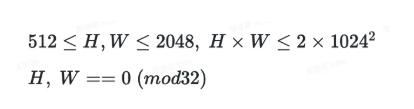智谱宣布推出「智谱 2025 开源年」的第一个模型:首个支持生成汉字的开源文生图模型 CogView4,遵循 Apache2.0 协议。
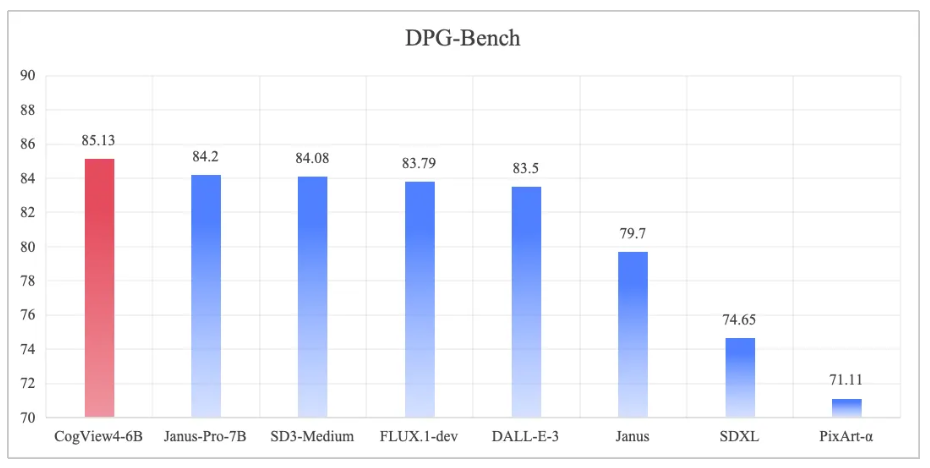
公告称,CogView4 在 DPG-Bench 基准测试中的综合评分排名第一,在开源文生图模型中达到 SOTA,也是首个遵循 Apache 2.0 协议的图像生成模型。
最新的 CogView4-0304 版本现已开源,并将于 3 月 13 日上线智谱清言(chatglm.cn)。后续,该公司还计划陆续增加 ControlNet、ComfyUI 等生态支持,全套的微调工具包也即将推出。
性能 SOTA
CogView4 具备较强的复杂语义对齐和指令跟随能力,支持任意长度的中英双语输入,能够生成在给定范围内的任意分辨率图像,同时具备较强的文字生成能力。
中文理解与生成
CogView4 支持中英双语提示词输入,擅长理解和遵循中文提示词,是首个能够在画面中生成汉字的开源文生图模型,能更好地满足广告、短视频等领域的创意需求。
在技术实现上,CogView4 将文本编码器从纯英文的 T5 encoder 换为具备双语能力的 GLM-4 encoder,并通过中英双语图文进行训练,使模型具备双语提示词输入能力。
任意分辨率,任意长度提示词
CogView4 支持输入任意长度提示词,能够生成范围内任意分辨率图像,不仅使用户创作更加自由,也提升了训练效率。CogView4 模型实现了任意长度的文本描述(caption)和任意分辨率图像的混合训练范式。
1. 图像位置编码
CogView4 采用二维旋转位置编码(2D RoPE)来建模图像的位置信息,并通过内插位置编码的方式支持不同分辨率的图像生成任务。
2. 扩散生成建模
模型采用 Flow-matching 方案进行扩散生成建模,并结合参数化的线性动态噪声规划,以适应不同分辨率图像的信噪比需求。
3. 架构设计
在 DiT 模型架构上,CogView4 延续了上一代的 Share-param DiT 架构,并为文本和图像模态分别设计独立的自适应 LayerNorm 层,以实现模态间的高效适配。
4. 多阶段训练
CogView4 采用多阶段训练策略,包括基础分辨率训练、泛分辨率训练、高质量数据微调以及人类偏好对齐训练。这种分阶段训练方式不仅覆盖了广泛的图像分布,还确保生成的图像具有高美感并符合人类偏好。
5. 训练框架优化
从文本角度,CogView4 突破了传统固定 token 长度的限制,允许更高的 token 上限,并显著减少了训练过程中的文本 token 冗余。当训练 caption 的平均长度在 200-300 token 时,与固定 512 token 的传统方案相比,CogView4 减少了约 50% 的 token 冗余,并在模型递进训练阶段实现了 5%-30% 的效率提升。
混合分辨率训练使模型能够支持较大范围内的任意分辨率生成,极大地提升了创作的自由度。目标分辨率只需满足以下条件: