
新智元报道
编辑:KingHZ
基于连续概念,Meta 团队新研究提出了超越「下一个 token 预测」语言建模新范式。更加重要的是,新方法不仅能增强原有的范式,而且比起知识蒸馏,数据量减少 20%,甚至能从小模型提取概念指导更大的模型!
「下一个 token 预测」(next token prediction,NTP)是大语言模型(LLMs)不断取得突破的核心技术。
但这种依赖 tokenization 的方法,导致 LLM「严重偏科」。
比如,Karpathy 发现一个表情包相当于 53 个 token!
关注 AI 的可能也知道 GPT-4o 不会数字母,不知道 Strawberray 中有几个字母「r」。
为了解决此类问题,最近的研究探讨了超越 token 级信号的方法,利用更丰富的信息来训练模型。
比如说,一次性预测多个 token;在下一个 token 预测之前增强输入,加入丰富的信号;或用连续的潜在表示替代离散的语言标记,提高推理效率。
Meta 的下一代系统「大概念模型」,彻底超越 token 级别语言建模,直接在语句级别上语言建模,摆脱人类语言类型对模型性能的制约。
这次,受到近期研究发现的启发,来自 Meta 的研究人员认为稀疏自编码器(Sparse Autoencoders,SAEs)可以捕捉高层次的语义概念,在 LLM 中有效地隔离出有意义的潜在特征。
由于 SAEs 是通过稀疏性约束训练,重构模型的隐状态,它促使模型集中关注一组紧凑的概念维度。
这可以突出预训练模型的概念——即支撑模型预测的核心语义方向,同时避免不必要的特征。

论文链接:https://arxiv.org/abs/2502.08524
新研究在多个语言建模基准和预训练模型规模(从百万规模到十亿规模的参数模型)上进行广泛的评估,展示了 CoCoMix 的有效性。
例如,在应用于 1.38B 参数模型时,CoCoMix 在下一个 token 预测任务中的表现与传统方法相当,同时减少了 21.5% 的训练数据量。
此外,CoCoMix 在弱监督到强监督场景中表现出显著的提升,其中从小模型中提取的概念甚至可以作为真实标签,用于监督大模型的训练。
最后,通过插入压缩的概念向量,能够在生成过程中探查预测的概念,从而引导和控制模型。
主要方法:CoCoMix
CoCoMix 是一种新的 LLM 预训练框架,通过预测概念并将其混入模型的隐状态中,以提高下一个 token 预测的准确性。
更高的样本效率,在下一个 token 预测、知识蒸馏以及插入暂停 token 等任务中表现优越,同时提高可解释性和可引导性,增强模型的可控性。
连续概念混合(CoCoMix)使用基于连续概念的语言建模框架。具体而言,CoCoMix 包含三个步骤来学习和使用潜在概念:
1. 从预训练的 SAE 中,提取概念并选择显著的概念。
2. LLM 从其隐藏状态预测这些概念。
3. 一旦预测出多个概念,就将它们压缩成一个单一的「连续概念」,并将其「混合」到 LLM 隐藏状态中。
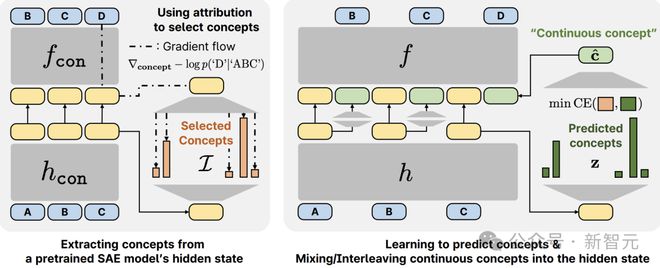
图1:CoCoMix 的概览。
新研究证明了 CoCoMix 具有更高的样本效率,并且优于标准的下一个 token 预测和知识蒸馏基线。
实验结果
CoCoMix 在性能上始终优于下一个 token 预测和知识蒸馏。
此外,新研究表明 CoCoMix 可以实现弱监督到强监督的转换,其中从较小模型中提取的概念可以指导更强(或更大)的学生模型。
由于模型经过训练可以预测其隐藏状态中的概念,可以通过检查概念预测来分析它关注哪些概念。通过放大或抑制预测的概念,我们还可以控制模型的输出生成。
总而言之,CoCoMix 效率更高,并且在不同模型规模下都优于下一个 token 预测,同时还引入了可解释性。
具体而言,通过研究以下问题,对 CoCoMix 进行了实证评估:
-
CoCoMix 能否提高 LLM 预训练中下一个 token 预测的性能?(图 2 和图3)
-
与其他知识蒸馏方法相比,CoCoMix 从弱监督到强监督设置中是否表现出改进?(表 1 和图4)
-
CoCoMix 是否引入了模型的可解释性和可操纵性?(图5)
-
CoCoMix 提出的各个组件对性能贡献如何?(图6)
提高 NTP 性能
图 2 展示了 CoCoMix 与 NTP(Next Token Prediction,下一个 token 预测)在不同训练检查点(checkpoint)的性能比较。每个模型包含总共 1.38B 个参数,都在 OpenWebText 数据集上进行训练。对于 CoCoMix,概念是从一个 1.24 亿大小的模型(比基础模型小 10 倍)中提取的。
显示了以下方面的改进:(a)验证困惑度,(b)在 LAMBADA、WikiText-103 上的平均困惑度,以及(c)在 HellaSwag、PIQA、SIQA、Arc-Easy 和 WinoGrande 上的平均准确率。
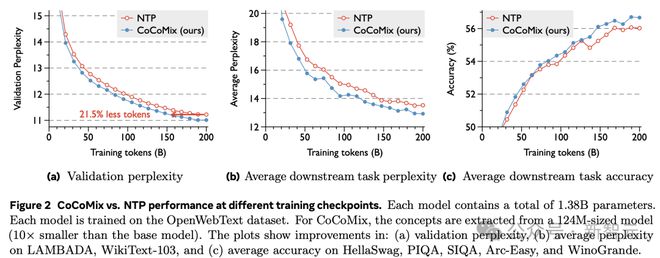
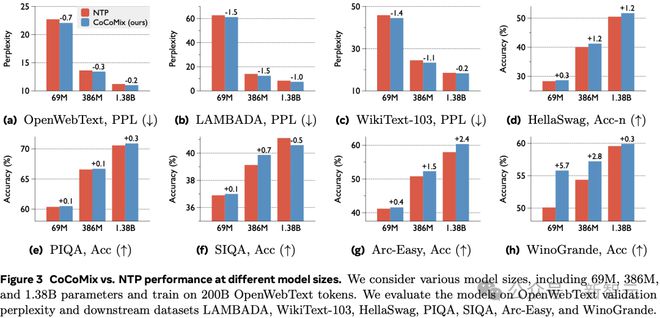
图 3 展示了 CoCoMix 与 NTP 在不同模型大小下的性能比较。考虑了各种模型大小,包括 69M、386M 和 1.38B 个参数,并在 200B 个 OpenWebText 的 token 上进行训练。评估了模型在 OpenWebText 验证困惑度以及下游数据集 LAMBADA、WikiText-103、HellaSwag、PIQA、SIQA、Arc-Easy 和 WinoGrande 上的表现。
与知识蒸馏比较
表 1 展示了 CoCoMix 与下一 token 预测(NTP)与知识蒸馏(KD)的对比。报告了在 OpenWebText(OWT)训练集上的表现,以及在下游任务中的表现。训练了三种不同规模的模型,其中 124M 模型作为教师模型。所有模型均在从 OpenWebText 数据集采样的 20B 个 token 上进行训练。加粗部分表示最佳结果。
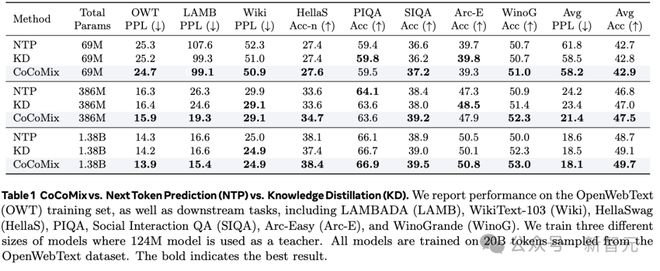
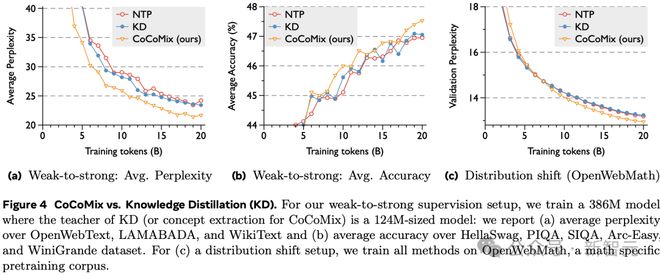
图 4 展示了 CoCoMix 与知识蒸馏(KD)的比较。对于弱监督到强监督设置,训练一个 386M 的模型,其中 KD 的教师(或 CoCoMix 的概念提取器)是一个 124M 大小的模型:报告了(a)在 OpenWebText、LAMABADA 和 WikiText 上的平均困惑度,以及(b)在 HellaSwag、PIQA、SIQA、Arc-Easy 和 WinoGrande 数据集上的平均准确率。对于(c)分布偏移设置,在 OpenWebMath(一个数学特定的预训练语料库)上训练所有方法。
可解释性和可操纵性
图 5 是概念引导效果的定性说明。CoCoMix 和 GPT2 模型分别是 350M 和 124M 参数的 Transformer,训练数据集为 OpenWebText。对于 CoCoMix,通过调整预测的概念 logit 值z来进行操作,而对于 GPT2,通过增加特定概念索引的激活值来调整 SAE 概念空间c。这展示了有针对性的概念引导对各自模型输出的影响。

各组件贡献
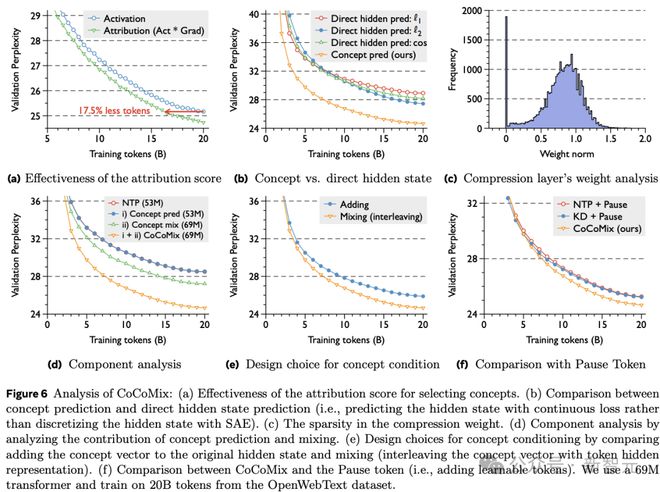
图 6 对 CoCoMix 的分析: (a) 归因分数在选择概念中的有效性。 (b) 概念预测与直接隐藏状态预测的比较(即,用连续损失预测隐藏状态,而不是用 SAE 离散化隐藏状态)。 (c) 压缩权重的稀疏性。 (d) 通过分析概念预测和混合的贡献进行的组件分析。 (e) 通过比较将概念向量添加到原始隐藏状态和混合(将概念向量与 token 隐藏表示交替)来选择概念条件设定的设计。 (f) CoCoMix 与暂停 token(即添加可学习的 tokens)的比较。使用了一个 69M 的 transformer,并且使用来自 OpenWebText 数据集的 20B 个 tokens 进行训练。
另外,值得一提是,作者中有多位华人,特别是「网红科学家」田渊栋也参与了本次论文工作。
更为详细的实验设置,请参阅原文。
参考资料:






