-Instruct 语音基准测试
以下视频为 Phi-4 Multimodal 分析口语语言,以帮助规划前往西雅图的旅行,展示了其先进的音频处理和推荐能力。
![]()
Phi-4-multimodal 仅拥有 56 亿个参数,却在多个基准测试中展现了卓越的视觉能力,尤其在数学和科学推理方面表现突出。
尽管其规模较小,该模型在通用多模态能力上仍保持竞争力,例如文档和图表理解、光学字符识别 (OCR) 以及视觉科学推理,甚至超过了 Gemini-2-Flash-lite-preview 和 Claude-3.5-Sonnet 等模型。
如下图 3 所示,Phi-4-Multimodal-Instruct 在多个任务中表现出色,如 MMMU (55.1)、ScienceQA (97.5) 和 ChartQA (81.4),而 GPT-4o 和 Gemini-2.0-Flash 在综合性能上得分较高。
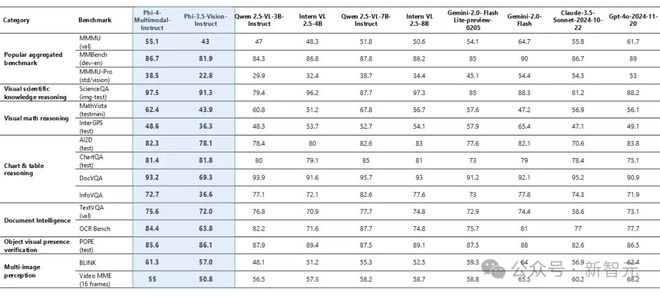
图3:Phi-4-Multimodal-Instruct 视觉基准测试
以下视频为 Phi-4-Multimodal 如何通过视觉输入解决复杂的数学问题,展示了其处理和解决图像中呈现的方程的能力。
Phi-4-mini 拥有 38 亿参数,它是一个稠密、仅包含解码器的 Transformer 模型,具有分组查询注意力、20 万词汇量和共享输入输出嵌入,旨在提高速度和效率。
尽管规模小巧,但在推理、数学、编程、指令跟随和函数调用等任务中,它的表现优于更大的模型。
该模型支持长达 128K token 的序列,提供高精度和可扩展性,使其成为先进 AI 应用的强大解决方案。
为了了解模型质量,微软将 Phi-4-mini 与一系列模型在如下图 4 所示的多个基准上进行比较。
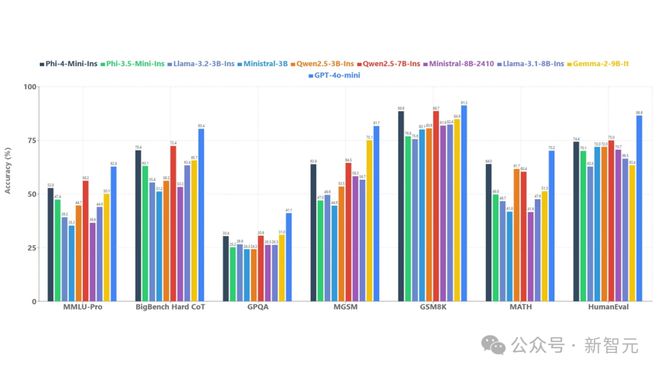
Phi-4-mini 语言基准测试
在多种基准测试中,Phi-4-mini 展现出了出色的性能。函数调用、指令跟随、长上下文处理和推理等强大能力,使它能够访问外部知识和功能。
通过标准化协议,函数调用使模型能够与结构化编程接口无缝集成,当用户发出请求时,它可以对查询进行推理,识别并调用带有适当参数的相关函数,接收函数输出,并将这些结果融入到响应中,创建了一个基于智能体的可扩展的系统。
定制化与跨平台
Phi-4-mini 和 Phi-4-multimodal 模型的规模较小,这一特点让它们能在计算资源有限的推理环境中使用。
在设备端,通过 ONNX Runtime 进一步优化后,两款模型可以跨平台使用。它们对计算资源需求低,延迟表现也更理想。
同时,模型拥有更长的上下文窗口,推理和逻辑能力强大,非常适合用于分析任务。较小的模型规模让微调或定制变得更轻松,成本也更低。
下表是 Phi-4-multimodal 在微调场景中的示例。

小模型,跑起来了
从一开始,微软设计 Phi 系列模型的初衷,便是加速 SLM 实际落地应用。
而如今,有了多模态 Phi-4-multimodal,以及参数更少、数推更强的 Phi-4-mini,又能赋能一大片应用了。
嵌入智能设备
手机制造商可以将 Phi-4-multimodal 直接集成到手机中,用户可以使用先进功能,如实时语言翻译、增强的照片和视频分析,能理解并回应复杂查询的智能个人助理。
这将在手机上直接提供强大的 AI 能力,提升用户体验,确保低延迟和高效率。
汽车领域
汽车公司将模型集成到车载辅助系统中,车辆可以理解并回应语音指令、识别驾驶员手势,以及分析来自摄像头的视觉输入。
它可以通过面部识别检测驾驶员的疲劳状态并提供实时警报,从而提高驾驶安全性。
此外,它还能提供无缝的导航辅助、解读路标并提供情境信息,在联网及离线状态下,都能创造更直观、更安全的驾驶体验。
金融服务
金融服务公司集成 Phi-4-mini 模型,以实现复杂金融计算的自动化、生成详细报告,并翻译成多种语言。
例如,该模型可以通过执行风险评估、投资组合管理和财务预测所需的复杂数学计算,为分析师提供帮助。
此外,它还能将财务报表、监管文件和客户沟通内容翻译成多种语言,有助于改善全球客户关系。
以下视频为 Phi-4-mini 作为智能体的功能,展示了其在复杂场景中的推理和任务执行能力。
微软 19 年老将,LoRA 核心缔造者带队
作为微软副总裁和 GenAI 团队负责人,19 年老将 Weizhu Chen 的研究为 AI 领域带来了多项突破性贡献,包括 LoRA、DeBERTa、Phi 和 Rho-1 等技术。
他开创的 LoRA 技术革新了大语言模型的应用方式,使其更加高效、经济且易于部署,不仅为众多微软产品提供了强大支持,还对整个行业产生了深远影响。
在微软,他的工作让公司能够为特定产品场景训练专业模型,尤其专注于 OpenAI 模型的应用。并且,还为 Azure AI、GitHub、Office、Biz Apps、MAI、DevDiv 和 Security 等多个产品部门创造了显著的业务价值。
比如在 2022 年共同推出的 GitHub Copilot,就一举成为了微软首个极为成功的 Copilot 产品。
同时,他还将 BerryRL 流程整合到微软产品中的工作,显著提升了 Codex-V2 和 SWE-Agent 等多个应用的模型训练效率和质量。
在此之前,他在香港科技大学获得计算机科学博士学位。


参考资料:
https://azure.microsoft.com/en-us/blog/empowering-innovation-the-next-generation-of-the-phi-family/






