
北京时间 2 月 28 日凌晨,OpenAI 发布 GPT-4.5。“这是我们迄今为止最大、最好的聊天模型,是在扩大预训练和后训练道路上迈出的一步。” OpenAI 介绍,这款新模型面向 GPT Pro 用户,下周起将向 Plus 用户和 Team 用户推出。
OpenAI CEO 山姆·奥尔特曼(Sam Altman)因为“在医院照顾孩子”并没有出现在发布现场,但他在X上发布了帖子造势,强调 GPT-4.5 是一个“高情商”更像人的模型,不会超越基准测试,是一种“不同类型的智能”。
从目前业界的反应来看,这一代模型的能力提升并不算大,但令人惊讶的是 GPT-4.5 的价格,每百万 Tokens 输入为 75 美元,相比 GPT-4o 的 2.5 美元上涨 30 倍,同时,OpenAI 表示,GPT-4.5 无法完全替代 GPT-4o。
与此同时,DeepSeek 26 日刚在海内外宣布了 API 错峰时间段的降价,V3 模型和 R1 模型的每百万 Tokens 输入只要 0.035 美元,相比原价分别下调 50% 和 75%,GPT-4.5 是这个价格的 2000 多倍。就在 28 日,DeepSeek 还放出了“开源周”最后一个代码库,将开源进行到底,这一搅动 AI 圈的“鲶鱼”,正在改写 AI 竞争格局。
好消息和坏消息
GPT-4.5 是奥尔特曼此前预告将“在几周内”发布的模型。奥尔特曼彼时称,除了发布 GPT-4.5,几个月时间内 OpenAI 还将发布下一代基座模型 GPT-5。如此看,GPT-4.5 很可能是 GPT-5 面世前的最后一个过渡模型。
与 OpenAI 此前发布新模型时的惯常做法不同,此前 OpenAI 通常会强调新模型在各领域的基准测试分数,此次 OpenAI 则表示,学术基准并不总是反映现实世界的有用性,OpenAI 转而强调了 GPT-4.5 的“情商”。
奥尔特曼在发帖中提到了“好消息”和“坏消息”,前者是,“这是第一个让人感觉像是在跟一个有思想的人说话的模型。”他表示,曾多次惊讶地发现能从人工智能那里得到很好的建议。
坏消息则是,“这是一个庞大而昂贵的模型”,甚至没办法同时推到 plus 用户那里,奥尔特曼表示,“GPU 已经不够了”,下周将添加数万个 GPU,然后将其推广到 plus。
奥尔特曼还特别提到,GPT-4.5 不是一个推理模型,也不会在基准测试中取得压倒性优势。它是一种“不同类型的智能”。在新模型发布前不久,OpenAI 首席研究官 Mark Chen 接受播客采访称,新模型并未被命名为 GPT-5,这是因为 OpenAI 内部对这款模型的评估还没有到达整整一代的性能提升。
OpenAI 表示,早期测试表明,用户与 GPT-4.5 交互更自然,该模型有更广泛的知识基础、理解用户意图的更强能力和更强大的“情商”,这使得 GPT-4.5 在写作、编程、解决实际问题等任务上很有用。在训练过程中,OpenAI 则使用了扩大(Scaling)无监督学习和推理的方法。
OpenAI 特别强调了 GPT-4.5 幻觉率降低、与人类协作表现更佳。OpenAI 通过用简单但具有挑战性的知识问题测试模型,结果显示,GPT-4.5 的幻觉率为 37.1%,低于 GPT-4o 的 61.8%、o1 的 44%、o3-mini 的 80.3%。在与人类协作的能力方面,OpenAI 称,GPT-4.5 在日常查询、专业查询、创造性智能这 3 个方面表现都比 GPT-4o 更强,GPT-4.5 能更好地理解人类微妙的暗示或隐含的期望。
为了展示 GPT-4.5 的能力,OpenAI 举了个例子。问 GPT-4.5“世界上第一种语言是什么”,GPT4.5 的回答是“我们不知道确切的第一种语言是什么,科学家认为我们可能永远不知道确切的答案,因为口语的出现远早于书面记录”,并解释了没有单一的第一种语言、口语可能最早在非洲出现。
同样的问题问 GPT-4 的 4T 版本,回答则是“确定人类使用的第一种语言极具挑战性”,并解释称,语言学家假设有许多语言的共同祖先,但这种祖先不是第一种语言。直观感受上,GPT-4.5 的表达更接近人类,GPT-4T 的语言表达显得有些机械。
此外,OpenAI 还强调了 GPT-4.5 与 o1 这类长思维链推理模型不同。例如,GPT-4.5 在做出反应前不需要经过思考,因此更通用,也更智能。不过,OpenAI 也说明,推理仍将是未来模型的核心能力,更强的推理能力即将出现。
在附录部分,OpenAI 才放出 GPT-4.5 的基准测试分数。在反映科学、数学、多语言、编码的 GPQA、AIME’24、MMMLU、SWE-Lancer 基准测试上,GPT-4.5 得分分别为 71.4%、36.7%、85.1%、32.6%,超过 GPT-4o 的 53.6%、9.3%、81.5%、23.3%,但部分得分低于 o3-mini。
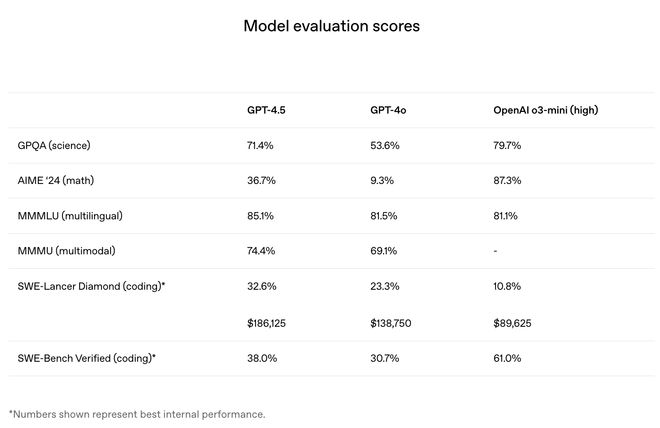
这一代的能力提升并不明显,而与此相对的是,能力定价上,GPT-4.5 预览版的 API 调用价格为每百万 Tokens 输入(input)75 美元,输出(output)150 美元,分别是 GPT-4o 价格的 30 倍、15 倍。

即便相比自家模型,这个价格也过于昂贵,而进一步与 DeepSeek 进行对比,差距更大。近期非波峰时间段,V3 模型和 R1 模型的每百万 Tokens 输入为 0.035 美元(原价分别是 0.07 美元/0.14 美元),每百万 token Tokens 输出只需要 0.55 美元(原价分别是 1.1 美元/2.19 美元),GPT-4.5 分别是上述价格的 2000 多倍和 270 多倍。
OpenAI 说明,由于 GPT-4.5 是一个非常大且计算密集的模型,所以价格比 GPT-4o 更贵。同时,OpenAI 提到 GPT-4.5 还无法完全替代 GPT-4o。考虑到要在支持现有功能和开发未来的模型之间取得平衡,OpenAI 还在评估是否长期在 API(接口)使用该模型。
“鲶鱼”搅动 AI 圈
除了拼性价比,DeepSeek 另一个方向是坚定开源路线。
就在 OpenAI 新品发布的这一天,DeepSeek 正进行着本周第五项代码开源——Fire-Flyer 文件系统(3FS)。它是“所有 DeepSeek 数据访问的动力引擎”,一个高性能的并行文件系统,专门优化 AI 数据访问,为 AI 工作负载提供卓越的存储基础设施。
据 DeepSeek,3FS 是专为 AI 场景设计的高性能存储解决方案,通过架构创新和硬件适配显著提升了数据处理效率,与传统的云存储挂载工具(如 s3fs)在目标场景和技术实现上存在显著差异。
除了 3FS,DeepSeek 本周陆续开源了让大模型在 GPU 上跑得更快的 MLA 解码核 FlashMLA,用于 MoE 模型训练和推理的 DeepEP 通信库,可支持 MoE 的 FP8 GEMM 代码库 DeepGEMM,一系列优化并行策略等底层代码,在 GitHub 上,DeepSeek 详细展开了 DeepSeek-V3 和 R1 模型背后的优化技术,教社区如何最大限度利用 GPU 能力。
“相当于以前 DeepSeek 是直接给一辆车,告诉大家这辆车续航 900 公里,但是现在 DeepSeek 在深挖,用什么方式能够开到 900 公里。”大模型生态社区 OpenCSG(开放传神)创始人陈冉此前对第一财经举例表示。
陈冉认为,DeepSeek 现在发布的算法某种意义上属于“脚手架”, 这些“脚手架”的开源有利于之后的生态搭建。社区和开发者可以基于 DeepSeek 的技术路线继续往前走,最终行业能基于此将生态做起来。
长期来看,DeepSeek 这一开源动作的意义在于,有模型标准,也有工具标准,也有生态基石,生态就能长起来。也有从业者认为,如果把大模型比作更底层的操作系统,那 OpenAI 可能是相对封闭的 IOS 生态,而 DeepSeek 就是开放的安卓。
DeepSeek 或许改写了 AI 圈的竞争格局和方向。奥尔特曼在 2 月 o3-mini 发布当天表示,OpenAI 的开源政策站在了“历史错误的一边”,需要想出一个不同的开源策略。
在国内,一贯坚持闭源路线的百度也“倒戈”向开源。去年,百度董事长李彦宏还表示,大模型开源的意义不大,闭源模型在能力上会持续领先。今年 2 月 14 日,百度就宣布将在未来几个月陆续推出文心大模型 4.5 系列,并于 6 月 30 日正式开源。
从开源的冲击看,能力不如开源模型的闭源模型面临尴尬境地。既然开源模型可以被开发者自行下载、微调乃至私有化部署,就不需要为了使用闭源大模型付费了。
DeepSeek 将算力用到极致,在低成本的基础上进行模型的训练和推理,此前也一度带崩芯片股,将压力给到海外大厂,规模越来越大的数据中心相关资本支出是否合理?这成为投资人对大厂的疑虑。
1 月以来,海外 AI 巨头近期新品发布密集,谷歌发布了 Gemini2.0 系列,xAI 发布了马斯克口中“地球上最聪明的人工智能”Grok 3,OpenAI 紧接着拿出了 GPT-4.5。
从全球知名 AI 模型评测平台 Chatbot Arena(大模型竞技场)的最新榜单来看,最新发布的 Gemini2.0 系列旗舰模型与 Grok 3 确实排在前列,但与排在第 5 位的 DeepSeek-R1 并没有拉开实质性的差距,以大模型竞技场的评分来看,差距在 15 分-40 分之间。
在 2025 年达沃斯论坛上,AI 科技初创公司 Scale AI 创始人亚历山大·王(Alexandr Wang)公开表示, DeepSeek 的 AI 大模型性能大致与美国最好的模型相当。他认为,过去十年来,美国可能一直在人工智能竞赛中领先于中国,但 DeepSeek 的 AI 大模型发布可能会“改变一切”。
在国内,DeepSeek 同样给大模型厂商不小的压力。去年C端大模型应用做得声量最大的国内厂商中,一定有豆包和 Kimi。但如果最近再看苹果中国区免费版 APP 排行,会发现,第一名是 DeepSeek,腾讯元宝搭载 DeepSeek 并大方投流后,也冲到了榜单第二名。
AI 业内人士表示,DeepSeek 的技术实力过硬且选择开源,这对一些闭源公司造成了冲击,一些大模型团队需要反思自身的做法。
DeepSeek-R1 不是大模型竞争的终局,有消息称,DeepSeek 正寻求巩固自身优势,尽早推出 R2 模型,消息提到 DeepSeek 原本计划在 5 月初发布 R2 模型,目前会加快这一速度。DeepSeek 目前并未对此回应。
此前 DeepSeek 在 R1 论文中提到,R1 的性能将在下一个版本得到改善,因为相关的 RL(强化学习)训练数据还很少。随着 RL 数据的增加,模型解决复杂推理任务的能力持续稳定提升,且会自然涌现出一些复杂行为能力。
同时,OpenAI 的下一代推理模型 o3 计划融入 GPT-5 并在几个月内推出。虽然 OpenAI 还在持续推出 GPT-4o、GPT-4.5 这类带有过渡色彩的模型,但目前距离 GPT-4 推出已有近两年时间。发布 GPT-4.5 之后,OpenAI 还需尽快证明自己仍是全球最先进的大模型公司,接下来推出 GPT-5 将是重要一步。
DeepSeek 能否赢得下一局对弈仍存变数,但可以确定的是,它为行业竞争带来了更深远的影响,在 2025 年初以压倒性的声势冒头,打乱了 AI 圈的格局,竞争对手或许需要思考,如何走赢下一步棋。






