
新智元报道
编辑:英智
LMM 在人类反馈下表现如何?新加坡国立大学华人团队提出 InterFeedback 框架,结果显示,最先进的 LMM 通过人类反馈纠正结果的比例不到 50%!
大规模多模态模型(Large Multimodal Models,LMM)在人类反馈下的表现如何?
这一问题对于利用 LMM 开发通用 AI 助手至关重要,现有的基准测试并未针对 LMM 与人类的交互智能进行测试。
来自新加坡国立大学的华人团队提出了 InterFeedback,一个可应用任何 LMM 和数据集的交互式框架。

论文链接:https://arxiv.org/abs/2502.15027
在此基础上,团队引入了 InterFeedback-Bench,用两个具有代表性的数据集(MMMU-Pro 和 MathVerse)来评估交互智能,并对 10 种不同的 LMM 进行测试。
InterFeedback-Bench 旨在全面评估 LMM:
1)交互式解决问题的能力;
2)解释反馈以提升自身的能力。
评估结果表明,最先进的 LMM 通过人类反馈纠正结果的比例不到 50%!
交互式过程可提升大多数 LMM 解决难题的性能,现有 LMM 在解释和整合反馈方面表现欠佳。进行额外迭代不一定能得出正确的解决方案,高质量反馈至关重要。
人类在解决问题时,具有很强的适应性,能够从反馈中不断学习完善。同样,先进的 LMM 也应该能从反馈中学习,提高解决问题的能力。
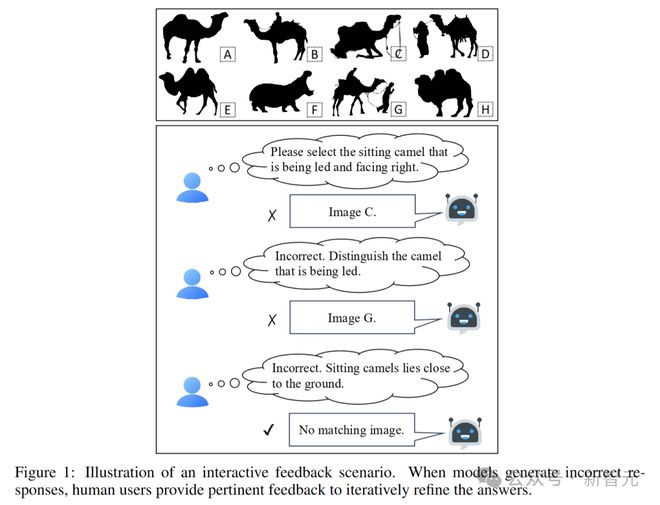
评估 LMM 交互智能的关键挑战在于自动模型测试,不同模型对相同查询的响应不同,需要人类在每个对话轮次中提供定制化反馈。
InterFeedback 框架设计原理
研究人员提出了 InterFeedback,这是一个基于交互式问题解决的框架,通过 GPT-4o 等模型模拟人类反馈,让 LMM 在动态的交互环境中进行测试和学习。
InterFeedback-Bench 将带有反馈的交互式问题解决过程,变成了一种数学模型,叫部分可观测马尔可夫决策过程(POMDP)。
通过状态空间、观测值、动作空间、转移函数和奖励函数等要素,精确地描述模型在交互过程中的行为和决策。
在实际应用中,当给定自然语言问题和输入图像时,模型基于当前状态获取观测值,生成自然语言回复。奖励函数通过精确匹配的方式判断任务的正确性,为模型提供反馈信号。
数据集构建
InterFeedback-Bench 采用了两个有挑战性的数据集:MathVerse 和 MMMU-Pro。
MathVerse 是一个视觉数学问题数据集,其中包含了各种需要结合图像和数学知识才能解决的问题。
MMMU-Pro 则是综合性的多模态基准测试,涵盖了多个领域的专家级问题,包括科学、技术、工程和数学等。
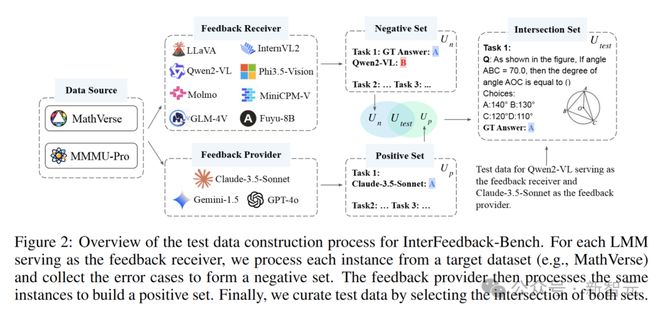
通过巧妙地利用 LMM(例如 GPT-4o)来模拟人机交互,构建出具有针对性的测试数据集。
具体而言,通过选择反馈提供模型M_p答对,而反馈接收模型M_r答错的交集,确保反馈的相关性和可靠性。
InterFeedback 框架
InterFeedback 框架有两个角色:反馈接收者M_r和反馈提供者M_p。
M_r是准备接受基准测试的 LMM,如 Qwen2-VL,M_p是当前最优的 LMM,如 GPT-4o,用于在每个时间步代替人类提供反馈。
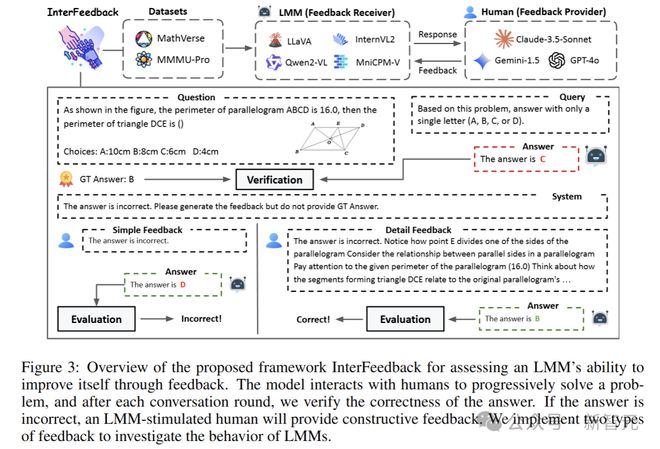
当M_r模型生成输出后,M_p会根据映射策略提供反馈,模型则根据反馈进行改进,如此循环,直到得到正确答案或达到预设的迭代次数。
在这个过程中,M_r根据当前的状态和观测信息,生成相应的动作。M_p则根据模型的回答,提供反馈信息,帮助模型改进自己的回答。
基于 InterFeedback 框架,团队构建了 InterFeedback-Bench 基准测试。这个基准测试旨在全面评估 LMM 交互式问题解决和反馈学习的能力。
人类评估基准测试
除了自动基准测试,研究团队还收集了 InterFeedback-Human 数据集,用于人工评估闭源模型。
与自动基准测试不同,InterFeedback-Human 数据集的评估过程更注重人类的参与和反馈。用户根据模型的回答,提供详细的反馈信息,包括问题的分析、正确的思路和答案等。
通过这种方式,可以更深入地了解模型在实际人机交互中的表现,以及它们理解和处理人类反馈的能力。
实验结果与分析
研究人员设计了一系列实验,在 MathVerse 和 MMMU-Pro 两个具有代表性的数据集上,对多个开源 LMM 进行了全面评估。
用准确率和纠错率来评估结果,纠错率定义为所有错误样本中被纠正答案的样本所占的百分比。N表示样本总数,N_e表示错误样本的数量,N_c表示已被纠正的样本数量。
准确率和纠错率可以用以下公式表示:
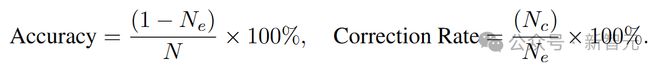
交互过程能提高性能
实验结果表明,交互式过程对大多数 LMM 的性能提升有显著的促进作用。
InterFeedback 框架能使大多数模型从 GPT-4o 和 Claude-3.5-Sonnet 等提供的反馈中受益。
例如,即使是性能较弱的 Fuyu-8B 模型,通过 GPT-4o 的反馈也能纠正 24.1% 的错误样本。这表明交互过程可以有效提高大多数 LMM 解决问题的能力。
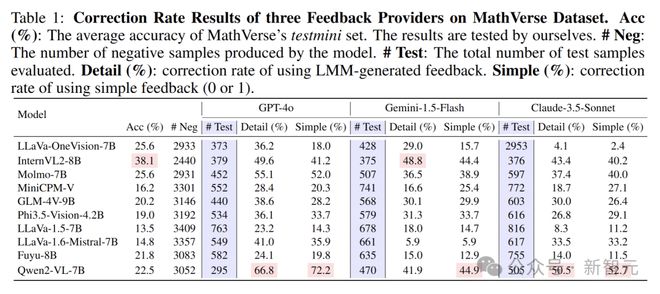
难以通过反馈提升性能
尽管有先进模型提供的反馈,但大多数 LMM 仍难以纠正所有错误样本。
以 Qwen2-VL-7B 和 Molmo 为例,Qwen2-VL-7B 在 MathVerse 数据集上使用 GPT-4o 的反馈时,纠错率为 66.8%,但在 MMMU-Pro 数据集上仅为 50.4%。
Molmo-7B 在 MathVerse 和 MMMU-Pro 数据集上的纠错率分别为 55.1% 和 51.7%,其余模型的纠错率普遍低于 50%。
即使有 LMM 提供的反馈,当前的模型在通过反馈提升自身性能方面仍存在较大困难。
准确率可能无法反映模型能力
实验发现,准确率可能无法真实、全面地反映模型的实际能力。
例如,InternVL2-8B 的准确率较高(38.1%),但其纠错率仅为 49.6%。而准确率较低(22.5%)的 Qwen2-VL-7B 在使用 GPT-4o 的反馈时,却达到了最高的纠错率 66.8%。
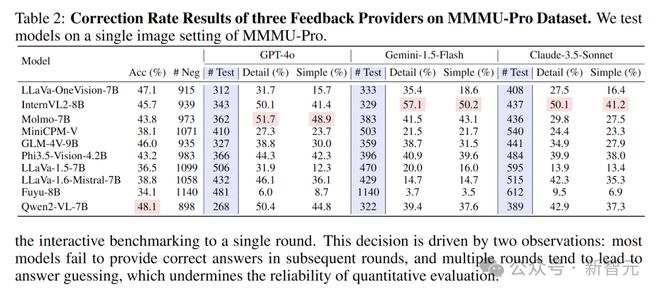
在 MMMU-Pro 数据集上也有类似情况,LLaVA-OneVision-7B 的准确率排名第二(47.1%),但其纠错率仅为 31.7%,低于几个准确率较低的模型。
这表明仅通过准确率评估模型,可能无法全面体现其真实能力。
反馈质量至关重要
令人惊讶的是,所有模型都能从简单的二元(0/1)反馈中受益。
同时,研究发现反馈质量至关重要,低质量反馈对性能的损害比简单的二元反馈更大。
在 MathVerse 数据集上,对于一些模型,使用次优模型(Gemini-1.5-Flash)提供的简单二元反馈,其效果优于 LMM 生成的详细反馈。
人工基准测试的分析
在对 OpenAI-o1、GPT-4o、Gemini-2.0 和 Claude-3.5-Sonnet 等闭源模型的人工评估中,Claude-3.5 的平均准确率最高,达到了 48.3%。
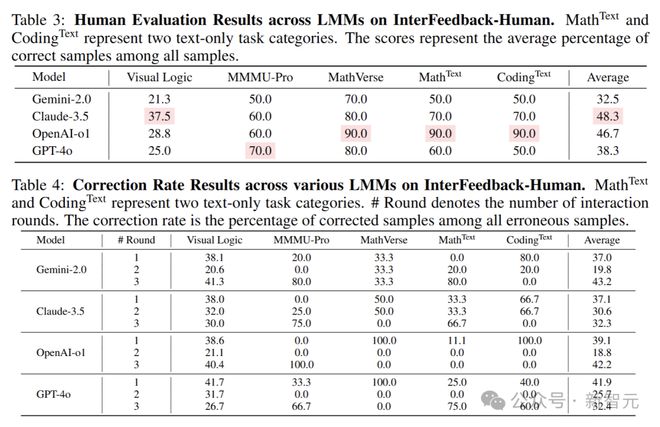
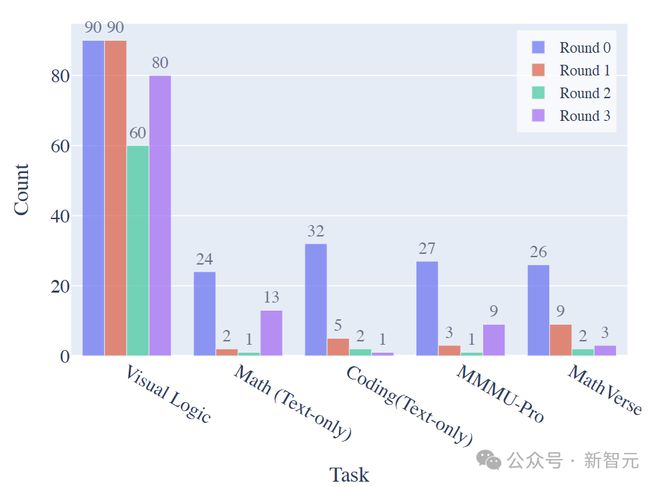
从纠正率结果分析来看,不同模型从人类反馈中获益的轮次和程度存在明显差异。
GPT-4o 在第一轮反馈中能够纠正 41.9% 的错误样本,显示出其对人类反馈的快速响应和学习能力。
Claude-3.5 则在第二轮反馈中展现出强大的纠正性能,成功纠正了 30.6% 的错误样本。在第三轮,由于提供了真实答案,所有 LMM 都能够给出选择正确答案的推理步骤。
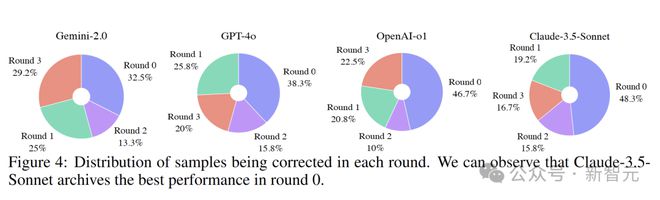
此外,不同任务类别中被纠正样本的分布也有所不同。
视觉逻辑任务大多在前两轮就能够得到有效解决,而纯文本数学任务和 MMMU-Pro 任务在前两轮的纠正相对较少。
相比之下,纯文本编码任务和 MathVerse 任务在前两轮也出现了一定比例的纠正,说明模型在这些领域具有一定的学习和改进能力。
参考资料:






