Toggle navigation
首页
产品中心
全新RDIF.vNext低代码框架
镇店
.NET C/S开发框架
.NET Web敏捷开发框架
.NET 快速开发框架(全新EasyUI版本)
.NET 代码生成器
.NET WebAPI服务端开发框架
客户案例
付款方式
技术文章
文档中心
下载
关于
首页
技术文章
数据库金典
正文
原创
2024-06-25
浏览 (
9806
)
玩转数据库索引
## 1、概述 通常我们要对数据库进行优化,主要可以通过以下五种方法。 1. 计算机硬件调优 2. 应用程序调优 3. 数据库索引优化 4. SQL语句优化 5. 事务处理调优 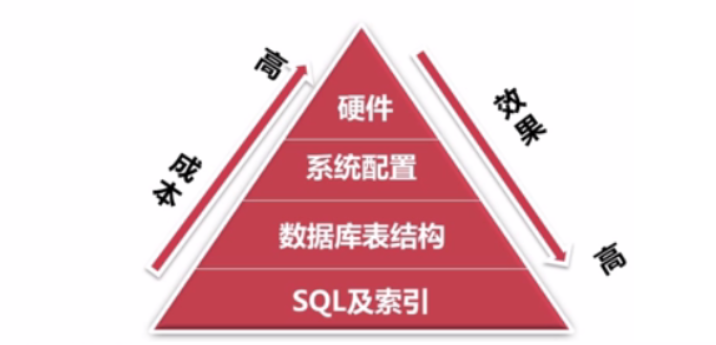 本篇文章将向大家介绍数据库中索引类型和使用场合,本文以SQL Server为例,对于其他技术平台的朋友也是有参考价值的,原理差不多。 查询数据时索引使数据库引擎执行速度更快,有针对性的数据检索,而不是简单地整表扫描(Full table scan)。 为了有效的使用索引,我们必须对索引的构成有所了解,而且我们知道在数据表中添加索引必然需要创建和维护索引表,所以我们要全局地衡量添加索引是否能提高数据库系统的查询性能。 ## 2、数据库中的文件和文件组 在物理层面上,数据库由数据文件组成,而这些数据文件组成文件组,然后存储在磁盘上。每个文件包含许多区,每个区的大小为64K由八个物理上连续的页组成(一个页8K),我们知道**页是SQL Server数据库中的数据存储的基本单位**。为数据库中的数据文件(.mdf 或 .ndf)分配的磁盘空间可以从逻辑上划分成页(从0到n连续编号)。 页中存储的类型有:**数据**,**索引**和**溢出**。 在SQL Server中,通过文件组这个逻辑对象对存放数据的文件进行管理。 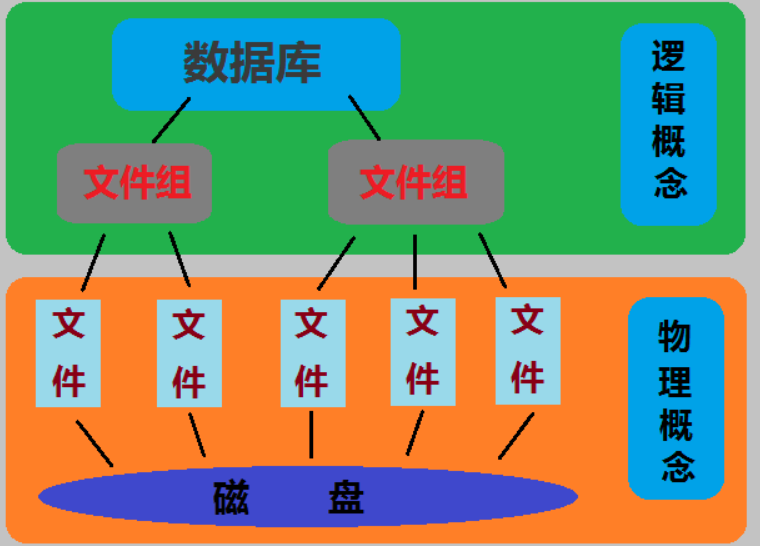 在顶层是我们的数据库,由于数据库是由一个或多个文件组组成,而文件组是由一个或多个文件组成的**逻辑组**,所以我们可以把文件组分散到不同的磁盘中,使用户数据尽可能跨越多个设备,多个I/O 运转,避免 I/O 竞争,从而均衡I/O负载,克服访问瓶颈。 ## 3、区和页 如下图所示,文件是由区组成的,而区由八个物理上连续的页组成,由于区的大小为64K,所以每当增加一个区文件就增加64K。 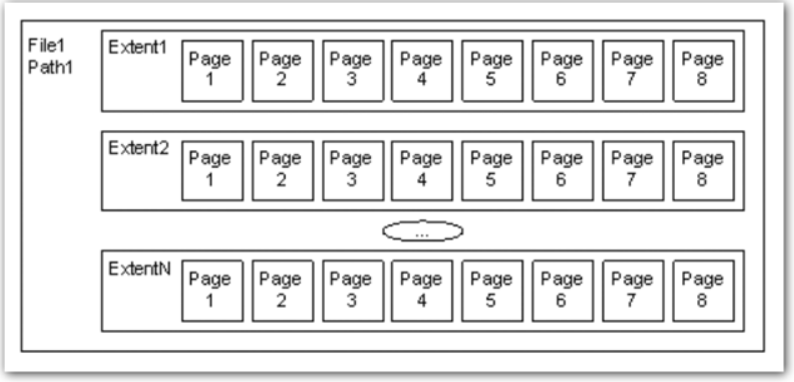 页中保存的数据类型有:表数据、索引数据、溢出数据、分配映射、页空闲空间、索引分配等。 | 页类型 | 内容 | | --------------------------------------------------- | ------------------------------------------------------------ | | Data | 当 text in row 设置为 ON 时,包含除 text、 ntext、image、nvarchar(max)、varchar(max)、varbinary(max) 和 xml 数据之外的所有数据的数据行。 | | Index | 索引条目。 | | Text/Image | 大型对象数据类型:text 、 ntext、image、nvarchar(max)、varchar(max)、varbinary(max) 和 xml 数据。数据行超过 8 KB 时为可变长度数据类型列:varchar 、nvarchar、varbinary 和 sql_variant | | Global Allocation Map、Shared Global Allocation Map | 有关区是否分配的信息。 | | Page Free Space | 有关页分配和页的可用空间的信息。 | | Index Allocation Map | 有关每个分配单元中表或索引所使用的区的信息。 | | Bulk Changed Map | 有关每个分配单元中自最后一条 BACKUP LOG 语句之后的大容量操作所修改的区的信息。 | | Differential Changed Map | 有关每个分配单元中自最后一条 BACKUP DATABASE 语句之后更改的区的信息。 | 在数据页上,数据行紧接着页头(标头)按顺序放置;页头包含标识值,如页码或对象数据的对象ID;数据行持有实际的数据;最后,页的末尾是行偏移表,对于页中的每一行,每个行偏移表都包含一个条目,每个条目记录对应行的第一个字节与**页头**的距离,行偏移表中的条目的顺序与页中行的顺序相反。 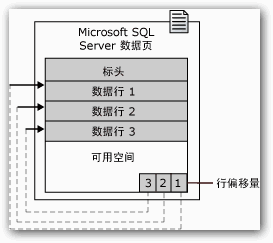 ## 4、索引的基本结构 “索引(Index)提供查询的速度”这是对索引的最基本的解释,接下来我们将通过介绍索引的组成,让大家对索引有更深入的理解。 索引是数据库中的一个独特的结构,由于它保存数据库信息,那么我们就需要给它分配磁盘空间和维护索引表。创建索引并不会改变表中的数据,它只是创建了一个新的数据结构指向数据表;打个比方,平时我们使用字典查字时,首先我们要知道查询单词起始字母,然后翻到目录页,接着查找单词具体在哪一页,这时我们目录就是索引表,而目录项就是索引了。 当然,索引比字典目录更为复杂,因为数据库必须处理插入,删除和更新等操作,这些操作将导致索引发生变化。 **叶节点** 假设我们磁盘上的数据是物理有序的,那么数据库在进行插入,删除和更新操作时,必然会导致数据发生变化,如果我们要保存数据的连续和有序,那么我们就需要移动数据的物理位置,这将增大磁盘的I/O,使得整个数据库运行非常缓慢;使用索引的主要目的是使数据逻辑有序,使数据独立于物理有序存储。 为了实现数据逻辑有序,索引使用双向链表的数据结构来保持数据逻辑顺序,如果要在两个节点中插入一个新的节点只需修改节点的前驱和后继,而且无需修改新节点的物理位置。 [双向链表](http://zh.wikipedia.org/wiki/双向链表)(Doubly linked list)也叫双链表,是[链表](http://zh.wikipedia.org/wiki/链表)的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。 理论上说,从双向链表中删除一个元素操作的时间复杂度是O(1),如果希望删除一个具体有给定关键字的元素,那么最坏的情况下的时间复杂度为O(n)。 在删除的过程中,我们只需要将要删除的节点的前节点和后节点相连,然后将要删除的节点的前节点和后节点置为null即可。 ```sql //伪代码 node.prev.next=node.next; node.next.prev=node.prev; node.prev=node.next=null; ``` 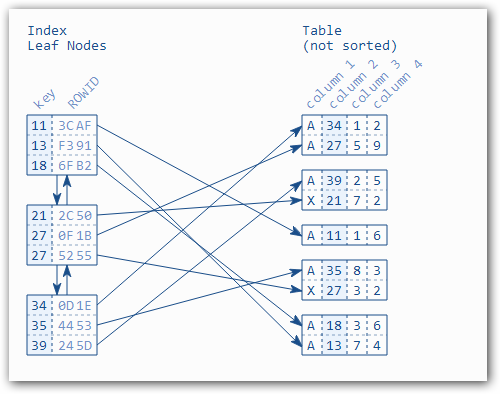 如上图,索引叶节点包含索引值和相应的RID(ROWID),而且叶节点通过双向链表有序地连接起来;同时我们主要到数据表不同于索引叶节点,表中的数据无序存储,它们不全是存储在同一表块中,而且块之间不存在连接。 总的来说,索引保存着具体数据的物理地址值。 ## 5、索引的类型 索引的类型主要有两种:**聚集索引**和**非聚集索引**。 **聚集索引**:物理存储按照索引排序。 指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。 **非聚集索引**:物理存储不按照索引排序。 该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。 ### 5.1、聚集索引 **聚集索引**的数据页是物理有序地存储,数据页是聚集索引的叶节点,数据页之间通过双向链表的形式连接起来,而且实际的数据都存储在数据页中。当我们给表添加索引后,表中的数据将根据索引进行排序。 假设我们有一个表T_Pet,它包含四个字段分别是:animal,name,sex和age,而且使用animal作为索引列,具体SQL代码如下: ```sql ----------------------------------------------------------- ---- Create T_Pet table in tempdb. ----------------------------------------------------------- USE tempdb CREATE TABLE T_Pet ( animal VARCHAR(20), [name] VARCHAR(20), sex CHAR(1), age INT ) CREATE UNIQUE CLUSTERED INDEX T_PetonAnimal1_ClterIdx ON T_Pet (animal) ``` ```sql ----------------------------------------------------------- ---- Insert data into data table. ----------------------------------------------------------- DECLARE @i int SET @i=0 WHILE(@i<1000000) BEGIN INSERT INTO T_Pet ( animal, [name], sex, age ) SELECT [dbo].random_string(11) animal, [dbo].random_string(11) [name], 'F' sex, cast(floor(rand()*5) as int) age SET @i=@i+1 END INSERT INTO T_Pet VALUES('Aardark', 'Hello', 'F', 1) INSERT INTO T_Pet VALUES('Cat', 'Kitty', 'F', 2) INSERT INTO T_Pet VALUES('Horse', 'Ma', 'F', 1) INSERT INTO T_Pet VALUES('Turtles', 'SiSi', 'F', 4) INSERT INTO T_Pet VALUES('Dog', 'Tomma', 'F', 2) INSERT INTO T_Pet VALUES('Donkey', 'YoYo', 'F', 3) ``` 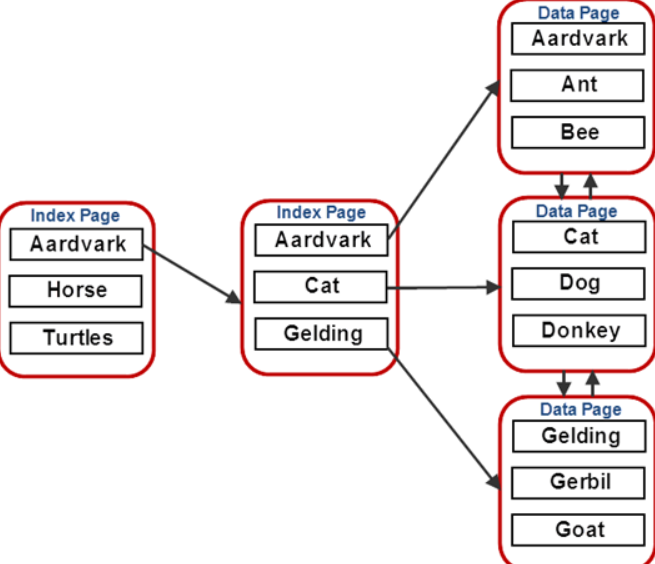 如上图所示,从左往右的第一和第二层是索引页,第三层是数据页(叶节点),数据页之间通过双向链表连接起来,而且数据页中的数据根据索引排序;假设,我们要查找名字(name)为Xnnbqba的动物Ifcey,这里我们以animal作为表的索引,所以数据库首先根据索引查找,当找到索引值animal = ‘Ifcey时,接着查找该索引的数据页(叶节点)获取具体数据。具体的查询语句如下: ```sql SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT animal, [name], sex, age FROM T_Pet WHERE animal = 'Ifcey' SET STATISTICS PROFILE OFF SET STATISTICS TIME OFF ``` 当我们执行完SQL查询计划时,把鼠标指针放到“聚集索引查找”上,这时会出现如下图信息,我们可以查看到一个重要的信息Logical Operation——Clustered Index Seek,SQL查询是直接根据聚集索引获取记录,查询速度最快。 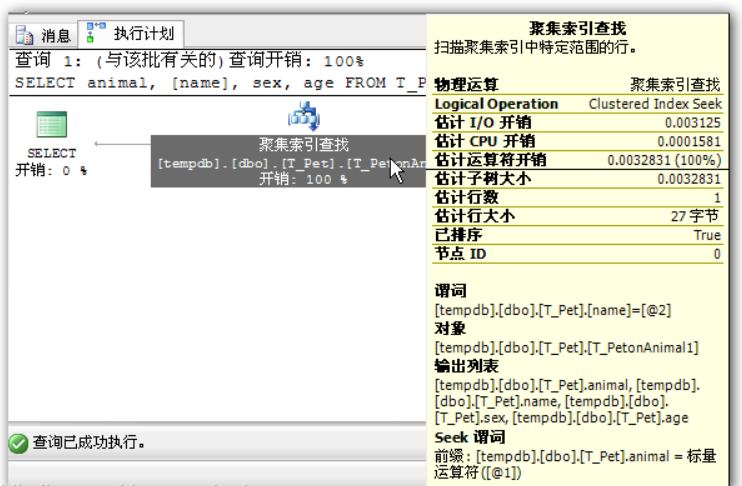 从下图查询结果,我们发现查询步骤只有2步,首先通过Clustered Index Seek快速地找到索引Ifcey,接着查询索引的叶节点(数据页)获取数据。 查询执行时间:CPU 时间= 0 毫秒,占用时间= 1 毫秒。 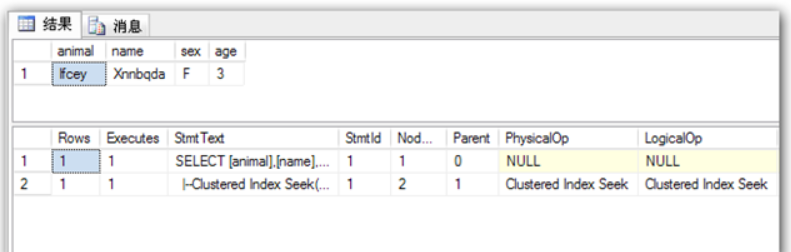 现在我们把表中的索引删除,重新执行查询计划,这时我们可以发现Logical Operation已经变为Table Scan,由于表中有100万行数据,这时查询速度就相当缓慢。 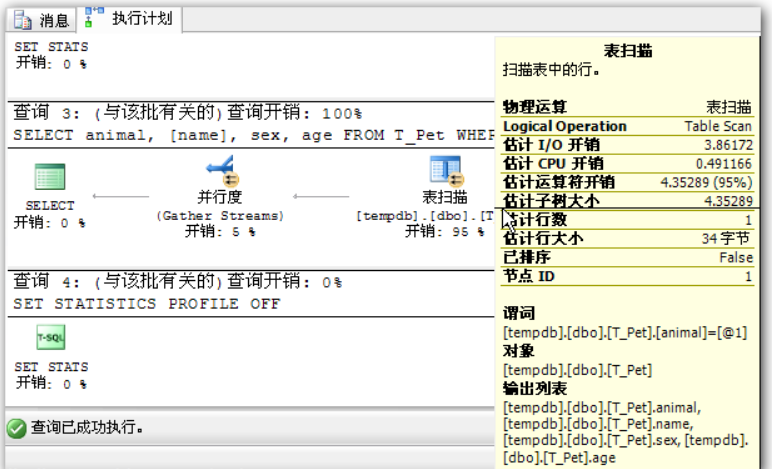 从下图查询结果,我们发现查询步骤变成3步了,首先通过Table Scan查找animal = ‘Ifcey’,在执行查询的时候,SQL Server会自动分析SQL语句,而且它估计我们这次查询比较耗时,所以数据库进行并发操作加快查询的速度。 查询执行时间:CPU 时间= 329 毫秒,占用时间= 182 毫秒。 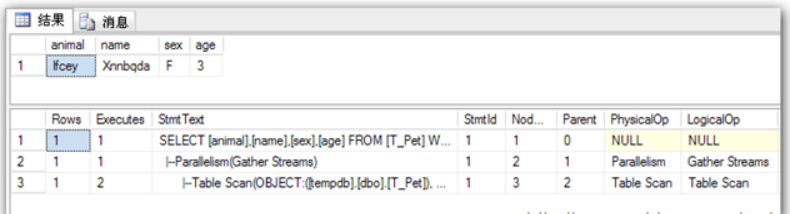 通过上面的有聚集索引和没有的对比,我们发现了查询性能的差异,如果使用索引数据库首先查找索引,而不是漫无目的的全表遍历。 ### 5.2、非聚集索引 在没有聚集索引的情况下,表中的数据页是通过堆(Heap)形式进行存储,堆是不含聚集索引的表;SQL Server中的堆存储是把新的数据行存储到最后一个页中。 **非聚集索引**是物理存储不按照索引排序,非聚集索引的叶节点(Index leaf pages)包含着指向具体数据行的**指针**或**聚集索引**,数据页之间没有连接是相对独立的页。 假设我们有一个表T_Pet,它包含四个字段分别是:animal,name,sex和age,而且使用animal作为非索引列,具体SQL代码如下: ```sql ----------------------------------------------------------- ---- Create T_Pet table in tempdb with NONCLUSTERED INDEX. ----------------------------------------------------------- USE tempdb CREATE TABLE T_Pet ( animal VARCHAR(20), [name] VARCHAR(20), sex CHAR(1), age INT ) CREATE UNIQUE NONCLUSTERED INDEX T_PetonAnimal1_NonClterIdx ON T_Pet (animal) ``` 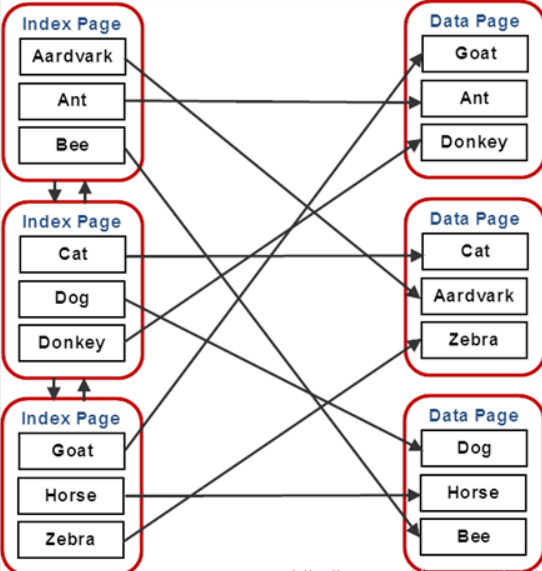 接着我们要查询表中animal = ‘Cat’的宠物信息,具体的SQL代码如下: ```sql SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT animal, [name], sex, age FROM T_Pet WHERE animal = 'Cat' SET STATISTICS PROFILE OFF SET STATISTICS TIME OFF ``` 如下图所示,我们发现查询计划的最右边有两个步骤:RID和索引查找。由于这两种查找方式相对于聚集索引查找要慢(Clustered Index Seek)。 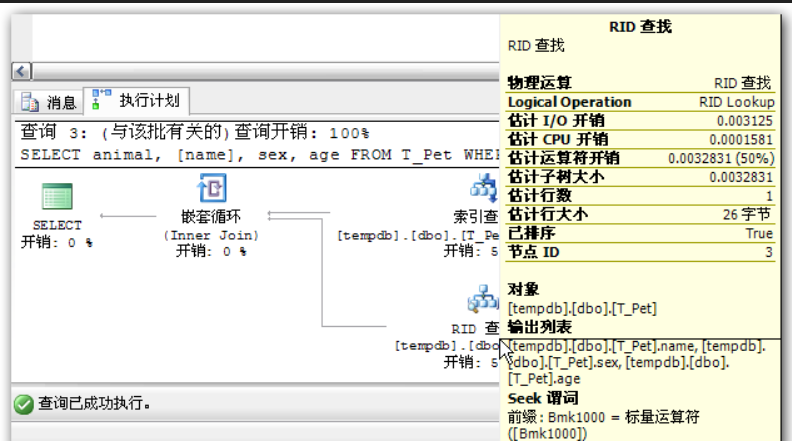 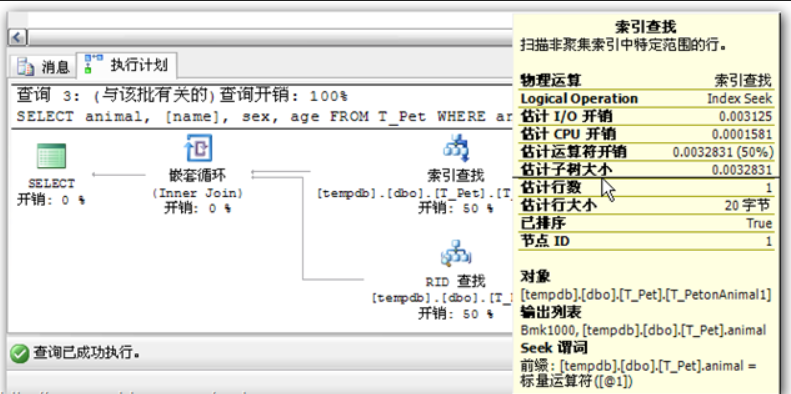 首先SQL Server查找索引值,然后根据RID查找数据行,直到找到符合查询条件的结果。 查询执行时间:CPU 时间= 0 毫秒,占用时间= 1 毫秒 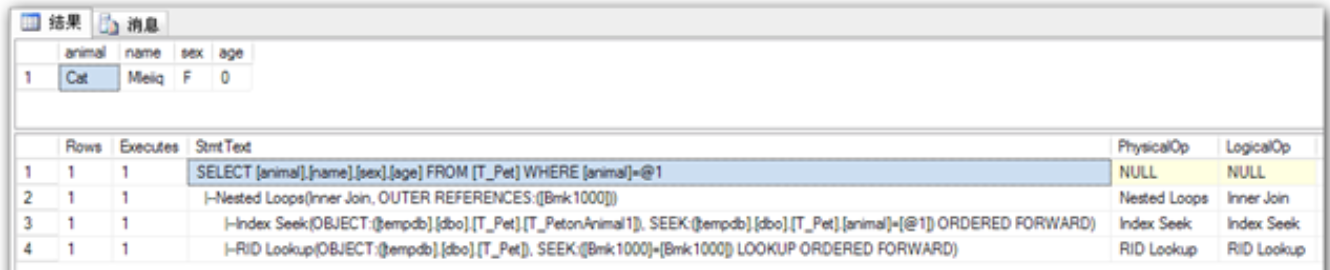 ### 5.3、堆表非聚集索引 由于堆是不含聚集索引的表,所以非聚集索引的叶节点将包含指向具体数据行的指针。 以前面的T_Pet表为例,假设T_Pet使用animal列作为非聚集索引,那么它的堆表非聚集索引结构如下图所示: 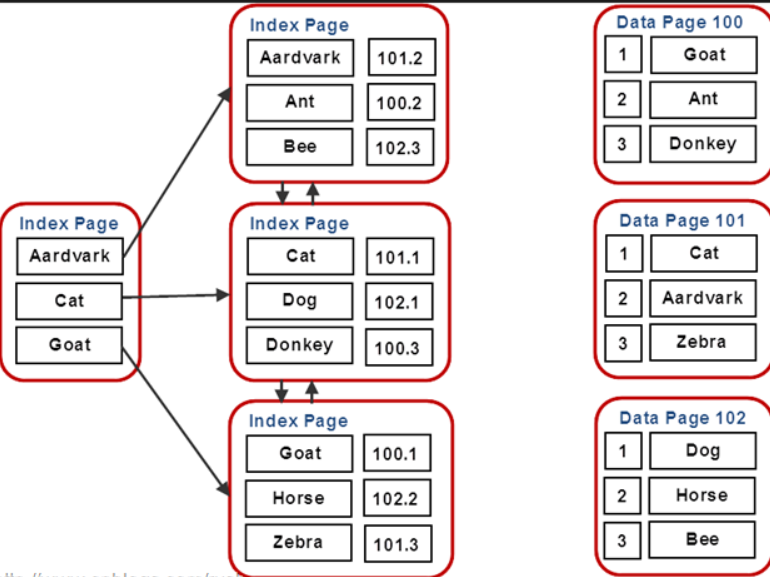 通过上图,我们发现非聚集索引通过双向链表连接,而且叶节点包含指向具体数据行的指针。 如果我们要查找animal = ‘Dog’的信息,首先我们遍历第一层索引,然后数据库判断Dog属于Cat范围的索引,接着遍历第二层索引,然后找到Dog索引获取其中的保存的指针信息,根据指针信息获取相应数据页中的数据,接下来我们将通过具体的例子说明。 现在我们创建表employees,然后给该表添加**堆表非聚集索引**,具体SQL代码如下: ```sql USE tempdb ---- Creates a sample table. CREATE TABLE employees ( employee_id NUMERIC NOT NULL, first_name VARCHAR(1000) NOT NULL, last_name VARCHAR(900) NOT NULL, date_of_birth DATETIME , phone_number VARCHAR(1000) NOT NULL, junk CHAR(1000) , CONSTRAINT employees_pk PRIMARY KEY NONCLUSTERED (employee_id) ); GO ``` 现在我们查找employee_id = 29976的员工信息。 ```sql SELECT * FROM employees WHERE employee_id = 29976 ``` 查询计划如下图所示: 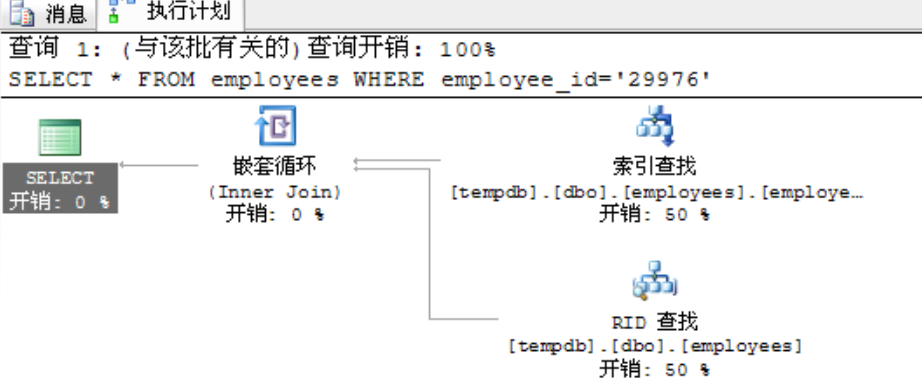 首先,查找索引值employee_id = ‘29976’的索引,然后根据RID查找符合条件的数据行;所以说,堆表索引的查询效率不如聚集表,接下来我们将介绍聚集表的非聚集索引。 ### 5.4、聚集表非聚集索引 当表上存在聚集索引时,任何非聚集索引的叶节点不再是包含指针值,而是包含聚集索引的索引值。 以前面的T_Pet表为例,假设T_Pet使用animal列作为非聚集索引,那么它的索引表非聚集索引结构如下图所示: 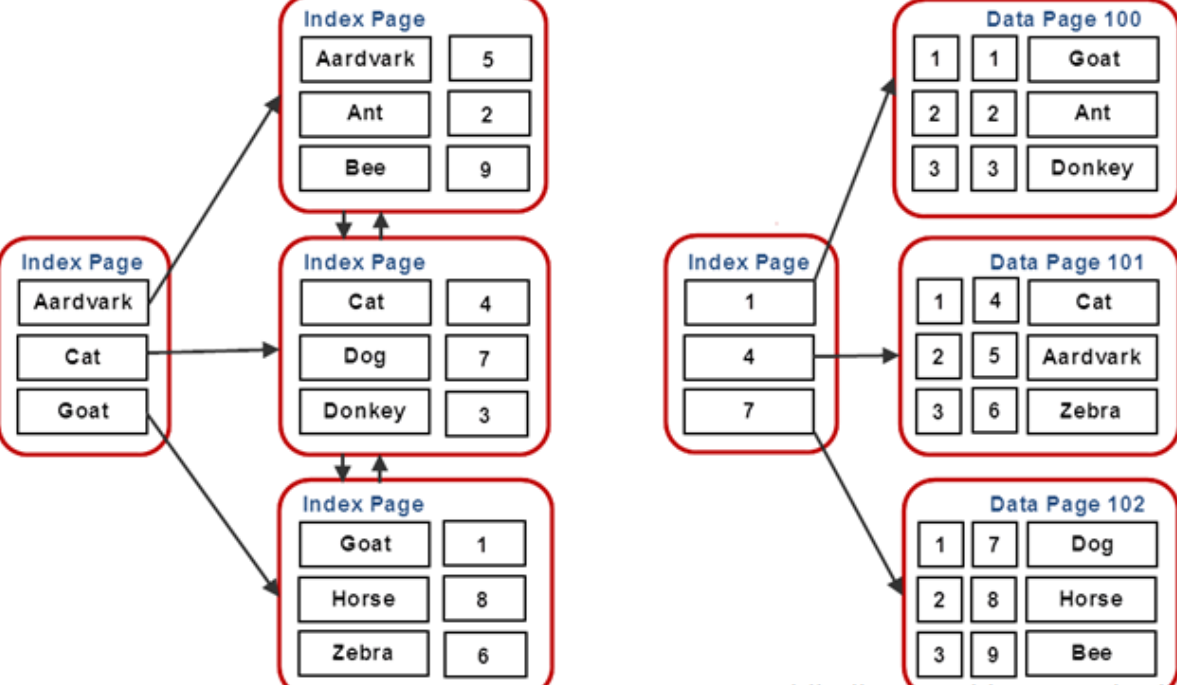 通过上图,我们发现非聚集索引通过双向链表连接,而且叶节点包含索引表的索引值。 如果我们要查找animal = ‘Dog’的信息,首先我们遍历第一层索引,然后数据库判断Dog属于Cat范围的索引,接着遍历第二层索引,然后找到Dog索引获取其中的保存的索引值,然后根据索引值获取相应数据页中的数据。 接下来我们修改之前的employees表,首先我们删除之前的堆表非聚集索引,然后增加索引表的非聚集索引,具体SQL代码如下: ```sql ALTER TABLE employees DROP CONSTRAINT employees_pk ALTER TABLE employees ADD CONSTRAINT employees_pk PRIMARY KEY CLUSTERED (employee_id) GO SELECT * FROM employees WHERE employee_id=29976 ``` 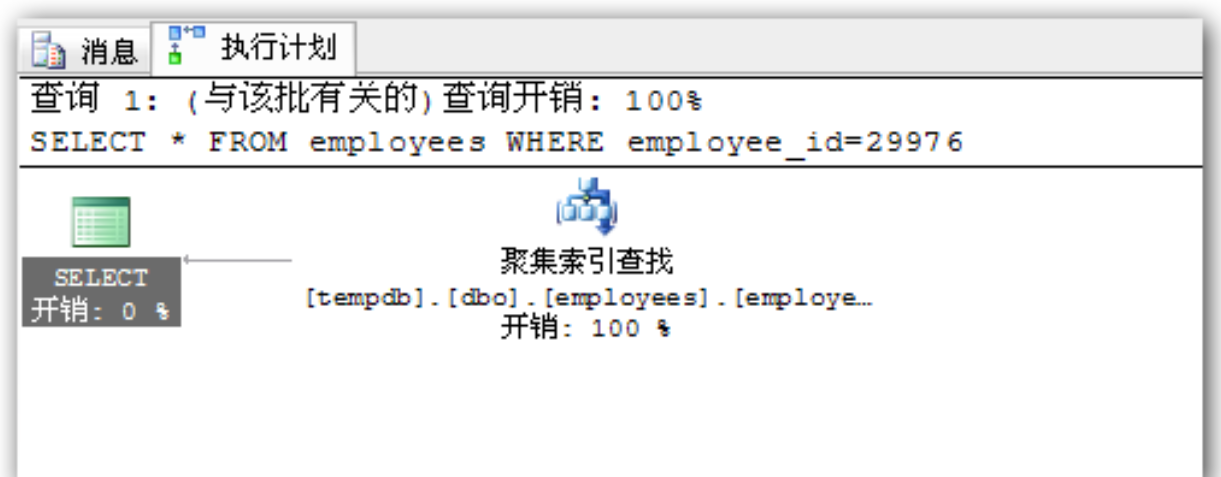 ## 6、索引的有效性 SQL Server每执行一个查询,首先要检查该查询是否存在执行计划,如果没有,则要生成一个执行计划,那么什么是执行计划呢?简单来说,它能帮助SQL Server制定一个最优的查询计划。 下面我们将通过具体的例子说明SQL Server中索引的使用,首先我们定义一个表testIndex,它包含三个字段testIndex,bitValue和filler,具体的SQL代码如下: ```sql ----------------------------------------------------------- ---- Index Usefulness sample ----------------------------------------------------------- CREATE TABLE testIndex ( testIndex int identity(1,1) constraint PKtestIndex primary key, bitValue bit, filler char(2000) not null default (replicate('A',2000)) ) CREATE INDEX XtestIndex_bitValue on testIndex(bitValue) GO INSERT INTO testIndex(bitValue) VALUES (0) GO 20000 --runs current batch 20000 times. INSERT INTO testIndex(bitValue) VALUES (1) GO 10 --puts 10 rows into table with value 1 ``` 接着我们查询表中bitValue = 0的数据行,而且表中bitValue = 0的数据有2000行。 ```sql SELECT * FROM testIndex WHERE bitValue = 0 ``` 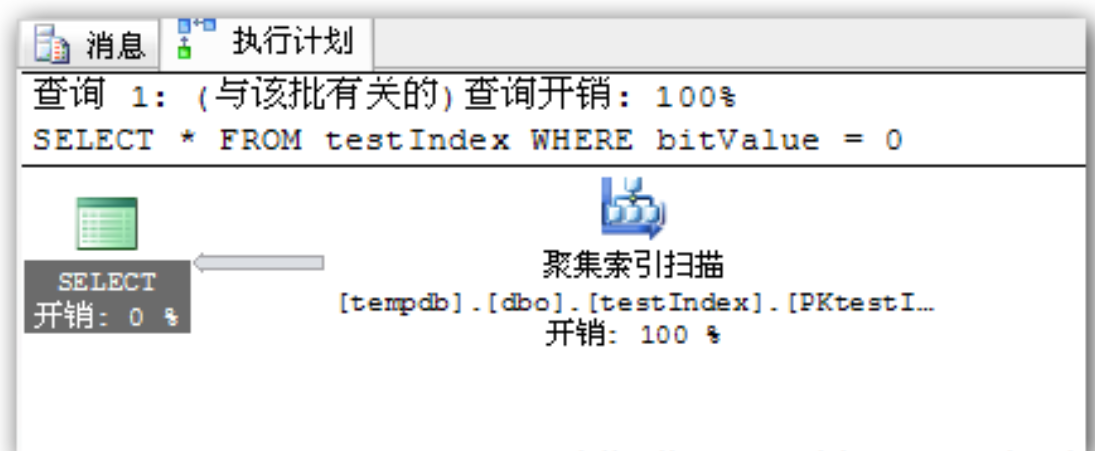 现在我们查询bitValue = 1的数据行。 ```sql SELECT * FROM testIndex WHERE bitValue = 1 ``` 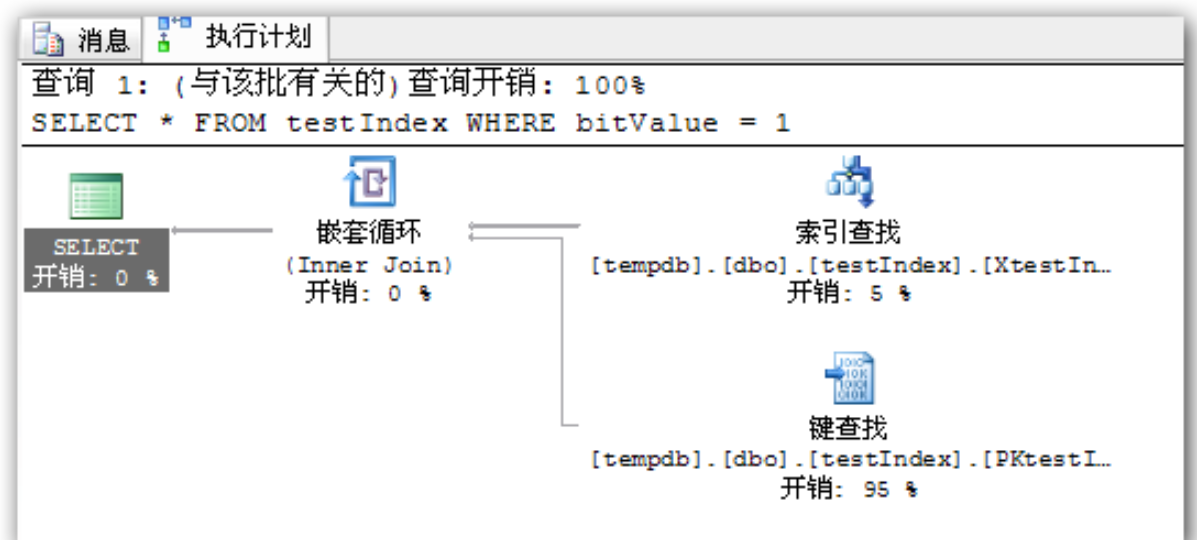 现在我们注意到对同一个表不同数据查询,居然执行截然不同的查询计划,这究竟是什么原因导致的呢? 我们可以通过使用DBCC SHOW_STATISTICS查看到表中索引的详细使用情况,具体SQL代码如下: ```sql UPDATE STATISTICS dbo.testIndex DBCC SHOW_STATISTICS('dbo.testIndex', 'XtestIndex_bitValue') WITH HISTOGRAM ```  通过上面的直方图,我们知道SQL Server估计bitValue = 0数据行行有约19989行,而bitValue = 1估计约21;SQL Server优化器根据数据量估算值,采取不同的执行计划,从而到达最优的查询性能,由于bitValue = 0数据量大,SQL Server只能提供扫描聚集索引获取相应数据行,而bitValue = 1实际数据行只有10行,SQL Server首先通过键查找bitValue = 1的数据行,然后嵌套循环联接到聚集索引获得余下数据行。 ## 7、索引的优缺点 **优点** 第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。 第二,可以大大加快 数据的检索速度,这也是创建索引的最主要的原因。 第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。 第四,在使用分组和排序 子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。 第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。 **缺点** 第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。 第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。 第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。 ## 8、索引创建原则 1.定义主键的数据列一定要建立索引。 2.定义有外键的数据列一定要建立索引。 3.对于经常查询的数据列最好建立索引。 4.对于需要在指定范围内的快速或频繁查询的数据列; 5.经常用在WHERE子句中的数据列。 6.经常出现在关键字order by、group by、distinct后面的字段。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。 7.对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。 8.对于定义为text、image和bit的数据类型的列不要建立索引。 9.对于经常存取的列不要建立索引 10.限制表上的索引数目。对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作。 11.对复合索引,按照字段在查询条件中出现的频度建立索引。在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用,因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。 ## 9、参考文章 [索引 - SQL Server | Microsoft Learn](https://learn.microsoft.com/zh-cn/sql/relational-databases/indexes/indexes?view=sql-server-ver16) [聚集与非聚集索引 - SQL Server | Microsoft Learn](https://learn.microsoft.com/zh-cn/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described?view=sql-server-ver16) [《ORACLE PL/SQL编程详解》全原创(共八篇)--系列文章导航](http://www.guosisoft.com/article/detail/164) [8 种主流数据迁移工具技术选型](http://www.guosisoft.com/article/detail/400334373904453) [SQLServer中的CTE(Common Table Expression)通用表表达式使用详解](http://www.guosisoft.com/article/detail/269) [[推荐推荐]ORACLE SQL:经典查询练手系列文章收尾(目录篇)](http://www.guosisoft.com/article/detail/165) [国思RDIF低代码快速开发平台(支持vue2、vue3)](http://www.guosisoft.com/article/detail/557095625134149) ----- 一路走来数个年头,感谢RDIF框架的支持者与使用者,大家可以通过下面的地址了解详情。 官方网站:[http://www.guosisoft.com/](http://www.guosisoft.com/) [http://www.rdiframework.net/](http://www.rdiframework.net/) 特别说明,框架相关的技术文章请以官方网站为准,欢迎大家收藏! RDIF.vNext低代码快速开发框架由海南国思软件科技有限公司专业团队长期打造、一直在更新、一直在升级,请放心使用! 欢迎关注RDIF.vNext低代码快速开发框架官方公众微信(微信号:guosisoft),及时了解最新动态。 使用微信扫描二维码立即关注 
正文到此结束
本文标签:
数据库
挨踢业界
版权声明:
本站原创文章,由
guosisoft.com
发布,遵循
CC 4.0 by-sa
版权协议,转载请附上原文出处链接和本声明。
上一篇
一文带你理清同源和跨域
下一篇
【干货】Vue3 组件通信方式详解
热门推荐
{{article.title}}
热门指数:
浏览({{article.lookCount + 5000}})
相关文章
{{article.title}}
该篇文章的评论功能暂时被站长关闭
说给你听
本文目录
文章标签
RDIF.NET
其他
微信开发
.NET
消息交互
.NetCore
项目管理
常用工具
工作流
Web前端
数据库
挨踢业界
随机文章
.NET快速信息化系统开发框架 V3.2->Web版本新增“文件管理中心”集上传、下载、文件共享等一身,非常实用的功能
微信公众号开发C#系列-6、消息管理-普通消息接受处理
.NET快速信息化系统开发框架 V3.2 新增解压缩工具类ZipHelper
RDIFramework.NET开发框架在线表单设计整合工作流程的使用
经典的52条产品交互设计原则
[推荐]ORACLE SQL:经典查询练手第一篇(不懂装懂,永世饭桶!)
如何快速开发软件?这篇文章说明白了
RDIFramework.NET ━ .NET敏捷开发框架V3.5版本全新发布 100%源码授权
RDIFramework.NET Web 敏捷开发框架 V6.3 发布 (.NET8+、Framework 双引擎)
RDIFramework.NET ━ .NET快速信息化系统开发框架 V3.2版本 正式发布
RDIFramework.NET CS敏捷开发框架 V6.2版本发布(.NET6+、Framework双引擎、全网唯一)
微软良心之作——Visual Studio Code 开源免费跨平台代码编辑器
Win10年度更新开发必备:VS2015 Update 3正式版下载汇总
RDIFramework.NET 快速开发框架 WebEasyUI版本 V6.0发布
.NET快速信息化系统开发框架 V3.2->新增记录SQL执行过程
RDIFramework.NET Web版报表管理-助力企业高效智能图表
信息系统项目管理系列之一:绪论
几款效率神器助你走上人生巅峰之园友推荐[收藏]
团队项目开发"编码规范"之七:控件命名规则
信息系统项目管理系列之九:项目质量管理
网站信息
文章总数:599 篇
标签总数:8 个
分类总数:8 个
留言数量:1385 条
在线人数:
89
人
运行天数:1321天
最后更新:2023-05-18
QQ:406590790
13005007127








