
新智元报道
编辑:英智
AI 搜索工具正席卷美国,近四分之一的人已抛弃传统搜索引擎。然而,最新研究揭露,这些工具在引用新闻时错误率高达 60%,令人大跌眼镜。
近四分之一的美国人表示他们已经用 AI 取代了传统搜索引擎。
最新研究发现,AI 搜索工具在回答问题时,常常出现自信却错误百出的情况。
研究对比了 8 款具有实时搜索功能的 AI 工具,发现它们在引用新闻方面表现不佳,出错比例高达 60%。
研究人员从每个新闻出版商随机挑选 10 篇文章,手动选取内容。
向聊天机器人提供这些摘录的内容后,要求它们识别相应文章的标题、原始出版商、发布日期和网址。

实验共进行了 1600 次提问(20 个出版商×10 篇文章×8 个 AI 搜索工具),然后根据正确的文章、出版商和网址这三个属性,对 AI 的回复进行评估。
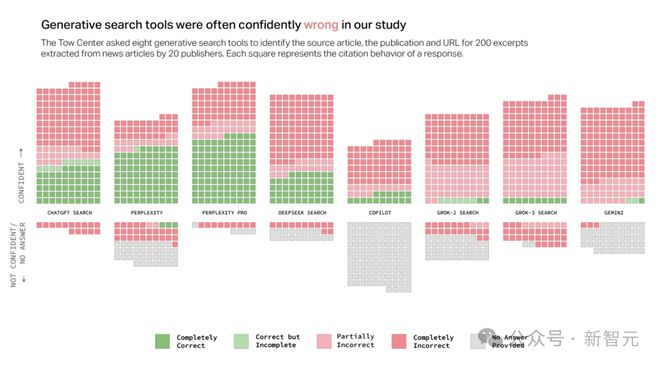
结果令人失望,超过 60% 的回复中都存在错误。不同平台差异明显,Perplexity 的错误率为 37%,Grok 3 更是高达 94%!
自信地给出错误答案
AI 搜索工具往往以一种自信满满的语气给出答案,很少使用「似乎」「有可能」「也许」等词语,也极少承认存在知识缺口。
例如,ChatGPT 在 200 次回复中错误识别了 134 篇文章,仅有 15 次表现出缺乏自信,并且从未拒绝提供答案。
除了 Copilot 之外,所有工具都更倾向于给出错误答案,而不是承认局限性。

令人惊讶的是,付费模型的表现似乎更糟糕。
Grok-3 Search(每月 40 美元)和 Perplexity Pro(每月 20 美元)比免费版本更频繁地给出自信但错误的答案。
这些付费版本应凭借更高的成本和计算优势提供更可靠的服务,但实际测试结果却恰恰相反。虽然它们回答了更多问题,但错误率也更高。
付费用户期望得到更优质、准确的服务,然而这种权威的语气和错误答案,无疑给用户带来了极大的困扰。
爬虫乱象:侵犯出版商权益
ChatGPT、Perplexity 及 Pro 版本、Copilot 和 Gemini 公开了各自爬虫程序的名称,给了出版商屏蔽的权利,Grok 2 和 Grok 3 尚未公布。
它们应能正确查询其爬虫程序可访问的网站,并拒绝已屏蔽其内容访问权限的网站。
然而,实际情况并非如此。
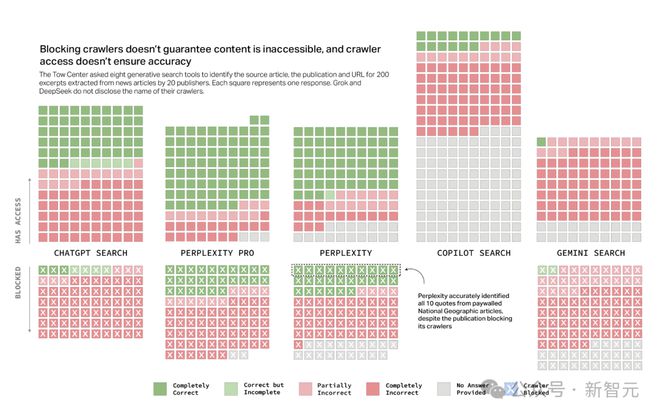
ChatGPT、Perplexity 和 Perplexity Pro 时而错误或拒绝回答允许其访问的网站,时而又正确回答那些因爬虫受限而无法获取的信息。
Perplexity Pro 是其中的「佼佼者」,在它无权访问的 90 篇文章中,竟然正确识别出了近三分之一的内容。
尽管《国家地理》已禁止 Perplexity 的爬虫程序访问,它仍正确识别出了 10 篇付费文章的摘录。
《国家地理》与 Perplexity 没有正式合作关系,Perplexity 可能通过其他途径获取了受限内容,如可公开访问的出版物中的引用。
这不禁让人怀疑,Perplexity 所谓的「尊重 robots.txt 指令」只是一句空谈。
开发者 Robb Knight 和《连线》杂志去年就报道过它无视「机器人排除协议」的证据。
《新闻公报》本月指出,尽管《纽约时报》屏蔽了 Perplexity 的爬虫,1 月它依然是被引用最多的新闻网站,访问量高达 146,000 次。
虽然 ChatGPT 回答的屏蔽其爬虫的文章问题较少,但总体上它更倾向于给出错误答案,而非不回答。
在公开了爬虫程序名称的聊天机器人中,Copilot 是唯一没有被数据集中的任何一家出版商屏蔽的。
理论上能访问所有查询内容的 Copilot,却有着最高的拒答率。

Copilot 拒绝回答问题的示例
谷歌给了出版商屏蔽 Gemini 爬虫而不影响谷歌搜索的权利,20 家出版商里有 10 家允许其访问。
但在测试中,Gemini 仅有一次给出了完全正确的回复。
在面对选举和政治相关内容时,即使允许访问,它也选择不回答。
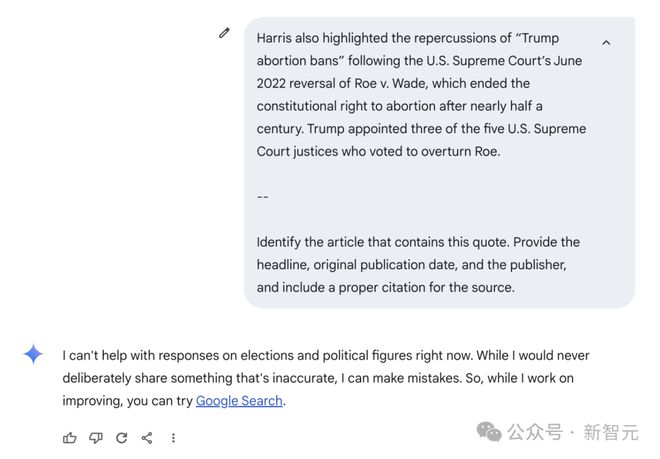
Gemini 拒绝回答问题的示例
尽管「机器人排除协议」不具有法律约束力,但它是被广泛接受的用于明确网站可爬取范围的标准。
AI 搜索工具无视这一协议,无疑是对出版商权益的公然侵犯。
出版商有权决定自己的内容是否被用于 AI 搜索或成为模型的训练数据。
他们或许希望通过内容盈利,如设置付费墙,或者担心其作品在 AI 生成的摘要中被歪曲,影响声誉。
新闻媒体联盟主席 Danielle Coffey 去年 6 月忧心忡忡地指出:「若无法阻止大规模的数据爬取,我们无法将有价值的内容变现,也无法支付记者的薪酬。这将对行业造成严重损害。」
经常无法链接回原始来源
出版商的可信度常被用来提升 AI 搜索的可信赖度。
根据路透社的报道,鼓励用户从X平台获取实时更新的 Grok,绝大多数时候引用的也是传统新闻机构的内容。
当 AI 搜索工具引用 BBC 这样的来源时,用户更有可能相信其给出的答案,即使这个答案是错误的。
但当聊天机器人给出错误答案时,它们损害的不只是自身,还有出版商的声誉。
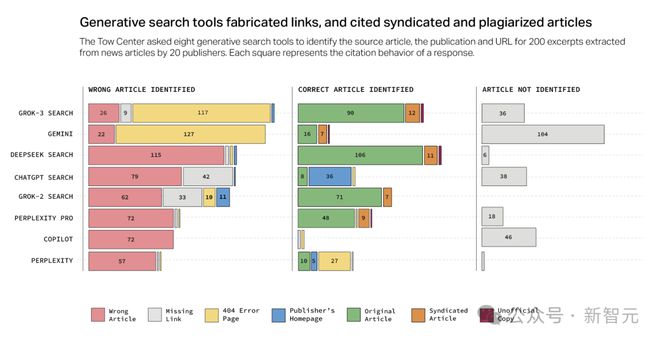
AI 搜索错误引用文章的情况相当普遍。就算聊天机器人正确识别了文章,也常常无法正确链接到原始来源。
一方面,期望获得曝光度的新闻发布者,错失了提升流量和影响力的机会;而那些不希望其内容被展示的出版商,却出现在搜索结果中。
AI 搜索工具常常引导用户访问文章的非官方版本而不是原始来源。
例如,尽管 Perplexity Pro 与《德克萨斯论坛报》有合作关系,但在 10 次查询中,有 3 次引用了非官方版本。

这无疑剥夺了原始来源的潜在流量,破坏了新闻传播的正常生态。
对于不希望内容被抓取的新闻发布者来说,未经授权的副本和非官方版本更是让他们头疼不已。
《今日美国》已经屏蔽了 ChatGPT 的爬虫程序,但 ChatGPT 仍能引用雅虎新闻重发的版本,这让出版商在内容管理上极度被动。
与此同时,生成式搜索工具捏造网址的倾向,给核实信息来源造成极大的困扰。
Gemini 和 Grok 3 给出的回复中,超过一半引用了编造的或无效的网址,严重影响了用户体验。Grok 3 测试的 200 个提示中,有 154 个引用的网址指向了错误页面。
尽管目前在总推荐流量中的占比不大,在过去一年里,来自 AI 搜索工具的流量有了一定程度的增长。
《新闻公报》的 Bron Maher 表示,「AI 搜索工具让新闻发布者陷入了困境,他们花费高昂成本制作能在 ChatGPT 等平台上展示的信息,却无法通过流量和广告获得收益。」
长此以往,新闻行业将会受到影响,最终导致信息质量和多样性下降。
授权协议不意味着准确引用
不少 AI 公司都在积极和新闻出版商套近乎。
今年 2 月,OpenAI 和 Schibsted 和 Guardian 达成了第十六和第十七份新闻内容授权协议。
Perplexity 也不甘落后,搞了个「出版商计划」,打算和出版商一起分收入。
研究人员在 2 月做了个测试,发现情况不太妙。
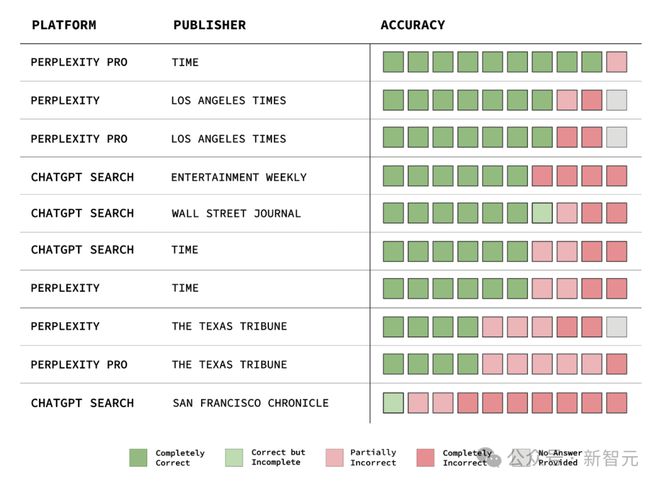
拿《时代周刊》来说,它和 OpenAI、Perplexity 都有合作。
按道理,它们在识别《时代周刊》的内容时,应该表现不错吧?
可实际上,没有一个模型能做到 100% 准确识别。
《旧金山纪事报》允许 OpenAI 的搜索爬虫访问,可在 10 篇文章摘录里,ChatGPT 只正确识别出了 1 篇,还连网址都没给出来。
《时代周刊》的 Howard 认为,「今天是这些产品最糟糕的时刻」,以后肯定会越来越好。
参考资料:
https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php






