
新智元报道
编辑:LRST
澳大利亚国立大学团队提出了 ARINAR 模型,与何凯明团队此前提出的分形生成模型类似,采用双层自回归结构逐特征生成图像,显著提升了生成质量和速度,性能超越了 FractalMAR 模型,论文和代码已公开。
前不久,大神何恺明刚刚放出新作「分形生成模型」,递归调用原子生成模块,构建了新型的生成模型,形成了自相似的分形架构,将 GenAI 模型的模块化层次提升到全新的高度。

论文地址: https://arxiv.org/pdf/2502.17437v1
GitHub 地址:https://github.com/LTH14/fractalgen
最近,澳大利亚国立大学的研究人员提出了一个全新的图像生成模型 ARINAR,在思想上与分形生成模型不谋而合,但是在性能和速度上都显著提升,base 模型的 FID 从 11.8 提升到 2.75,生成时间从 2 分钟降低到 12 秒!ARINAR 不仅超越了之前的扩散模型,与目前表现最好的自回归模型 MAR 相比,ARINAR 生成质量相当,速度是 MAR 的 5 倍。

论文链接: https://arxiv.org/abs/2503.02883
GitHub 地址:https://github.com/Qinyu-Allen-Zhao/Arinar
ARINAR 全称是双层自回归逐特征生成模型(Bi-Level Autoregressive Feature-by-Feature Generative Models),核心思想在于:通过逐特征生成的方式生成 tokens,从而提高整体图像生成的质量和速度。
设计动机
现有的自回归(AR)图像生成模型通常采用逐 token 生成的方式。具体来说,模型会首先预测第一个 token 的分布,根据这个分布采样出第一个 token,然后基于这个 token 生成下一个 token 的分布,再采样出第二个 token,依此类推,直到生成完整的图像。
这里的 token 可以理解为图像的某种表示形式,通常是使用自编码器(如 VAE)实现图像与一系列 tokens 之间的转换。每个 token 可以看作图像的一个局部区域或特征的编码。
研究人员指出,逐 token 生成的核心挑战在于如何建模高维 token 的复杂分布。每个 token 通常是一个高维向量(例如 16 维)。当模型需要预测下一个 token 的分布时,如何准确地表达和预测该 token 的分布一直是一个难题。
现有的方法主要有两种思路:
-
离散 token 生成:一些方法使用特殊的自编码器(如 VQVAE)将图像转换为离散的 token,然后使用多项式分布来建模 token 的分布。这种方法的问题在于,离散化会引入量化误差,导致生成图像的质量下降。
-
连续 token 生成:另一些模型尝试直接建模连续 token 的分布。
例如,GIVT 模型使用高斯混合模型(GMM)来预测 token 的分布,并从 GMM 中采样生成 token。然而,实践中 GMM 难以准确拟合复杂的高维 token 分布;
另一种方法是 MAR 模型,使用轻量级的扩散模型来生成 token。虽然扩散模型能够更好地拟合分布,但扩散过程通常需要上百次迭代,导致整个模型生成速度较慢。
这些方法的局限性在于,要么过于简单,无法很好地拟合复杂的 token 分布,要么生成速度较慢。
因此,研究人员提出了一个新的思路:逐特征生成。
具体来说,模型每次不再一次性生成整个 token,而是逐特征生成。每个 token 由多个特征组成(例如 16 维),模型会先生成第一个特征的分布并采样出第一个特征,然后基于这个特征生成第二个特征的分布,再采样出第二个特征,依此类推,直到生成整个 token。
方法设计
ARINAR 模型的设计分为两层自回归结构:
外层自回归层:这一层负责生成 token 的条件向量。具体来说,它基于已经生成的 token,预测下一个 token 的条件向量。这里外层可以是任意之前的自回归模型,例如使用 MAR。
内层自回归层:这一层基于外层生成的条件向量,逐特征生成下一个 token。具体来说,内层会先生成第一个特征,然后基于这个特征生成第二个特征,依此类推,直到生成整个 token。
假如一个图像被转换成 256 个 16 维的 tokens,那么外层自回归模型就会运行 256 次,每次预测下一个 token 的条件向量。每次外层自回归模型生成条件向量后,内层自回归模型就会运行 16 次来逐特征生成相应的 token。

这种双层结构的好处是,内层自回归只需专注于单个特征的生成,而不需要一次性建模整个 token 的分布。因此,内层可以使用简单的高斯混合模型(GMM)来建模单个特征的分布,从而大大简化了预测 token 分布的难度。
与 FractalMAR 的关系
在论文中,研究人员提到了一个与之类似的工作 FractalMAR,也是一个多层自回归模型,但它是在像素空间中逐像素生成图像的。
也就是说,FractalMAR 的每一层都负责生成图像的不同部分,从大块区域到单个像素。例如使用一个四层自回归模型:
-
最外层生成整个图像的大块区域;
-
第二层生成每个大块区域中的小块区域;
-
第三层生成每个小块区域中的像素;
-
最内层生成每个像素的 RGB 值。
相比之下,ARINAR 是在特征空间中逐特征生成图像的。ARINAR 使用了自编码器将图像转换为连续的特征表示,然后在这些特征上依赖 GMM 进行逐特征生成。
研究人员强调,虽然 ARINAR 和 FractalMAR 的设计思路相似,但 ARINAR 在性能和速度上都优于 FractalMAR。ARINAR 可以看作是 FractalMAR 在潜在空间中的版本。
实验结果
研究人员在 ImageNet 256×256 图像生成任务上对 ARINAR 进行了测试,使用了 213M 参数的模型(ARINAR-B)。实验结果显示:
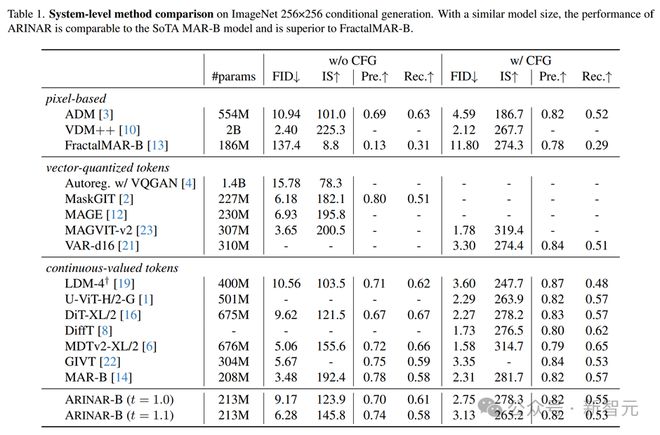
生成质量上,ARINAR-B 在没有使用 CFG(classifier-free guidance)的情况下,FID(Frechet Inception Distance)得分为 9.17,使用 CFG 后,FID 得分提升到 2.75,这个结果与当前最先进的 MAR-B 模型(FID=2.31)相当,且显著超过了 FractalMAR。
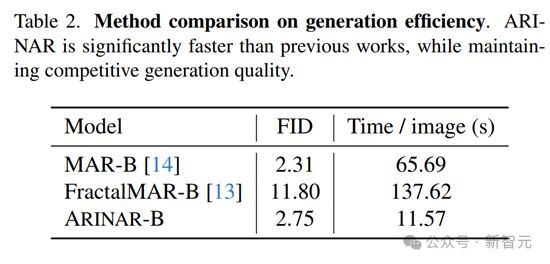
生成速度上,ARINAR-B 生成一张图像的平均时间仅需 11.57 秒,而 MAR-B 需要 65.69 秒,FractalMAR-B 则需要 137.62 秒。ARINAR 在保持高质量生成的同时,显著提升了生成速度。
总结与不足
ARINAR 通过逐特征生成的方式,简化了自回归模型的复杂度,同时提高了生成速度和生成质量。
与 FractalMAR 相比,ARINAR 在潜在空间中生成图像,避免了像素空间的复杂性,从而在性能和速度上都取得了更好的结果。
这篇论文展示了自回归模型在图像生成任务中的巨大潜力,尤其是在生成速度和生成质量之间的平衡上,ARINAR 提供了一个非常有前景的解决方案。
然而,由于计算资源的限制(使用 4 张 A100 GPU),研究人员在这篇论文中只训练了一个基础模型(ARINAR-B),并且训练时间长达 8 天。这确实限制了模型的进一步扩展和更大规模实验的进行。
论文中也提到,研究人员正在寻求更多的计算资源,以便进行更多的实验和训练更大的模型。这意味着未来可能会有更多的研究成果发布,进一步验证 ARINAR 的潜力和可扩展性。
参考资料:






