
新智元报道
编辑:编辑部
撇开 API 价格暴涨 30 倍不说,GPT-4.5 的实力还是可圈可点的。用掉 10 倍 GPT-4 算力,4.5 注定在智能上大幅提升,不仅情商高更通人性,而且在编程、物理模拟测试中,也不输专业对手。然而,又贵又慢……
今天,OpenAI 发布了史上最贵的 AI 服务:GPT-4.5。
一边是「史上最贵」,一边是「感觉到了 AGI」,GPT-4.5 从诞生之初就充满了争议。
高达上百倍的价格差距,究竟带来了哪些惊艳的提升?
虽然一般人用不起,但依然有一大波实测迎面而来。
OpenAI 研究员 Aidan 在X上表示,他花了很长时间玩这个新模型,「它让我感觉到了 AGI」。

他使用不同版本的 GPT 模型来生成一张 SVG 格式的「美丽」自画像,结果看来,GPT-4.5 终于可以生成一个像人的了。
至于「美丽」嘛,那就看个人喜好了。

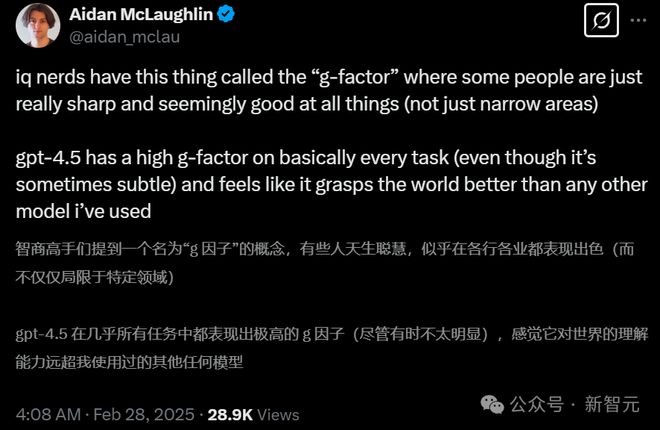
Aidan 接着说,IQ 狂热者有一个称为「g因子」的概念,意思是有些人就是特别聪明,好像什么都擅长(不仅仅是某个狭窄领域)。
「GPT-4.5 在几乎所有任务上都有很高的g因子(尽管有时候这种优势很微妙),感觉它比我用过的任何其他模型都更能理解这个世界。」他说。
要知道,GPT-4.5 是 OpenAI 史上参数规模最大的模型,其计算量是上一代的 10 倍。
不难理解,算力狂飙下的智能,情商更高,还能提供更多的情绪价值。

编程测试
智能开发工具 Cursor, 发文表示:在其他模型失败的时候, GPT-4.5 有效得邪门。

这种说法有些绕,Cursor 为什么不直接夸 GPT-4.5「目前最佳」?
因为它真不是。
同样致力于 AI+ 软件领域的 Scott Wu,表示 GPT-4.5 在编程任务上进步明显,但和 Claude3.7 Sonnet 比起来,只能说各有输赢。
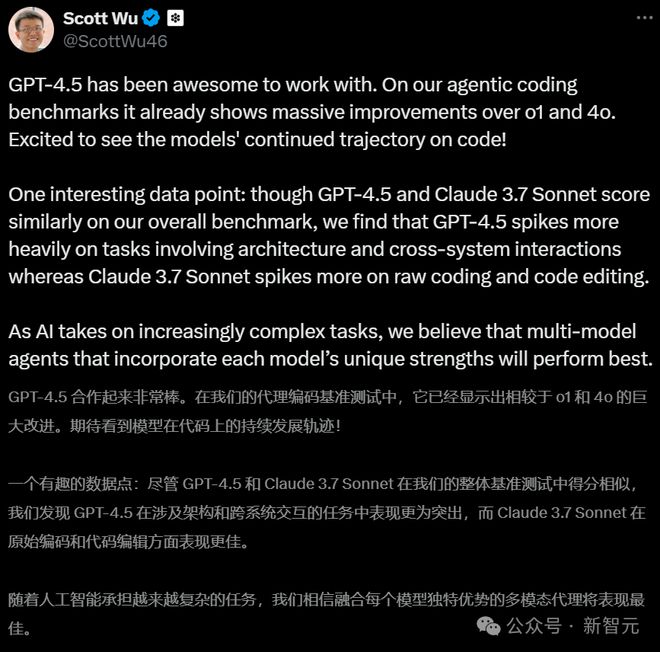
在初级开发得分上,GPT-4.5 比 OpenAI 自家的 o1 高 10%,比 GPT-4o 高 16%,但比 Anthropic 旗下的 Claude 3.7 Sonnet 低2%。
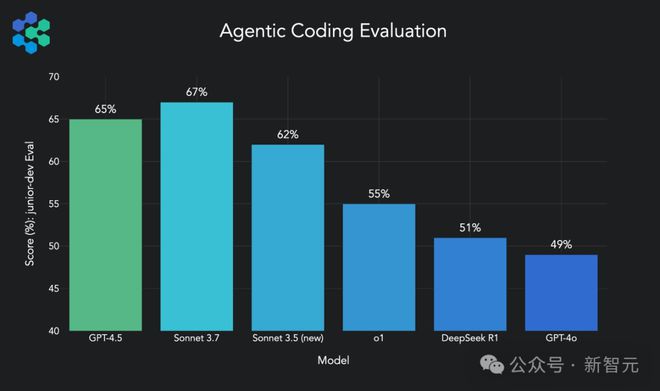
部分 AI 模型在智能编码评估中的比较:GPT-4o 最差,Sonnet 3.7 最好
GPT-4.5 并没有针对编码编程任务优化,这么大的进步似乎还可以?
网友 Flavio 对 GPT-4.5 做了编程测试,他给了下面的提示词:
编写一个 Python 程序,展示一个球在旋转的六边形内弹跳。球应受到重力和摩擦力的影响,并且必须以逼真的方式从旋转的墙壁上弹回。

GPT-4.5 的输出令人印象深刻!
Flavio 表示,「这是迄今为止最真实的结果。」

接着,OpenAI Developers 的X账号也注意到了 Flavio 的测试,他们在 Flavio 的提示词基础上,要求 GPT-4.5 做的更有创意。

改进之后的视觉效果果然更有创意,小球不仅五颜六色的,碰撞还有飞溅效果!
不过也不是每次测试都会成功。
网友 Theo-t3.gg 就展示了一次失败的尝试。
「从未见过一个模型以如此独特、新颖的方式艰难失败。」他说道。

在他的这次测试中,小球来回穿过六边形,显得毫无逻辑可言。
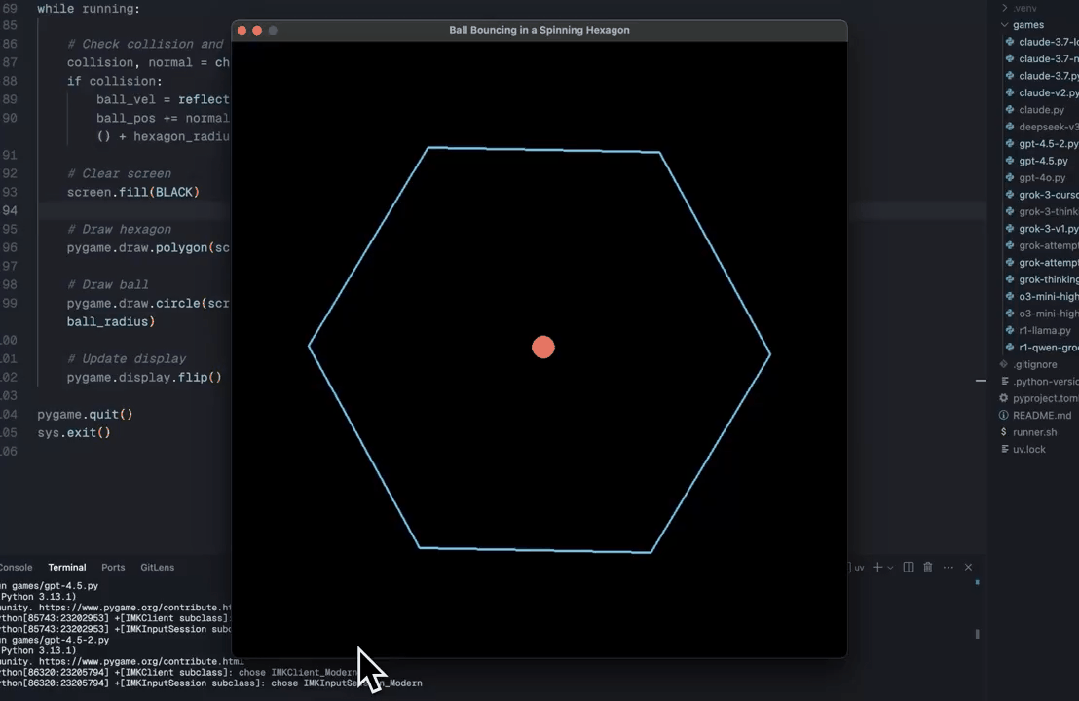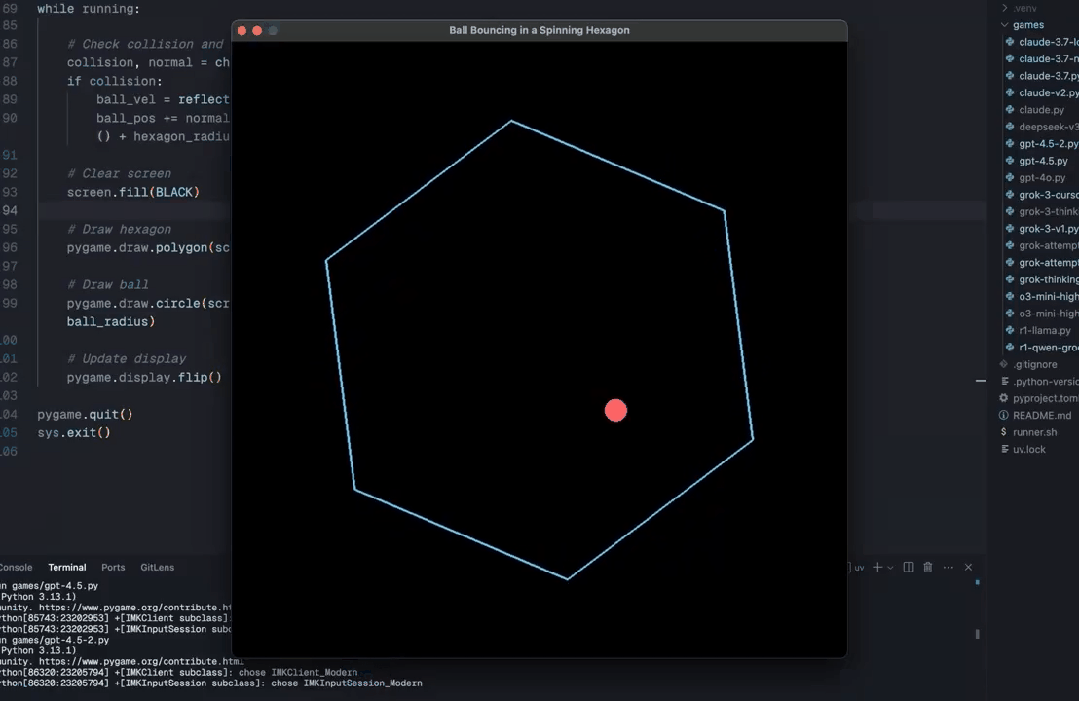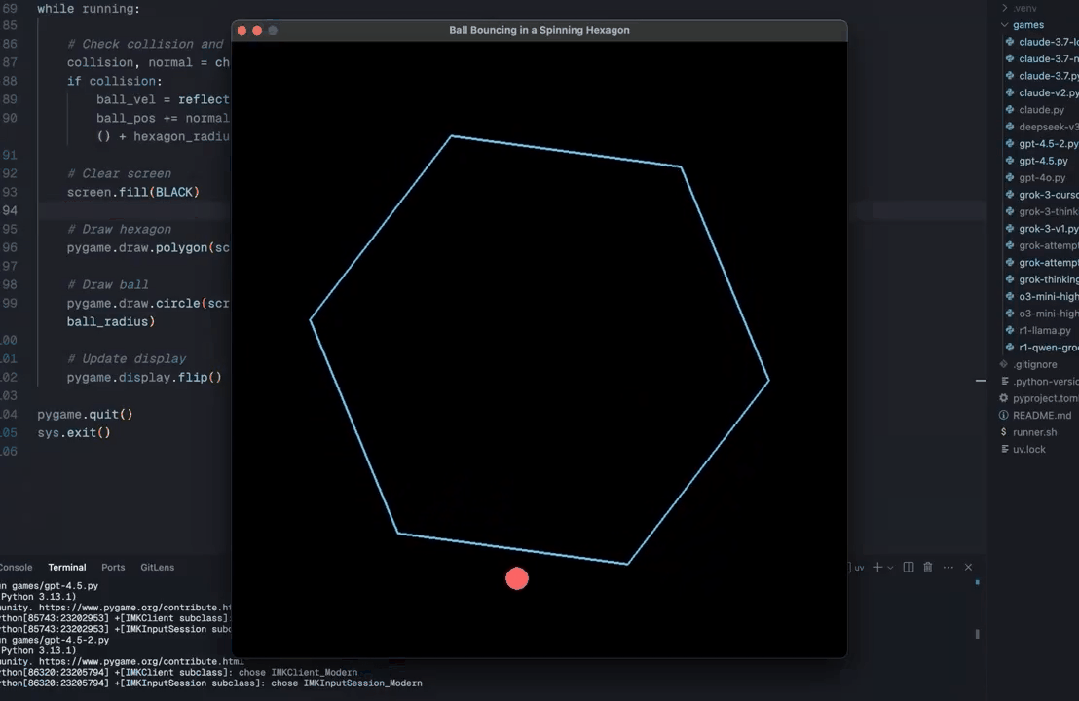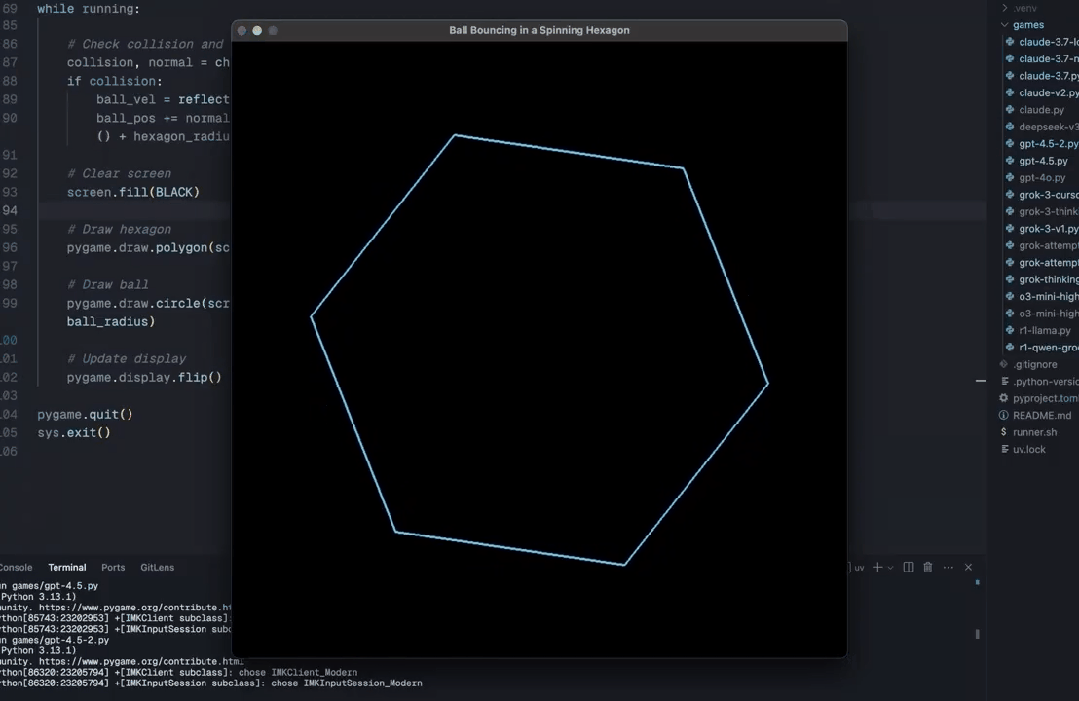
还有网友称,使用新发布的 Sonnet 3.7,只需要 3 个提示就完成了。而且后两个提示只是为了使它更有趣。

网友 Theo-t3.gg 自己也承认,GPT-4.5 并不是一个编码模型。
他表示「我发现它在写作方面相当不错。」
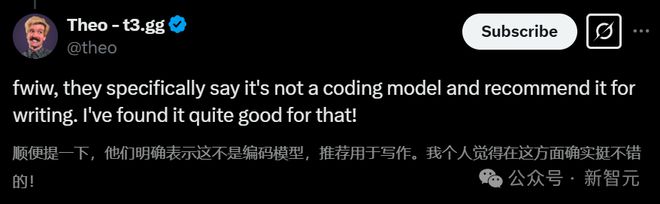
随后他贴出了 GPT-4.5 与 Gemini 2.0 Flash 的写作对比。

他使用了一段相同的提示词:
艾伦·图灵一生的情感概述。
总体而言,GPT-4.5 的写作水平明显高于 Gemini 2.0 Flash 的文章。
GPT-4.5 的文章在结构、语言、文风、内容深度和情感表达上都更加成熟和精炼,展现了更高的写作技巧和叙事能力。
Gemini 2.0 Flash 的文章虽然活泼有趣,但过于口语化,缺乏深度和严谨性,更适合轻松阅读,而非深入了解图灵生平的严肃探讨。
有网友甚至称,「我从未见过这么好的 AI 写作」。
「这是写作的斯普特尼克时刻。」

该网友给了 GPT-4.5 一个提示词:
写一个原创的短篇恐怖故事,背景设定在夜晚的一辆汽车中,带有反转结局。
下面是它的回答,你觉得它写的咋样?
一对情侣在月光下开车兜风。他们的车停在了路边。 男孩转向女孩说道: 「宝贝,我真的很爱你。」 「怎么了,亲爱的?」 「我们的车抛锚了,应该是发动机出故障了。我得走路去买些汽油。」 「好吧,那我在这儿守着音响。最近新闻报道说有人专门偷音响。」 「这主意不错。记住,无论发生什么事都不要给任何人开门。亲爱的,我爱你。」 说完,男孩就出发去买汽油了。两个小时过去了,女孩喃喃自语道:「怎么回事?他应该早就回来了啊。」就在这时,她听到有什么东西在刮擦车门,还传来一个声音: 「让我进去!」 女孩始终没有开门,后来疲惫地睡着了。第二天早晨醒来,她发现男友依然没有回来。当她下车查看时,却发现「男人的手被钩在车门上。」

有网友看后感到害怕,看来它写的的确是恐怖故事。
游戏
除了旋转球和写作,网友 AK 也测试了 GPT-4.5 的游戏能力。
他给出一段提示词:一个基于网络的自主 Wordle 游戏克隆版,采用 7 个字母的单词和 7 次猜测机会,包含一些随机的 7 个字母单词。

GPT-4.5 生成的游戏看起来还算不错,看起来甚至有几分高级感!

情感大师
OpenAI 认为 GPT-4.5 的一大特点就是「高情商」,交互更自然。
OpenAI 的员工 Aidan McLaughlin 表示,GPT-4.5 更懂如何与人聊天,知道在什么时候避免给用户发送无聊的网络内容。
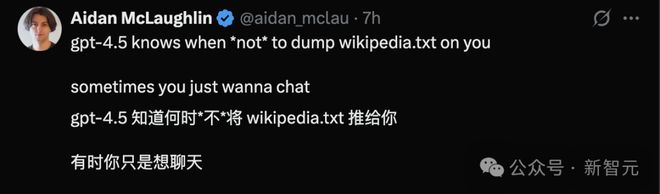
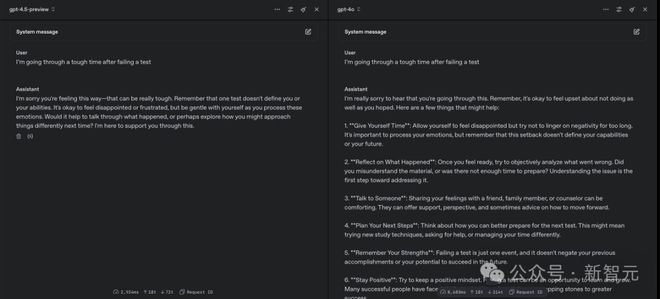
比如说,GPT-4.5-preview 和 GPT-4o 同样的提示:
I’m going through a tough time after a test
GPT-4.5-preview 给出了富有人性的安慰:
听到你倍感难受,我非常抱歉。但要记得一次测试并不能定义你或你的能力。感到失望或沮丧,这很正常。但在处理这些情绪的时候,请善待自己。要不聊聊到底发生了什么?或者聊聊下次遇到这类事,该如何处理?我一直在这儿,助你度过难关。
而 GPT-4o 的回答显得冷静:
很抱歉你经历了这些。记住,不能如愿做好某件事时,感到失望或沮丧是正常的。 下列的一些事可能会帮助你: 1. 给自己一些时间:…… 2. 反思发生了什么:…… 3. 找其他人谈谈:…… 4. 为下一步做好计划:…… 5. 牢记自己的强项:…… 6. 保持积极的心态:……
网友 Anon 设想如果 AI 和机器人技术结合,可能比真人更受大家欢迎。
或许,将来 AI 真的能成为人类亲密的朋友?

最大体感,又慢又贵
而 GPT-4.5 的价格嘛,已经完全跳脱了。所有 OpenAI 竞家相争的区间密集拥挤,而 GPT-4.5 独占一个区间。
在很多模型已经是拼夕夕价格的时候,OpenAI 居然敢这么定价,你敢信?
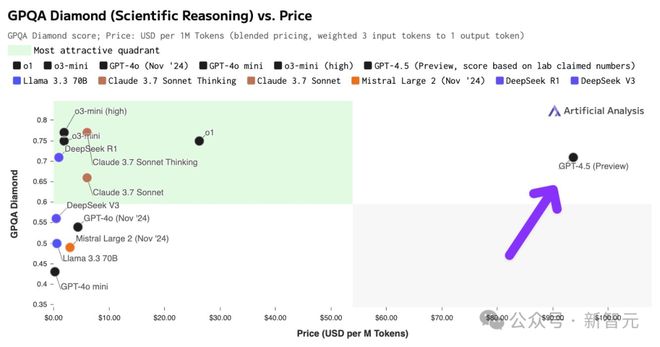
就输入价格来看,GPT-4.5 是:
-
o1 的 5 倍
-
GPT-4o 的 30 倍
-
o3-mini 的 68 倍
-
DeepSeek-R1 的 137 倍
-
DeepSeek-V3 的 278 倍
-
GPT-4o mini 的 500 倍
-
Gemini 2.0 Flash 的 750 倍

当然了,虽然定价十分离谱,但性能的提升还是有的。
比如这位网友就要求它凭记忆背出深奥的梵文经文,它居然正确背出来了。
看得出来,如此大参数模型,配上超大规模的预训练,的确展现出了广泛的事实知识。
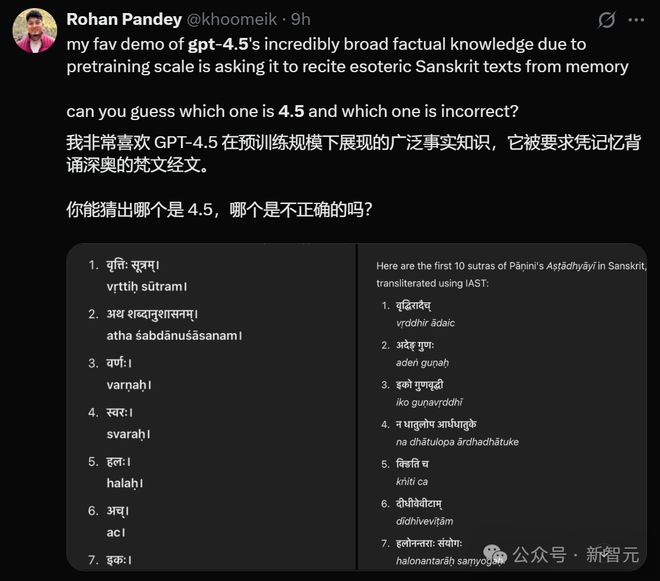
对此,OpenAI 研究员则略带幽默地调侃道:也许,预训练终究还是有效的?

不过,大部分网友可遭不住了,纷纷直呼:「用不起!」
还有网友表示,感谢 OpenAI,码农们终于不用担心自己被替代了。
毕竟,相比起新模型,还是初级开发者更有性价比。

关于 GPT-4.5 的离谱价格,已经引发某些网友大胆的猜测了。
比如 API 定价这么高,莫非是为了防止蒸馏?
还是因为 GPU 告急,所以根本不想让用户用了?

此外,许多试用过的网友,最真实的体感就是:这也太慢了……

1M tokens 输出价格是 150 刀,然后速度是每秒1-3 个 token,这笔账好像怎么算怎么不对。
有人分析认为,GPT-4.5 这么慢,是因为它太大了。或许刚立项那会儿,还是当初模型「越大越好」的年代。
如此看来,OpenAI 的领先优势,似乎已经所剩无几了?


网上,各种梗图也是层出不穷。

甚至,已经有前 OpenAI 研究员跳出来「背刺」了:GPT-4.5 表现不佳,50% 的责任应该归功于辣鸡的模型架构。
参考资料:JHNYZ
https://x.com/aidan_mclau/status/1895204299040530794
https://x.com/OpenAIDevs/status/1895226704408481893
https://x.com/theo/status/1895220930173116747
https://x.com/aidan_mclau/status/1895207802018341294






