
文章来源:天翼云网站
本文介绍了英特尔®至强®处理器在 AI 推理领域的优势,如何使用一键部署的镜像进行纯 CPU 环境下基于 AMX 加速后的 DeepSeek-R1 7B 蒸馏模型推理,以及纯 CPU 环境下部署 DeepSeek-R1 671B 满血版模型实践。
大模型因其参数规模庞大、结构复杂,通常需要强大的计算资源来支持其推理过程,这使得算力成为大模型应用的核心要素。随着 DeepSeek-R1 模型的问世,各行各业纷纷展开了关于如何接入大模型能力的广泛调研与探索,市场对大模型推理算力的需求呈现出爆发式增长的趋势。
例如在医疗、金融、零售等领域,企业迫切希望通过接入 DeepSeek 大模型来提升决策效率和业务能力,从而推动行业的创新发展。在这一背景下,算力的供给和优化成为推动大模型落地应用的重要因素。
近年来,CPU 制程和架构的提升以及英特尔®高级矩阵扩展 AMX(Advanced Matrix Extensions)加速器的面世带来了算力的快速提升。英特尔对大模型推理等多个 AI 领域持续深入研究,提供全方位的 AI 软件支持,兼容主流 AI 软件且提供多种软件方式提升 CPU 的 AI 性能。目前,已有充分的数据显示 CPU 完全可以用于大模型推理场景。
CPU 适用于以下大模型推理场景:
- 场景1: 大模型推理需要的内存超过了单块 GPU 的显存容量,需要多块或更高配 GPU 卡,采用 CPU 方案,可以降低成本;
- 场景2: 应用请求量小,GPU 利用率低,采用 CPU 推理,资源划分的粒度更小,可有效降低起建成本;
- 场景3: GPU 资源紧缺,CPU 更容易获取,且可以胜任大模型推理。
天翼云 EMR 实例 DeepSeek-R1-Distill-Qwen-7B 蒸馏模型部署实践
本节内容主要介绍如何在天翼云 EMR 实例上,基于 Intel® xFasterTransformer 加速库和 vllm 推理引擎完成模型部署,并展示相关性能指标。
服务部署
为了方便用户使用,天翼云联合英特尔制作了一键部署的云主机镜像,内置 DeepSeek-R1-Distill-Qwen-7B 模型、vLLM 推理框架、xFT 加速库以及 open-webui 前端可视环境。您可在天翼云控制台选择下列资源池和镜像,开通云主机进行体验。
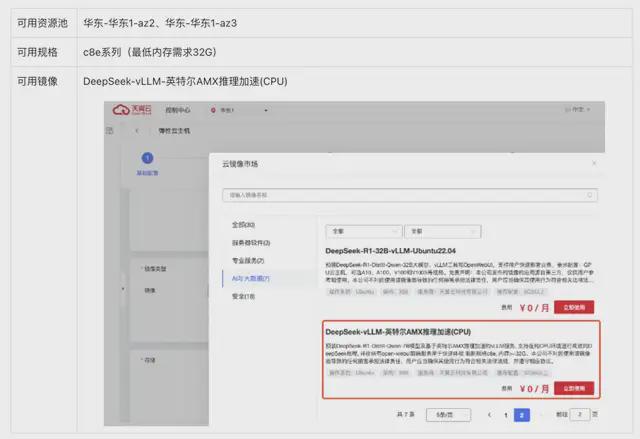
完成云主机开通后,推理服务会在 5 分钟内自动启动,您无需进行任何其他操作。
注:如需在云主机外访问服务,您需要绑定弹性 IP,并在安全组内放行 22/3000/8000 端口。
模型使用
open-webui 前端使用
镜像已内置 open-webui,并已完成和 vllm 的连接配置,可直接通过以下地址进行访问:
http://[弹性 IP]:3000/
注:1.首次打开页面时,您需要先完成管理员注册,以进行后续的用户管理。注册数据均保存在云实例的/root/volume/open-webui 目录下。
2. 如果首次打开对话页面时没有模型可供选择, 请您稍等几分钟让模型完成加载即可。
vllm api 调用
镜像内置 vllm 服务可直接通过如下地址访问:
# 根路径 http://[弹性 IP]:8000/# 查询现有模型 http://[弹性 IP]:8000/v1/models# 其他 api 接口参阅 vllm 文档
注:vllm 服务配置有 API_KEY,您可在云实例的/root/recreate_container.sh 文件开头查看到当前值,并可进行修改以确保服务安全。
性能指标
借助于英特尔 AMX 的加速能力,本推理服务能够取得显著的性能提升,天翼云完成测试并给出参考指标如下:
基本参数
vcpu 数:24(物理核 12)
内存:64GB
硬盘:60G 通用型 SSD
模型:DeepSeek-R1-Distill-Qwen-7B(bf16)
batch size:1
输入 token 个数:30-60
输出 token 个数:256
性能数据
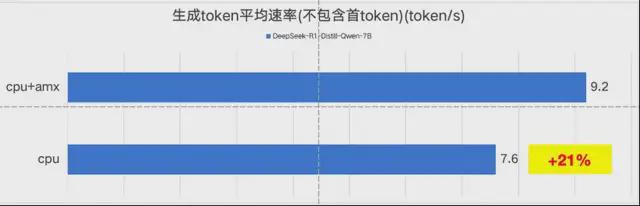
平均 token 生成速率:
首 token 时延:
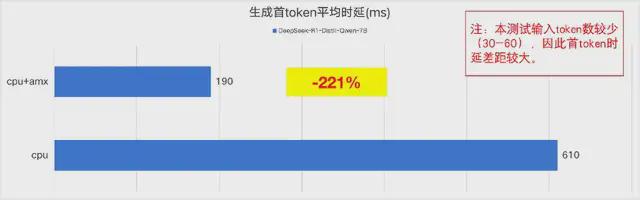
在天翼云 c8e 系列 24vcpu 云主机上,启用 AMX 加速能力后,DeepSeek 7B 蒸馏模型(BF16)推理速度能够超越 9token/s,满足日常使用需求。
基于英特尔®至强®6 处理器部署满血版 DeepSeek-R1 671B 实践
性能指标
DeepSeek R1 671B 满血版模型以其卓越的性能,为用户带来了极致的效果体验,不过其部署成本也不容小觑。若采用传统的 GPU 部署方式,需要8-16 张 GPU 才能提供足够的支持,这无疑大幅增加了硬件购置、能耗以及维护等方面的成本。
在这样的背景下,天翼云基于英特尔®提供的至强®6 处理器服务器进行了 DeepSeek R1 671B 满血版 Q4_K_M模型的部署尝试,测试结果如下:
1-instance 1-socket:
平均吞吐性能 9.7~10 token/s
2-instance 1-socket:
平均 7.32 token/s和 7.38token/s, 共 14.7token/s
从上面测试数据可以看到,采用单实例单 socket 部署下,DeepSeek R1 671B 满血版模型可达到平均 9.7~10 token/s的吞吐量,而在双实例部署模式中,总体吞吐量提升至 14.7 token/s。单颗 CPU 系统的吞吐性能可以达到普通用户正常使用的需要。
英特尔®至强®6 处理器简介
英特尔®至强®CPU 为 DeepSeek R1 671B 模型的部署提供了一个极具竞争力的方案。英特尔®至强®CPU 具备支持 T 级超大内存的能力,这使得它在权重存储与加载方面表现高效。对于像 DeepSeek R1 671B 这样的超大模型,其所需的显存容量在多卡 GPU 配置下才能满足,而英特尔®至强®CPU 能够凭借其强大的内存支持能力,为该模型提供良好的运行环境。
此外,DeepSeek R1 模型采用的 MOE(Mixture of Experts)结构,通过参数稀疏化的方式,使得在单 token 推理时仅需激活少量专家参数。这种特性显著降低了推理过程中的算力要求,与 CPU 的计算特点相契合,使得模型在 CPU 系统上的运行更加高效。这意味着在英特尔®至强®CPU 上部署 DeepSeek R1 671B 模型,不仅能够充分发挥模型的性能优势,还能有效降低部署成本,避免了对大量 GPU 的依赖。
如需复现以上性能测试结果,请参看附录2
总结
通过本次实践,无论是在天翼云 EMR 云实例上结合 xFasterTransformer 部署 DS R1 distill Qwen-7B 蒸馏模型,还是基于英特尔®至强®6 处理器部署满血版 DeepSeek-R1 671B 模型,均验证了 CPU 系统在 DeepSeek 大模型推理上的可行性和符合业界普遍要求的性能表现。CPU 系统不仅能够灵活应对不同规模的模型需求,无论是轻量化蒸馏模型还是全功能满血模型,都能高效满足用户场景需求,提供了一种低成本、经济高效的解决方案。
附录 1 英特尔®至强®可扩展处理器与 AI 加速技术
最新英特尔®至强®可扩展处理器产品
英特尔第五代®至强®可扩展处理器(代号 Emerald Rapids)——为 AI 加速而生
第五代英特尔®至强®处理器以专为 AI 工作负载量身定制的设计理念,实现了核心架构和内存系统的双重飞跃。其 64 核心设计搭配高达 320MB 的三级缓存(每核心由 1.875MB 提升至 5MB),相较上代缓存容量实现近三倍增长,为大规模并行 AI 推理提供充裕的本地数据存储空间。与此同时,处理器支持 DDR5-5600 高速内存,单路最大 4TB 的容量保证了大数据处理时的带宽和延迟优势。基于这些硬件提升,Emerald Rapids 整体性能较上一代提升 21%,AI 推理性能平均提升 42%,在大语言模型推理场景中可实现最高 1.5 倍的性能加速,同时大幅降低总拥有成本达 77%。
英特尔®至强®6 处理器(代号 GNR Granite Rapids)——引领 CPU AI 算力革新
全新 GNR 处理器专为应对人工智能、数据分析及科学计算等计算密集型任务而设计。该产品在内核数量、内存带宽及专用 AI 加速器方面均实现重大突破:
- 核心与性能:每 CPU 配备多达 128 个性能核心,单路核心数较上一代翻倍,同时平均单核性能提升达 1.2 倍、每瓦性能提升 1.6 倍,进一步强化了 CPU 在大模型推理中的独立处理能力;
- AI 加速功能:内置英特尔®高级矩阵扩展(AMX)新增对 FP16 数据类型的支持,使得生成式 AI 和传统深度学习推理任务均能获得显著加速;
- 内存与I/O突破:支持 DDR5-6400 内存及英特尔首款引入的 Multiplexed Rank DIMM (MRDIMM) 技术,有效将内存带宽提升至上一代的 2.3 倍;同时,高达 504MB 的三级缓存和低延迟设计确保数据能够更快加载,为复杂模型训练和推理缩短响应时间。
英特尔®至强®6 处理器不仅通过更多的核心和更高的单线程性能提升了 AI 大模型推理能力,同时也能够作为机头 CPU 为 GPU 和其他加速器提供高速数据供给,进一步缩短整体模型训练时间。在满足混合工作负载需求的同时,其 TCO 平均降低 30%,大模型推理加速最高可达 2.4 倍。
无论是第五代至强还是全新的至强 6 处理器,英特尔均通过在核心架构、缓存系统、内存技术和专用 AI 加速器方面的全面革新,提供了业界领先的 AI 计算支持。这两款产品为数据中心和高性能计算平台在 AI 推理、训练以及多样化工作负载下提供了强大而高效的算力保障。

△图 1 英特尔高级矩阵扩展(AMX)
英特尔全方位的 AI 软件生态支持
英特尔及其合作伙伴凭借多年 AI 积累,围绕至强®可扩展处理器打造了完善的软件生态:广泛支持主流开源框架,通过插件优化及多样化开源工具链,使用户在 x86 平台上能够轻松开发、部署通用 AI 应用,无需手动调整,同时确保从终端到云的全程安全保护。
此外,至强®处理器内置多种 AI 加速指令(如 AVX-512、AMX),使得任何兼容软件均可直接调用加速功能。开发者可免费下载英特尔分发版工具、库及开发环境,充分利用这些内置加速器应对各类 AI 管线需求。结合多样化硬件优势与开放生态,英特尔通过经济、可扩展的方案,将 AI 能力无缝延伸至云端与边缘。
其中,xFasterTransformer(xFT)是英特尔官方开源的 AI 推理框架,专为大语言模型在至强®平台上深度优化。xFT 不仅支持多种数据精度(FP16、BF16、INT8、INT4),还能利用多 CPU 节点实现分布式部署,显著提升推理性能并降低成本。其简单的安装和与主流 Serving 框架(如 vLLM、FastChat、MLServer、MindSpore Transformer、PaddlePaddle)的兼容性,帮助用户快速加速大模型应用。在 3.1 节中基于天翼云 EMR 云主机和 xFasterTransformer 加速引擎实现了对与 DeepSeek R1 蒸馏模型的高效推理部署。

△图 2 英特尔提供 AI 软件工具全面兼容主流 AI 开发框架
附录 2 CPU 环境下部署 DeepSeek-R1 671B 模型实践
环境配置
硬件配置
- CPU:Intel®Xeon®6980P Processor, 128core 2.00 GHz
- 内存 24*64GB DDR5-6400
- 存储 1TB NVMe SSD
软件环境
- OS: Ubuntu 22.04.5 LTS
- Kernel: 5.15.0-131-generic
- llama.cpp: github bd6e55b
- cmake: 3.22.0
- gcc/g++: 11.4.0
- Python: 3.12.8
- git: 2.34.1
BIOS⾥关闭 sub NUMA 相关配置。
注:版本是指本测试中服务器上安装的版本,并⾮要求的最低版本。
部署步骤
1. 安装 llama.cpp
参考 llama.cpp 官⽹的安装说明,我们的步骤如下。
# 下载 llama.cpp 推理框架源码 git clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp# 预先准备 intel oneapi 库 source /opt/intel/oneapi/setvars.sh# 基于 oneapi 库对 llama.cpp 进行编译 cmake -B build -DGGML_BLAS=ON -DGGML_BLAS_VENDOR=Intel10_64lp -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx -DGGML_NATIVE=ON cmake --build build --config Release -j$nproc
2. 下载模型⽂件
我们直接使用了社区制作的 DeepSeek 671B 满血模型的 Q4 量化版,您也可以下载 DeepSeek 官方 BF16 版本,并通过 llama.cpp 提供的脚本转换为 GGUF 格式。
社区提供了从 1bit 到 8bit 不同版本的量化选项,具体区别可以参考社区网页。我们选择了使用最受欢迎的 Q4_K_M 版本。如果追求最佳效果,建议使用 Q8_0 版本。

# 下载 unsloth 制作的社区版量化模型(hf-mirror 和 modelscpoe 源都可) git clone —no-checkout https://hf-mirror.com/unsloth/DeepSeek-R1-GGUFcd DeepSeek-R1-GGUF/# 建议 nohup 执行, 预计至少需要半天时间, 同时确保磁盘容量足够 400G.git lfs pull —include=”DeepSeek-R1-Q4_K_M/*”
Q4_K_M 版本的文件大小为 404.43GB,下载过程可能会比较耗时。下载完成后,您可以在 DeepSeek-R1-Q4_K_M 目录下找到一系列 .gguf 文件,例如 DeepSeek-R1-Q4_K_M-00001-of-00009.gguf。
3. 模型加载和运⾏
使用 llama-cli,指定模型文件路径并启用交互模式,DeepSeek R1 满血版就可以在 CPU 上顺利运行了。
build/bin/llama-cli -m /tmp/DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00001-of- 00009.gguf -i
下面用几个示例展现 DeepSeek-R1 671B 满血版强大的的 reasoning 推理能力:
测试模型自我认知:
验证推理能⼒的经典“草莓”问题:

“等灯等灯”的意思:

4. 性能及优化
那么 CPU 运⾏满⾎版 R1 的性能怎么样呢?我们做了相关性能测试。对于 Q4_K_M模型,使⽤如下命令进行:
export MODEL_PATH=/tmp/DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00001-of-00009.ggufnumactl -C 0-127 -m 0 ./build/bin/llama-cli -m $MODEL_PATH -t 128 —temp 0.6 -s 42 -no-cnv —no-kv-offload -ctk q4_0 -c 8192 -n 128 -p “<|User|>以孤独的夜行者为题写一篇 750 字的散文,描绘一个人在城市中夜晚漫无目的行走的心情与所见所感,以及夜的寂静给予的独特感悟。<|Assistant|>”
这⾥使⽤numactl 来指定使⽤单路 CPU (0-127, 6980P 有 128 核),以及这⼀路 CPU 的内存节点(numa0),避免跨 numa 传输以获取最佳性能。
llama.cpp 是本地编译的,编译的时候使⽤Intel oneAPI 可以有效提升它的性能。英特尔尝试⽤了 oneAPI⾥的 Intel C++ 编译器和数学加速库 MKL,结合 jemalloc 内存管理优化,推理速度可以达到每秒 9.7~10 词元 (TPS, tokens per second)。
上⾯的实验是在单路 CPU 上进⾏的,我们⼜在两路 CPU 上各⾃独⽴启动 1 个模型实例,总速度可以达到 14.7TPS (7.32TPS+7.38TPS)。
再进⼀步,英特尔观察到基于现有的 llama.cpp 软件⽅案,在 CPU 平台没有实现⾼效的专家并⾏和张量并⾏等优化,CPU 核⼼利⽤率和带宽资源没有充分发挥出来,6980P 的 128 核⼼运⾏1 个模型还有不少性能储备。预计可以继续增加实例数来获得更好的总 TPS。
另外,通常情况下,CPU 的 SNC (Sub-NUMA Clustering)设置可以获得更⾼的带宽,但是受限于软件并未优化实现良好匹配,此次实验关闭了 SNC 测试。
以下⽅式的系统配置也有助于提升性能:
- BIOS⾥关闭 AMP prefetcher
- ⽤cpupower 打开 CPU 的 pstate 性能模式
- 提⾼CPU 的 uncore 频率
- 关闭超线程(Hyper-Threading)
注: 为了加快试验进度,我们限制了词元输出⻓度(-n 128)。经过验证,增加输出⻓度(例如-n 512) 对于生成性能指标的影响不大。






