
新智元报道
编辑:KingHZ
【新智元导读】DeepSeek 和 xAI 相继用 R1 和 Grok-3 证明:预训练 Scaling Law 不是 OpenAI 的护城河。将来 95% 的算力将用在推理,而不是现在的训练和推理各 50%。OpenAI 前途不明,生死难料!
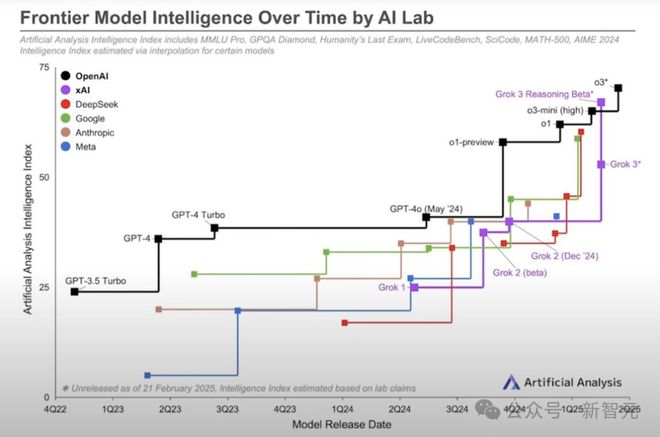
语言模型竞技场 LM Arena,新的「全能冠军」诞生了!
这次是「地球上最聪明的 AI」——Grok 3。
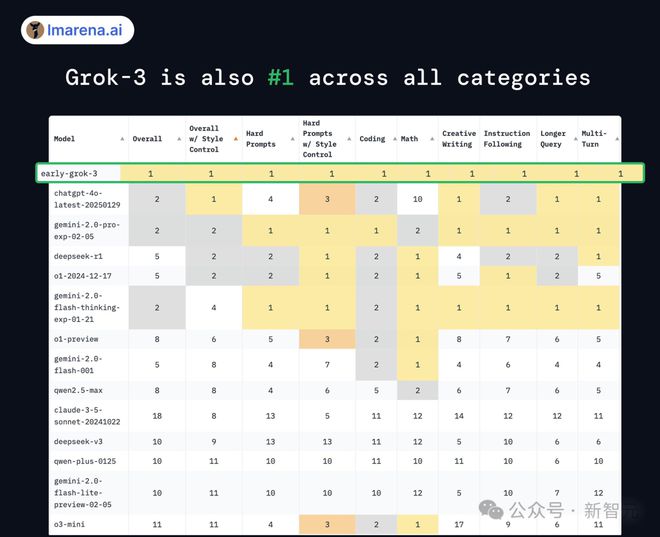
Grok 3 证明了 Scaling Law 的确有效,OpenAI 技术护城河被攻破!
此前,DeepSeek 证明不用 Scaling Law 也能达到 OpenAI o1 水平。
真是「一根筋,两头堵」:无论 Scaling Law 有用没用,OpenAI 的技术「窗户纸」被捅破了。
这不得不怀疑 OpenAI 到底行不行?OpenAI 的盈利模式有可持续性吗?xAI+DeepSeek 又能带来什么?
Atreides Management 的管理合伙人和首席投资官 Gavin S. Baker,分享了自己对 AI 竞争的见解。
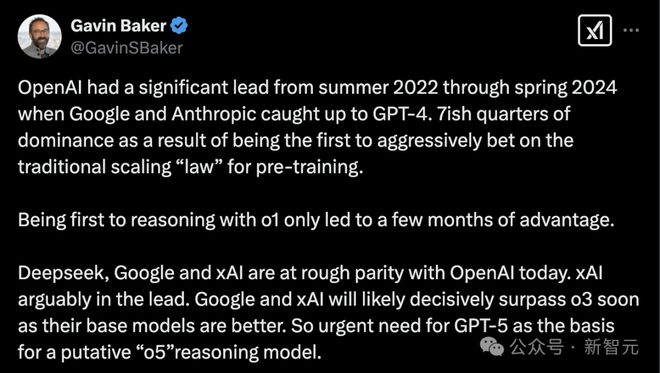
OpenAI 时代结束
从 2022 年夏季到 2024 年春季,OpenAI 在 GPT-4 上领先,直到谷歌和 Anthropic 追上了 GPT-4。
OpenAI 是首个积极采用传统「Scaling Law」进行预训练的公司,享受了大约 7 个季度的主导地位。
首次实现 o1 推理只带来了几个月的优势。
如今,DeepSeek、谷歌和 xAI 与 OpenAI 大致处于同一水平,其中 xAI 可能稍占优势。
谷歌和 xAI 预计很快会凭借其更好的基础模型,显著超越 o3。
因此,OpenAI 迫切需要推出 GPT-5,作为未来「o5」推理模型的基础。
奥特曼都承认,OpenAI 未来的领先优势将会缩小。
而微软 CEO 纳德拉则明确表示,在模型能力上,OpenAI 一度拥有独特的优势,而这一即将结束。
OpenAI 没有独门秘籍
谷歌和 xAI 都拥有独特且有价值的数据源,这些数据源使它们逐渐区别于 DeepSeek、OpenAI 和 Anthropic。
如果 Meta 在模型能力方面赶上,也会如此。
Gavin S. Baker 认为:没有访问独特且有价值数据的顶级 AI 模型,是有史以来贬值最快的资产。
蒸馏只会加剧这一现象。
微软似乎也认同这一观点:选择了不再给 OpenAI 投入 1600 亿美元进行预训练,并取消了传闻中的数据中心建设。
如果没有访问 YouTube、X、TeslaVision、Instagram 和 Facebook 等独有数据,未来的尖端模型可能不会有投资回报(ROI)。
从这个角度看,扎克伯格的战略似乎更加合理。
最终,独有的数据可能是唯一能够带来差异化,并对预训练万亿甚至千万亿级别参数模型的投资回报的基础。
OpenAI 难以一家独大
经济学家 Ethan Mollick,则认为 AI 的确进入了新时代,OpenAI 时代落幕了。
左图是训练 Scaling Law,也就就是说模型规模越大,性能越强。训练更大的模型需要增加计算能力、数据和能源的使用量。
通常,需要将计算能力增加 10 倍以获得性能的线性增长。计算能力以 FLOPs(浮点运算)衡量,这是计算机执行的基本数学运算的数量,如加法或乘法。
右图是推理 Scaling Law,也就就是说模型思考越久,它表现越好。
如果让模型花更多计算能力去处理问题,就能得到更好的结果——
就像给聪明人几分钟额外时间来解决谜题一样。
这称之为测试时或推理时计算
第二个规模法则诞生了推理模型(Reasoner)。
在需要时,第三代模型都将作为 Reasoners 运行,因为有两个优势:更大的训练规模,以及在解决问题时具有可扩展性。
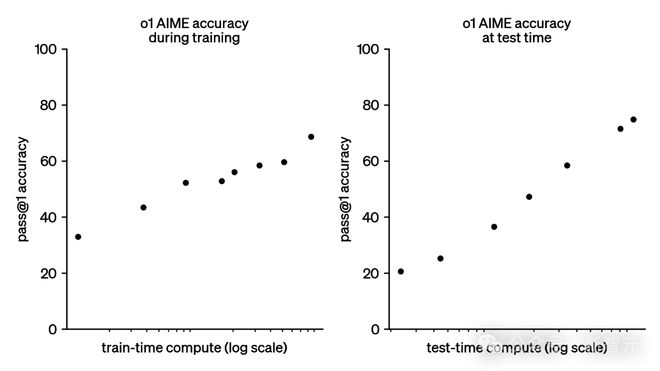
这两个 Scaling Law 正在极大地提升 AI 的数学能力,并且还在增加其他方面的能力。
如果有一个大型、智能的 AI 模型,就可以用它来创建更小、更快、更便宜的模型,这些模型的智能程度虽然不如母模型,但仍然相当高。
即使是小型模型,但加入了推理能力,它们会变得更加智能。这意味着 AI 的能力在提升,而成本却在下降。
下图展示了这一趋势的迅速发展,y轴上表示 AI 的能力,x轴上表示成本的对数下降。
GPT-4 刚发布时,每百 token 大约需要 50 美元(大约相当于一个单词)。
而现在使用比比原始 GPT-4 更强大的 Gemini 1.5 Flash,每百万 token 的成本大约只有 12 美分,成本下降了 99%+。
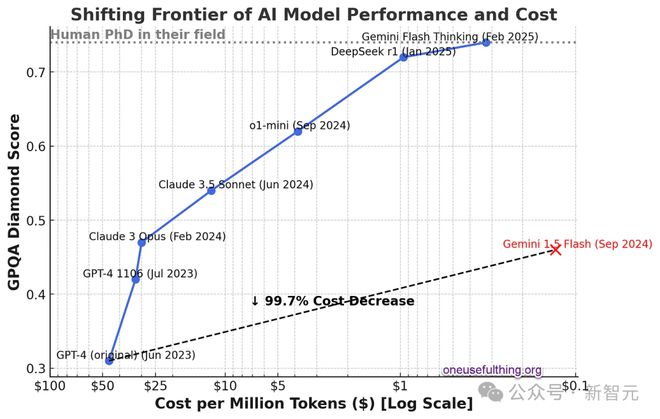
GPQA 是一系列非常难的多项选择题,旨在测试高级知识。拥有互联网访问权限的博士在其专业领域外的正确率为 34%,在其专业领域内的正确率为 81%。每百万 token 的成本是使用模型的成本(Gemini Flash Thinking 的成本是估算的)。
OpenAI 内忧外患
Gavin S. Baker 认为微软之所以不给 OpenAI 提供 1600 亿美元的预训练资金,就是因为 AI 的预训练是前期成本,并不能带来利润。
相反,微软将提供 OpenAI 推理服务来赚钱。
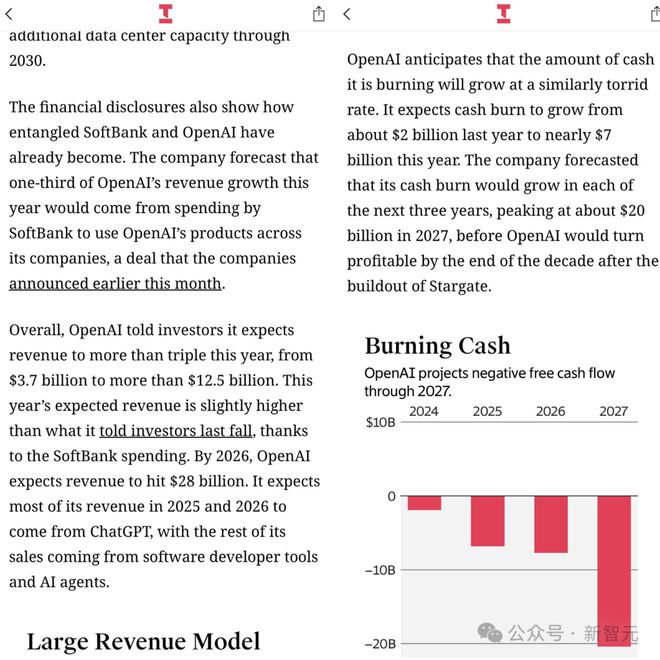
The information 估计软银今年将在 OpenAI 产品上投入超过 20 亿美元,约占 OpenAI 收入的 20%。25-30 年,OpenAI 在算力上的花费为 3200 亿美元。2027 年现金消耗达 200 亿美元。
而在 2023 年,纳德拉一度公开表示无法想象没有 AI 的生活,要全力押注 AI。

现在微软和 OpenAI 的裂痕在持续加大。

去年,微软就表示将非 OpenAI 的模型接入到 Copilot 中。
在未来某个时刻,微软甚至可能使用开源模型来支持 Copilot。

Copilot 已有多家 AI 供应商
除了最大的外部合作伙伴,一些高管和重要员工也纷纷另立门户。
前 CTO,Mira Murati,与 OpenAI 的老同事联合创立了 Thinking Machines Lab,目标是 AI 研究和产品。 前首席科学家,Ilya Sutskever,创立了 Safe Superintelligence,目标是 AI 安全。 创始员工,Andrej Karpathy,两度加入 OpenAI,最后选择离开,创立 Eureka Labs,主营业务为 AI 教育。 副总裁,Dario Amodei,创立 Anthropic,最近刚刚推出了 AI 模型 Claude 3.7 Sonnet。
更不要提,马斯克还在法院提起诉讼,竭力阻止奥特曼将 OpenAI 转为非营利公司。
AI 的收入来自推理
如果 Scaling Law 还有效,训练数据决定了未来大模型的投资回报,那么只有 2 到 3 家公司,会进行尖端模型的预训练。
只要少数几个巨型数据中心,就足以让它们进行所需的连续集群预训练。
其余的 AI 计算只需要一些较小的数据中心,这些数据中心经过地理优化,从而实现了低延迟和/或高成本效益的推理。
Gavin S. Baker 认为:「经济高效的推理 = 更便宜、质量较低的电力」。
现在,全世界有6-10 家公司会预训练尖端模型,但到那时,一切将截然不同。
请注意,推理模型的计算量非常大。测试时的计算意味着计算就是智能。
因此,与 2023-2024 年整个市场的「以预训练为中心」相比,这种情况所需的计算量可能还要大。
这和目前的算力分布,完全不同:
不再是预训练和推理各占 50% 的情况。 而可能变成预训练只占5%,推理占 95%。 很多硬件将针对推理进行优化,而很少针对预训练优化。
卓越的基础设施将至关重要。
所有这些都没有考虑到设备上(on-device)推理和/或完全量化的影响。
而超级智能(ASI)的经济效益,本质上是未知的。
Gavin S. Baker 希望它们很高,但一个拥有 140 智商的模型,在设备上运行并访问关于世界的独特数据,对于大多数用例来说可能已经足够。
ASI(超级智能)并不需要用来预订旅行等任务。
到 2030 年,推理成本(即运行 AI 模型的成本)预计将超过训练成本,因此 OpenAI 需要一个长期可持续的解决方案。
如果 Stargate 项目未能提供与微软云服务相同的稳定性和效率,这可能会带来重大风险。
时间会证明一切。
DeepSeek 效应
即便是 DeepSeek 梁文峰公开表示,业内对 DeepSeek-R1 反应过度。他表示这只是一次一般的普通的创新,世界每天都有类似这样的创新。
不妨假设一下,DeepSeek 来自美国中西部某个实验室。
比如,某个计算机科学实验室买不起最新的英伟达芯片,只能使用旧硬件。
但他们有一个很棒的算法和系统部门,用几百万美元训练了一个模型:
瞧,这个模型与 o1 大致相当。看,我们找到了一个新的训练方法,我们优化了很多算法!
每个人都像「哦哇」一样开始尝试同样的方法,然后欢呼:这是 AI 进步的一周!
美国股市也不会因此蒸发一万亿美元。
DeepSeek 的确在大模型训练上,取得了一些创新。但和其他从业人员一样研究同样的问题。
不仅如此,他们还发表了论文,并开源了模型。
在开源 AI 界,甚至出现了用最经济的方法,复刻 DeepSeek-R1「顿悟时刻」的竞赛。
这一切就像是 2004 年的谷歌。
在 2004 年,谷歌在上市招股书S-1 文件中,向世界透露他们使用分布式算法,在计算机网络中将商品连接在一起,实现了最佳的性价比,从而构建了最大的超级计算机集群。

谷歌S-1 文件链接:https://www.sec.gov/Archives/edgar/data/1288776/000119312504073639/ds1.htm
这与当时其他所有科技公司都不同,它们只是购买越来越大的大型机。
为了跟上不断上升的交易量,一些大公司会从甲骨文购买越来越大的数据库服务器。
谷歌的S-1 描述了如何能够超越大型机的可伸缩性限制。
后来,谷歌发表了 MapReduce 和 BigTable 论文,描述了用于管理和控制这个成本效益更高、功能更强大的超级计算机的算法。
谷歌在取得如此巨大成功之后,并没有马上发表论文,公开他们的做法。
相比之下,在与模型发布的同时,DeepSeek 发表了论文。
DeepSeek 的发展轨迹,与 2004 年谷歌展示自己的能力并没有什么本质不同。
竞争对手仍然需要调整并实际去做这件事,但 DeepSeek 推动了这一领域的发展。
认为英伟达、OpenAI、Meta、微软、谷歌等公司已经完蛋了,这种想法也没什么理由。
当然,DeepSeek 是一个新的、强大的新兴公司,但 AI 领域不是每周都会出现这样的情况吗?
每个人都会在几个月内复制这一成就,一切都会变得更便宜。
唯一的真正后果是,AI 乌托邦/末日现在比以往任何时候都要近。
参考资料:
https://x.com/GavinSBaker/status/1893348988386189774
https://x.com/SumitGup/status/1893709368480117096
https://www.oneusefulthing.org/p/a-new-generation-of-ais-claude-37






